Do you think IIT Guwahati certified course can help you in your career?
Introduction:
Manacher's Algorithm is an algorithm that is used for finding all the substrings of a given String that are palindromes in the linear order(i.e. o(n)) complexity.
Palindromes are specific types of strings which, if traversed from backwards or forward, appear the same.
E.g.:-
1-> abcdcba
2-> aba
Statement:
Given String s with length n. Track down every one of the sets (i,j) with the end goal that substring s[i… j] is a palindrome. String 't' is a palindrome when t=t(rev) (t(rev) is a reverse string for t).
Elaboration on Statement:
Obviously, in the most pessimistic scenario, we can have O(n^2) palindrome strings, and at the primary look, it appears to be that there is no straight calculation for this issue.
In any case, the data about the palindromes can be kept in a more conservative manner: for each position i=0… n−1, we'll discover the qualities d1[i] and d2[i], signifying the number of palindromes likewise with odd and even lengths with focuses in the position I.
For example, string s=abababc has three palindromes with odd length with focuses in the positions s[3]=b, I. e. d1[3]=3:
What's more, string s=cbaabd has two palindromes with even length with focuses in the positions s[3]=a, I. e. d2[3]=2:
So the thought is that on the off chance that we have a sub-palindrome with length l with a focus in some position I, we likewise have sub-palindromes with lengths l−2, l−4 and so on with priorities in I. So these two clusters d1[i] and d2[i] are sufficient to keep the data for pretty much every one of the sub-palindromes in the String.
It's obviously true that there is a calculation, which is sufficiently straightforward, that works out these "palindrome clusters" d1[] and d2[] indirect time. The analysis is portrayed in this article.
Solutions:
As a rule, this issue has numerous arrangements: with String Hashing, it tends to be addressed in O(n⋅log(n)), and with Suffix Trees and quick LCA, this issue can be tackled in O(n).
However, the technique portrayed here is adequately more straightforward and has less secret steady on schedule and memory intricacy. This calculation was found by Glenn K. Manacher in 1975.
Trivial Algorithm:
To stay away from ambiguities in the other depiction, we mean what "trifling calculation" is.
The calculation does the accompanying. For each middle position it attempts to expand the appropriate response by one until it's conceivable, contrasting a couple of related characters each time.
Such a calculation is slow; it can ascertain the appropriate response just in O(n^2).
The execution of the minor calculation is:
Pseudo code:
vector<int> d1(n), d2(n); for (int i = 0; i < n; i++) { d1[i] = 1; while (0 <= i - d1[i] && i + d1[i] < n && s[i - d1[i]] == s[i + d1[i]]) { d1[i]++; }
d2[i] = 0; while (0 <= i - d2[i] - 1 && i + d2[i] < n && s[i - d2[i] - 1] == s[i + d2[i]]) { d2[i]++; } }
We depict the calculation to track down every one of the sub-palindromes with odd length, I. e., to compute d1[]. The answer for every one of the sub-palindromes with even length (for example, working out the exhibit d2[]) will be a minor adjustment for this one.
For a quick estimation, we'll keep up with the boundaries (l,r) of the furthest right discovered sub-palindrome (I. e. the palindrome with maximal r). At first we set l=0,r=−1.
In this way, we need to work out d1[i] for the following i, and every one of the past qualities in d1[] has been determined. We do the following:
In case ‘I’ is outside the current sub-palindrome, i. e. i>r, we'll simply dispatch the trifling calculation. So we'll increment d1[i] sequentially and actually take a look at each time if the current furthest right substring [i−d1[i]… i+d1[i]] is a palindrome. At the point when we track down the primary crisscross or meet the limits of s, we'll stop. For this situation, we've at last determined d1[i]. After this, we should not neglect to refresh (l,r). r ought to be refreshed so that it addresses the last record of the current furthest right sub-palindrome.
