Do you think IIT Guwahati certified course can help you in your career?
Introduction
When working with data, the structure we choose may make a huge difference. There are two primary approaches: Map style dataset and Iterable style dataset. These methods help us in organising the collected data. The Map style makes use of keys for quick access, but the Iterable style organises data in a flexible way, allowing for easy and efficient data processing through iteration.
In this, we'll look at both approaches and their advantages and disadvantages. We'll explore how they affect memory, performance, and usability. You'll know which style is perfect for your project at the en
Map Style Dataset
A Map style dataset organises data using a key-value structure, making it easy to retrieve specific information quickly based on unique keys.
A Map style dataset is a method of organising and storing data in a structured manner. In this approach, data is stored as key-value pairs. Each key serves as a unique identifier, like a label, and is associated with a corresponding value. Think of it as a dictionary where words (keys) have their meanings (values). This arrangement enables rapid and direct retrieval of information using the keys.
For instance, if you had a collection of student records stored in a map style dataset, each student's name could be a key, and their associated grades could be the corresponding values. When you want to access a particular student's grades, you simply provide their name (the key), and you can quickly retrieve the related data (the value).
This approach is efficient when you need to quickly access specific pieces of information without having to search through the entire dataset. It's like having an index for a book – you can jump to the relevant section without reading the entire book. The key-value structure of a Map style dataset simplifies data retrieval and is particularly useful for scenarios where quick and precise access to data is a priority.
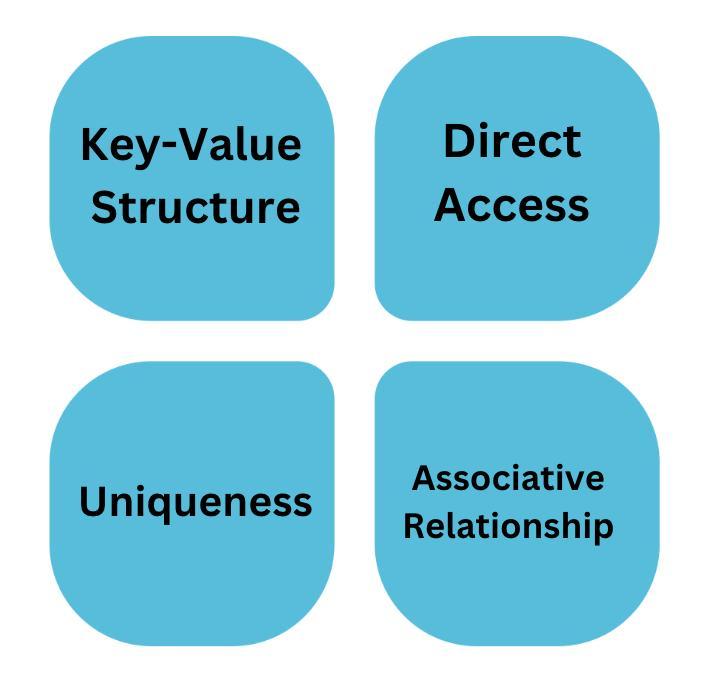
Characteristics of Map Style Dataset
Let’s discuss the characteristics of Map Style Dataset
1. Key-Value Structure
Data in a Map style dataset is stored as pairs of keys and their corresponding values. This relationship allows for efficient data retrieval based on unique keys.
Imagine you have a collection of special boxes where you want to keep your toys. Each box has a label (key) and holds a toy (value). This is similar to how a Map style dataset works!
2. Direct Access
With the help of keys, you can directly access specific data elements without needing to search through the entire dataset. This speeds up data retrieval, making it well-suited for scenarios requiring quick access to specific information. It is like like having a superpower to quickly find specific things without searching for hours.
Imagine you have a special box for each of your toys, and each box has a label. When you want a particular toy, you don't need to open every box to find it. Instead, you just look at the label and go straight to the right box. That's direct access.
3. Uniqueness
Each key is unique within the dataset, preventing duplication and ensuring data integrity.
Imagine: You have a collection of your favourite toys, and you want to give each toy a name. Each toy's name is special and unique, just like how your name is unique to you.
4. Associative Relationship
The key-value structure allows you to associate related information. For instance, you can link a person's name (key) with their contact details (value).
Imagine you have a bunch of cute socks, and you want to keep them organised with their matching shoes. You make sure that each sock has its own matching shoe, and they go together like best friends.
Iterable Style Dataset
It is the processing of large amounts of data without loading everything into memory all at once. It's like going through a collection step by step, only looking at what you need when you need it. It is basically a way to organise and work with data that focuses on easy and flexible processing. It's like having a conveyor belt of information that you can access one piece at a time. This approach allows you to go through the data step by step, processing each part as you need it.
