Do you think IIT Guwahati certified course can help you in your career?
Introduction
A Least Recently Used (LRU) is a widely used technique to manage the memory efficiently. It arranges data in order of use, making it easy to see which ones haven't been used in the longest time. This was the drawback of earlier algorithms like FIFO and LIFO etc.
In this article, we’ll discuss the implementation of the LRU cache. Before that, you can revise your concepts of Memory management techniques in OS.
What is LRU Cache?
LRU (Least Recently Used) Cache is a data structure that stores a limited number of items, discarding the least recently used item when it reaches capacity. It provides fast access to frequently used data by maintaining items in order of their last access time.
LRU Cache Operations
LRU Cache Operations:
Get: Retrieve an item and mark it as most recently used
Put: Add a new item or update an existing one
Evict: Remove the least recently used item when cache is full
Update order: Adjust item positions based on access
LRU cache can be implemented by combining these two data structures:
A Doubly Linked Listimplementation of Queue: The most frequently used item will be at the head of the list and the least-recently-used item at the tail.
Hash set: To store the references of a key in the cache.
Algorithm to Implement LRU cache
A process is stored in memory frames. And the processes are divided into pages. Every time a process executes, its pages are brought to the LRU Cache.
If a page needed by the processor is not present in the LRU Cache, we bring that in it. We simply add a new node in the queue and change its address in the hash table to implement this. If the LRU cache(doubly linked list) is full, we must replace a page with the required one.
If the page is already present somewhere in the Cache, we have to take it to the front. Let's understand this with the help of one example.
Example
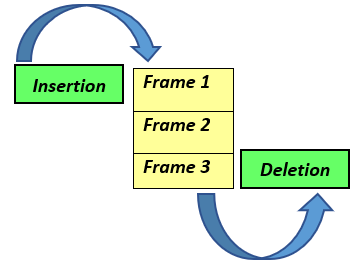
Initially, there are no pages in the memory. The cache is implemented as a queue, so, the insertion and deletion will take place as shown in the diagram below:
The processing of reference strings using the given LRU Cache is shown below.
Implementation of LRU using Double Linked List and hashing
In this approach, we are using a hash map of keys and double linked nodes. This approach is more efficient than the first one.
Java
Java
import java.util.*;
class Cache_Node { int key; int value; Cache_Node prev_node; Cache_Node next_node;
public Cache_Node(int key, int value) { this.key = key; this.value = value; } }
//A class to implement LRU Cache class LRUCache { private HashMap<Integer, Cache_Node> map; private int number_of_frames, count; private Cache_Node head, tail;
public LRUCache(int number_of_frames) { this.number_of_frames = number_of_frames; map = new HashMap<>(); head = tail = null ; count = 0; }
public void deleteNode(Cache_Node node) { Cache_Node prev = node.prev_node; Cache_Node next = node.next_node; if (prev != null) { prev.next_node = next; }
if (next != null) { next.prev_node = prev; }
}
public void addToHead(Cache_Node node) { if (head == null) { head = tail = node; return; } node.next_node = head ; if (head != null) { head.prev_node = node; } head = node;
}
public int get(int key) { if (map.get(key) != null) { Cache_Node node = map.get(key); int result = node.value; deleteNode(node); addToHead(node); return result; }
public class LRU_Test { public static void main(String[] args) { //Creates a cache with three frames LRUCache cache = new LRUCache(3);
cache.set(1, 10); cache.set(2, 20); cache.set(3, 30); System.out.println("Current sequence in cache"); System.out.println(" -------"); cache.printCache(); System.out.println(" -------"); System.out.println("Value for the key: 2 is " + cache.get(2)); cache.set(4, 40); System.out.println("Current sequence in cache"); System.out.println(" -------"); cache.printCache(); System.out.println(" -------"); System.out.println("Value for the key: 1 is " + cache.get(1)); System.out.println("Value for the key: 3 is " + cache.get(3)); System.out.println("Value for the key: 4 is " + cache.get(4));
Current sequence in cache
-------
| 3: 30 |
| 2: 20 |
| 1: 10 |
-------
Value for the key: 2 is 20
Current sequence in cache
-------
| 4: 40 |
| 2: 20 |
| 3: 30 |
-------
Value for the key: 1 is -1
Value for the key: 3 is 30
Value for the key: 4 is 40
Current sequence in cache
-------
| 4: 40 |
| 3: 30 |
| 2: 20 |
-------
Time Complexity
The hash map makes the time of the get operation to be O(1). The list of double linked nodes makes the nodes adding/removal operations O(1).
