Do you think IIT Guwahati certified course can help you in your career?
Introduction
Do you know why Neural Network is important? It is because it helps a lot in the training process. It basically helps to predict the behavior of the model and can be able to anticipate the real working of the model. In the last few years, loss functions have gained very attention and importance in the field of deep learning.
In this article, we will explore the concept of Loss Functions in Neural Networks, understanding their significance and various types.
Loss Function
The Loss Function is very important to Neural Networks. It tells the predicted error of the network, and the calculation is referred to as the loss function. In simpler terms, the Loss serves the purpose of computing gradients, which are used to adjust the weights of the Neural Network. This mechanism of checking gradients to update weights is what enables the training of the Neural Network.
Importance of Loss Function
Following are some of the points:
Guiding Optimization: The Loss functions help the optimized algorithm manage the parameters of Neural networks when a model is trained.
Minimizing Prediction Error: The most important feature is that it helps to predict the actual value or circumstances that might occur nearest to the actual one.
Accurate Predictions: By continuously updating the model's parameters to minimize the Loss, the neural network can make more real predictions.
Learning from Data: Loss functions help the network learn from the training data and generalize to unseen examples. Here the Loss functions let the network learn from the training data and some examples.
Model Evaluation: Loss functions quantitatively measure how well the model performs on the task at hand.
Different Losses for Different Tasks: Many different types of loss functions are used for different tasks, they are regression, classification, or object detection, to get fit the specific requirements of the problem.
Types of Loss Functions
In Supervised Learning, we encounter two primary types of loss functions, which align with the two major categories of neural networks: regression and classification.
Regression neural networks aim to predict continuous output values based on input data rather than pre-defined labels. The loss functions used in this context include Mean Squared and Mean Absolute Error.
On the other hand, classification neural networks aim to classify input data into pre-set categories. The neural network generates a vector of probabilities indicating the likelihood of the input belonging to each category. The chosen category is the one with the highest probability. The loss functions typically employed here are Binary Cross-Entropy and Categorical Cross-Entropy.
Binary Cross-Entropy Loss
It is used for binary classification tasks, where there are only two classes (e.g., 0 or 1, true or false). It also measures the dissimilarity between the predicted probability distribution and the true binary labels.
The Mean Squared Error (MSE) is a measure of how well a line fits a data point in a regression problem. Calculate the average difference between the predicted squared values and the actual data. Simply put, it measures the deviation of the predicted values from the actual values and indicates how well the score represents the data.
The lesser the MSE, => Smaller the error => Better the estimator.
The Mean Squared Error is calculated as follows:
MSE = (1/n) * Σ(actual – forecast)2
Where:
Σ = a symbol that means “sum.”
n = sample size
actual = the actual data value
forecast = the predicted data value
Categorical Cross-Entropy Loss
Categorical Cross-Entropy Loss is a way to measure the difference between the predicted probabilities and the true labels in multi-class classification tasks. It helps train a model by penalizing incorrect predictions and encouraging more accurate ones. The formula involves summing the products of true label probabilities and the logarithm of predicted probabilities. The goal is to minimize the Loss and improve the model's ability to classify different categories effectively.
Where:
N = the number of classes/categories.
Yi = the true probability of class
Pi = the predicted probability of class
log is the natural logarithm.
Frequently Asked Questions
What is the purpose of a loss function in neural networks?
The loss function quantifies the difference between predicted and actual values, guiding the optimization process during training.
How does the choice of a loss function affect model performance?
The choice of a loss function impacts the model's ability to learn specific patterns and influences its ability to generalize to new data.
What is the difference between regression and classification loss functions?
Regression loss functions measure the distance between predicted and actual values, while classification loss functions compare predicted probability distributions with true labels.
Can custom loss functions be designed for specific tasks?
Yes, custom loss functions can be designed to address unique requirements and optimize specific objectives.
Conclusion
Loss functions are fundamental components of neural network training, influencing the model's performance and learning capabilities. In this article, we explored various types of loss functions, their implementation, and best practices for selecting them. Choosing the right loss function depends on the task at hand, and understanding their nuances is crucial for building effective neural network models.
So now that you know about the Loss Functions in Neural Networks, you can refer to similar articles.






























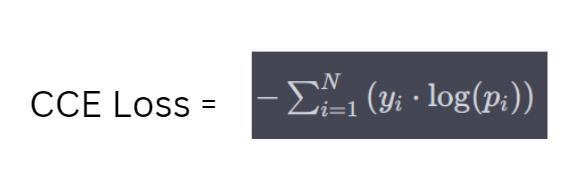


 9+ registered
9+ registered 