Presently consider the situation when i≤r. We'll attempt to remove some data from the all-around determined qualities in d1[]. Thus, how about we find the "reflect" position of i in the sub-palindrome (l,r), for example, we'll get the position j=l+(r−i), and we really take a look at the worth of d1[j]. Since j is the position balanced to i, we'll quite often relegate d1[i]=d1[j]. Outline of this (palindrome around j is really "duplicated" into the palindrome around I):
At the principal level, clearly this calculation has direct time intricacy since we frequently run the gullible analysis while scanning the response for a specific position.
Nonetheless, a more cautious investigation shows that the calculation is straight. Truth be told, Z-work building calculation, which seems to be like this calculation, likewise works in linear time.
We can see that each emphasis of trifling calculation expands r by one. Additionally, r can't be diminished during the calculation. Along these lines, the little analysis will make O(n) emphasis altogether.
Additionally, different pieces of Manacher's calculation work clearly indirect time. In this manner, we get O(n) time intricacy.
Steps for the Implementation of Manacher’s Algorithm:
For ascertaining d1[], we get the accompanying code. Things to note:
i is the file of the middle letter of the current palindrome.
d1[] stores the odd palindromes. In this way, on the off chance that r, k is introduced to 1, as a solitary letter is a palindrome in itself. For d2[], k will be initialised to 0.
On the off chance that I don’t surpass r, k is either instated to the d1[j], where j is the mirror position of I in (l,r), or k is limited to the size of the "external" palindrome.
The while circle signifies the insignificant calculation. We dispatch it regardless of the worth of k.
On the off chance that the size of the palindrome focused at I is x, d1[i] stores (x+1)/2.
Pseudo code:
vector<int> d1(n); for (int i = 0, l = 0, r = -1; i < n; i++) { int k = (i > r) ? 1 : min(d1[l + r - i], r - i + 1); while (0 <= i - k && i + k < n && s[i - k] == s[i + k]) { k++; } d1[i] = k--; if (i + k > r) { l = i - k; r = i + k; } }
For computing d2[], the code seems to be comparative, however with minor changes in arithmetical articulations. Things to note:
Since an even palindrome will have two focuses, I is the last of the two community files.
in the event that ‘i’ surpasses r, k is instated to 0, as a solitary single letter is certifiably not an even palindrome.
On the off chance that the size of palindrome focused at I is x, d2[i] stores x/2.
Pseudo code:
vector<int> d2(n); for (int i = 0, l = 0, r = -1; i < n; i++) { int k = (i > r) ? 0 : min(d2[l + r - i + 1], r - i + 1); while (0 <= i - k - 1&& i + k < n && s[i - k - 1] == s[i + k]) { k++; } d2[i] = k--; if (i + k > r) { l = i - k - 1; r = i + k ; } }
What is a palindrome String? ->Strings that read exactly the same if read from forward or backward.
What is Manacher’s Algorithm? ->It is an algorithm to find out all the palindrome substrings of a given String.
What is the Time Complexity of Manacher's Algorithm? ->O(n)
What is a trivial algorithm? ->it is an algorithm to find out all the palindrome substrings of a given String.
What is the Time Complexity of a trivial Algorithm? ->O(n^2)
Key Takeaways :
In this blog, we discussed how to implement the manacher’s algorithm and how to use it to find the substrings that are palindrome for a given string and how to implement the trivial algorithm, we also discussed the time complexity regarding this algorithm and implementation.



























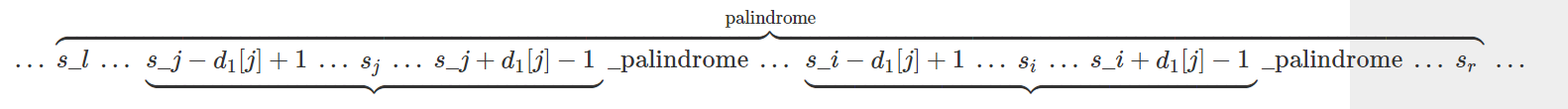


 9+ registered
9+ registered 