Imagine you have a big box of different toys, and you want to play with them one by one without taking all of them out at once. This is similar to how an Iterable style dataset works. Instead of taking out all the toys together, you pick one toy, play with it, and then move on to the next one. It's like a conveyor belt of toys, and you control when you want to play with each toy. This way, you don't get overwhelmed with all the toys at once, and you can enjoy them one by one.
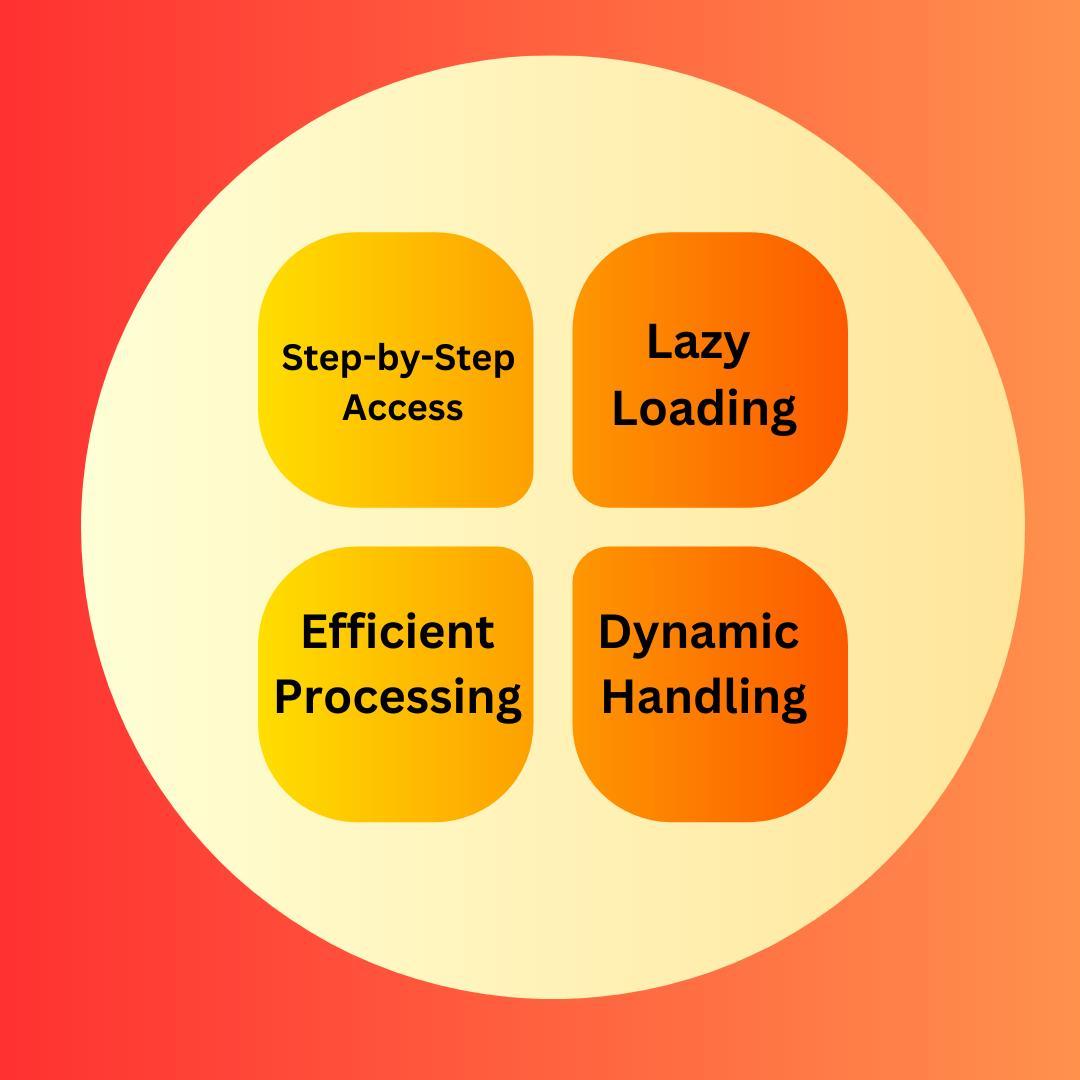
Characteristics of Iterable Style Dataset
An Iterable style dataset offers unique characteristics and benefits that make it a valuable approach for handling and managing data.
1. Step-by-Step Access
Step-by-step access is like reading a storybook one page at a time instead of trying to read the whole book in one go. Let's break it down in a simple way!Imagine you have a storybook with many pages, and you want to enjoy each part slowly. With step-by-step access, you read one page, enjoy the story on that page, and then turn to the next page.