Space Complexity
The space complexity of this approach is O(N), where N is the total number of nodes in the cache.
Now, let’s move on to the frequently asked questions on this topic.
Efficient Memory Management LRU ensures frequently accessed data stays in memory, leading to more efficient memory utilization by evicting the least recently used items.
Improved Cache Hit Ratio Since it prioritizes recently accessed data, LRU often leads to a higher cache hit ratio compared to simpler strategies like FIFO.
Good for Temporal Locality LRU is highly effective in scenarios where recent items are likely to be accessed again soon, leveraging temporal locality patterns in data access.
Widely Used in Practice LRU is easy to implement and widely used in various systems like web browsers, databases, and operating systems for efficient cache management.
Disadvantages of LRU Cache
High Overhead in Maintaining Order Maintaining the access order of items in the cache requires additional data structures like linked lists, increasing implementation complexity and overhead.
Expensive in Large Systems LRU’s operations can be costly in systems with large cache sizes, as it requires keeping track of the usage order for every item.
Not Always Optimal In workloads with unpredictable access patterns, LRU may not perform well and can lead to suboptimal eviction choices compared to other algorithms.
Memory Usage Additional memory is needed to store metadata (like timestamps or access order), which can be significant in systems with limited resources.
Real-World Applications of LRU Cache
Web Browsers Browsers use LRU to store recently accessed webpages or images in cache, so frequently visited sites load faster without fetching from the network.
Database Systems LRU is applied to manage database buffers, keeping frequently accessed data in memory to reduce disk access times and enhance query performance.
Operating Systems OS memory management utilizes LRU for paging and virtual memory systems, evicting the least recently used pages when memory is low.
Content Delivery Networks (CDNs) CDNs use LRU to cache popular content closer to users. Less frequently accessed content is removed, making room for the most current or popular data.
Frequently Asked Questions
What is the best data structure to implement LRU cache?
The best data structure to implement an LRU cache is a combination of a HashMap (or dictionary) and a doubly linked list. The HashMap provides constant-time lookups, while the doubly linked list efficiently tracks the order of usage, supporting quick insertions and deletions.
What is the stack implementation of LRU?
In the stack implementation of LRU, a stack is used to track cache items by usage. When an item is accessed, it is moved to the top of the stack. When the cache exceeds its capacity, the least recently used item at the bottom is removed.
What is the difference between LRU and MRU cache?
LRU (Least Recently Used) evicts the least recently accessed items, assuming they are least likely to be used again. MRU (Most Recently Used) evicts the most recently accessed items, assuming they are most likely to be used soon. LRU works well for temporal locality, while MRU suits specific cases like bursty access patterns.
What is the LRU algorithm for Cache?
This caching method keeps items that have been recently used near the top of the Cache. The LRU inserts a new item to the top of the Cache whenever it is accessed. When the cache limit is reached, things that have been accessed less recently are deleted from the Cache beginning at the bottom.
Conclusion
In this article, we’ve learned about the implementation of LRU Cache. LRU cache is an essential technique for efficient memory management, especially in systems that frequently access data. By ensuring that the least recently used items are evicted first, LRU effectively optimizes cache hit ratios and memory utilization. Its implementation, often using a combination of a HashMap and a doubly linked list, offers fast access and eviction operations.



































 9+ registered
9+ registered 

