


























Introduction
In this blog, we will discuss how to find the Longest Substring with At Least K Repeating Characters. It’s a significant problem to check your understanding of hashing and strings. Such questions are frequently asked in interviews and is a fundamental problem.
Before solving the problem, it’s recommended to understand hashmaps, strings, the sliding window, and the divide and conquer technique. This blog will dive deep into each detail to get a firm hold over the application of strings and hashing in problems.
Let’s look at the problem statement.
You are given a string s, containing only lowercase characters and an integer k. The task is to find the maximum length of a substring of s, such that every unique character in the substring has a frequency greater than or equal to k.
Let’s understand the problem using an example.
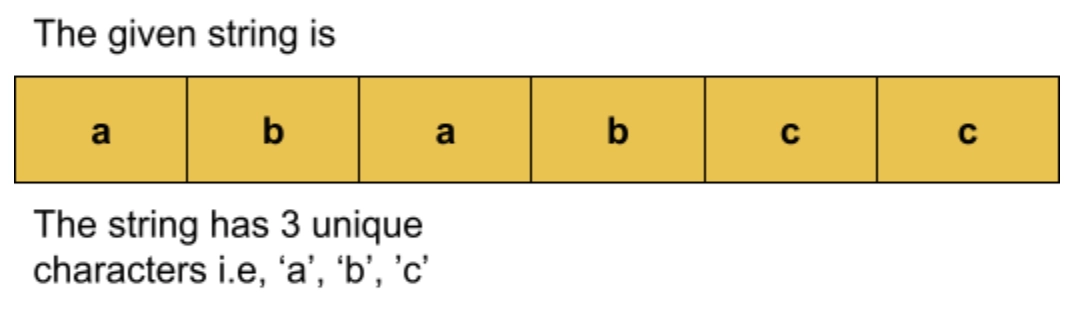
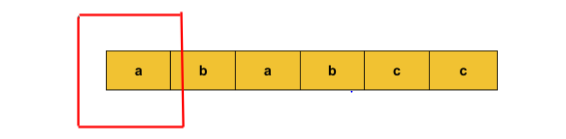
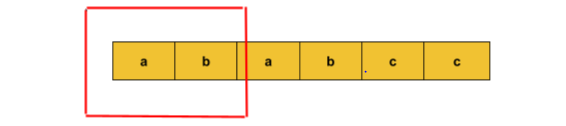
Input: string s = “ababcc”, k =2
Output: 6
Explanation: Since the unique characters have a count greater than or equal to k.
Recommended topic, kth largest element in an array, and Euclid GCD Algorithm
Naive Approach
First, let’s look at the naive approach that would probably strike anybody’s mind before jumping to an optimal approach.
So, the basic approach is to find all the substrings, count the frequency of unique characters in the substrings, and maximize the length of such substrings where the frequency of each unique character is greater than k.
So the naive/basic approach could be formulated as:
- Compute all substrings of the given substring.
- Count the frequency of every unique character in each substring.
- If the condition is satisfied in the substring, then maximize the answer.
Now let’s look at the PseudoCode.
PseudoCode
Algorithm
___________________________________________________________________
procedure longestSubstring(s, k):
___________________________________________________________________
1. ans ← 0
2. for each substring in substrings(s) do
3. if hasKFrequencyCharacters(substring, k) do # check the condition
4. ans ← max(ans, substring.size())
5. end if
6. return ans
7. end procedure
___________________________________________________________________
Implementation in C++
//C++ program to solve the problem Longest Substring with At Least K Repeating //Characters
#include <bits/stdc++.h>
using namespace std;
int longestSubstring(string &s, int k){
int ans = 0; // length of the subtring to return
if(s.size() < k) return ans; // edge case if the size of the string is less than k
// iterate over all subtrings from given index
for(int l = 0; l<s.size(); ++l){
vector<int> countMap(26, 0); // maintain a map to store count of each character
for(int r = l; r<s.size(); ++r){ // go through all possible length substrings from l
countMap[s[r]-'a']++; // increment the count of this character
bool hasKFrequencyCharacters = 1; // flag to check if the count of each character >= k
for(int i=0;i<26;++i){
if(countMap[i]>0 and countMap[i]<k){ // check if condition is violated
hasKFrequencyCharacters = 0;
}
}
//if condition satisfies maximise the answer
if(hasKFrequencyCharacters){
ans = max(ans, r-l+1);
}
}
}
// return the ans
return ans;
}
int main() {
// string s
string s = "ababcc";
// k
int k = 2;
//find the answer
cout<<"The longest substring having atleast k frequency of each unique character is: "<<longestSubstring(s, k);
return 0;
}
Output
The longest substring having atleast k frequency of each unique character is: 6Complexity Analysis
Time Complexity: O(|s|2)
This is because we iterate through all the subtsrings of s
Space complexity: O(1) at the worst case as we use constant memory to store the characters of the string s1 and s2.
The above algorithm works in quadratic time, which is good but not an efficient algorithm. This gives us the motivation to improve our algorithm.
So let’s think about an efficient approach to solve the problem.
Also check out - Substr C++


 9+ registered
9+ registered 