Think of it as taking a journey and discovering new things as you go. You're not trying to reach the end in a hurry – you enjoy each step. In Iterable style datasets, you process data piece by piece, just like reading a story page by page.
2. Lazy Loading
Lazy loading is like having a magical assistant who only brings things to you when you need them, saving space and making things run smoothly. Let's dive into this concept in a simple way.
Imagine you have a treasure chest full of toys, and you don't want to carry them all at once. Instead, you call your magical assistant when you want a toy, and they bring it to you. This way, you're not tired from carrying everything around all the time.
Think of it as having a special button that magically gets you whatever you need, whenever you need it. Lazy loading in Iterable style datasets helps keep things organised and running smoothly, just like having your toys brought to you one by one.
3. Efficient Processing
Efficient processing is like doing tasks step by step, focusing on one thing at a time, which makes things faster and easier. Let's explore this concept in a simple way.
Imagine you have a big box of colourful blocks, and you want to build different shapes. Instead of trying to build everything at once, you pick one block, place it in the right spot, and then move on to the next block.
Think of it as cooking a delicious meal. You chop vegetables, then you cook them, and finally, you put everything together. This step-by-step approach ensures that each part is done perfectly. Efficient processing in Iterable style datasets is like that – you handle each part of the data one by one, making sure everything is done right.
4. Dynamic Handling
Dynamic handling is like having a toolbox that changes its tools based on what you're building. Let's understand this concept in a simple way.
Imagine you're building different things with your blocks, and you need different tools for each project. Instead of carrying all the tools at once, your toolbox magically gives you the right tool when you need it.
Think of it as having a magical backpack that gives you the exact tool you need, exactly when you need it. Dynamic handling in Iterable style datasets helps you process data differently based on what you're aiming to achieve.
Operations
Let’s discuss the operations for Map Style and Iterable Style Dataset.
Map Style Dataset Operations
add(key, value): Adds a new item to the dataset based on the given key-value pair.
get(key): Gets and returns the value associated with the given key.
remove(key): Removes the item from the dataset that corresponds to the specified key.
contains(key): Returns a boolean value if the dataset contains an item with the given key.
update(key, newValue): Sets the value of an existing item to the new value using the specified key.
count(): This function returns the total number of items in the dataset.
keys(): Returns a collection of all the dataset's keys (labels).
values(): This function returns a list of all the values in the dataset.
isEmpty(): Determines whether or not the dataset is empty and returns a boolean value.
clear(): Clears the dataset of all items, leaving it empty.
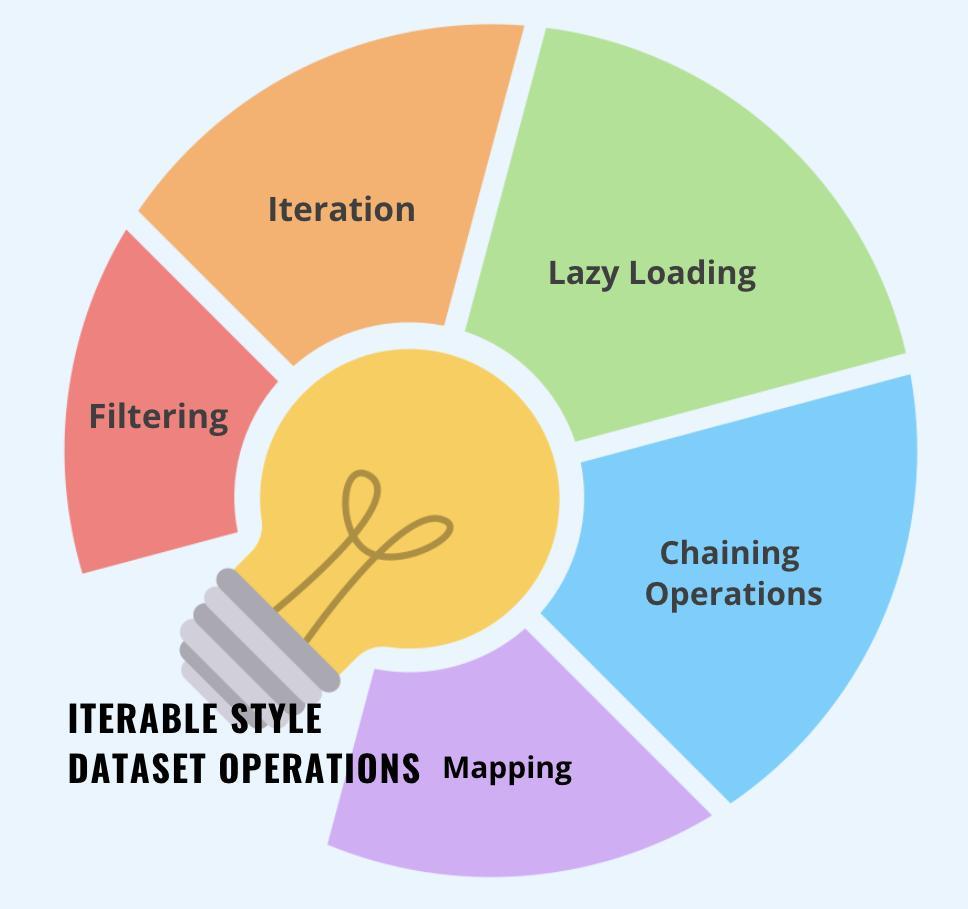
Iterable Style Dataset Operations
Let’s discuss the iterable style dataset operations.
Iteration (for item in dataset): This operation allows you to iteratively loop through each item in the dataset, processing them sequentially.
Lazy Loading: Iterable datasets load data only when necessary, saving memory and increasing efficiency.
Filtering: A filter operation can be used to pick certain things that meet specified criteria, resulting in the creation of a new iterable dataset containing the filtered objects.
Mapping: The map operation transforms each item in the dataset and returns an iterable dataset containing the modified items.
Chaining Operations: You may chain together numerous operations to conduct complicated data processing activities in a series without having to load the complete dataset into memory.
Advantages of Map Style Dataset Methods
Let’s discuss the advantages of Map Style Dataset.
1. Convenient Access
Consider having a labelled box for each of your toys. You may rapidly discover and get a certain toy by its label using methods like add and get. It's like knowing which box has your favourite toy without having to sift through everything.
2. Organised Storage
Just as storing your toys in different bins makes it easier to find them, utilising methods like add and delete ensures that each piece of data has its own spot in the dataset.
3. Quick Updates
When it's time to replace an old toy with a new one, techniques like updating make it possible to do so quickly. It's similar to removing a jigsaw piece without disrupting the rest of the picture.
4. No Confusion
You may verify if a given toy is in your collection using methods like includes. This eliminates uncertainty and allows you to know exactly what you have, such as checking to see if your favourite toy is in the toy box.
5. Simple Counting
The count technique informs you how many toys you have. It's similar to counting your fingers without having to count them individually.
6. Efficient Organisation
Methods like keys and values create well-organised lists of labels and toys. It's like keeping a detailed inventory of all your possessions.
Advantages of Iterable Style Dataset Methods
Some nice advantages that make handling data simpler and more effective are provided by dataset methods in the iterable style.
Let's examine the advantages of iterable style dataset methods in layman's terms.
1. Memory-Friendly
Visualise having a magical bag that only provides the items you require. Similar to this, iterable methods get only the data you are now using. This keeps your computer working smoothly and conserves memory.
2. Custom Processing
Iterable processes may be compared to having several ways to play with your toys. As you travel through the toys, you may decide to perform various things with each one. Similar to this, you may process data in many ways to acquire the precise results you need using techniques like filtering and mapping.
3. Quick Thinking
Iterable techniques let you analyse data incrementally, much as how you can solve puzzles more quickly by concentrating on one component at a time. Real-time analysis applications like following a moving item or responding to altering data benefit greatly from this.
4. No Waiting
It works like a sandwich maker, where you choose the ingredients from a conveyor belt. Iterative techniques begin processing immediately once the entire dataset has loaded. This enables you to complete tasks more quickly, such as assembling a sandwich while on the go.
Imagine a companion who makes game recommendations depending on your mood. Similar to iterative processes, iterative approaches adapt, enabling you to alter your data processing strategy depending on your goals.
5. Works for Any Size
Iterative approaches can handle anything, whether you have a little box of toys or a large toy shop. In a sense, they resemble technologies that can adapt to any dataset size.
Scenarios for Choosing Map Style Dataset Methods
It's like choosing the best tool for the task when selecting map-style dataset approaches. Let's examine several instances when these techniques excel in plain language!
1. Maintaining Contact with pals
Picture yourself with a list of your pals and a list of their preferred pastimes. Map-based solutions are ideal for this. Each friend's name may be the key, and their preferred activity can be the value in the add function. Using their name, you may later determine what their favourite activity is.
2. Organising Recipes
Map approaches can be helpful if you're compiling recipes. Recipe names can serve as both the key and the value for each recipe. You may add fresh recipes, edit older ones, or even get rid of ones you don't need anymore.
3. Managing To-Do Lists
Map techniques act as a task manager when you have a list of activities to do. The key is the task's name, and the value represents its specifics. When a job is finished, you may delete it and change its information.
4. Building a Dictionary
Map approaches are your language partner while learning new words in a foreign language. The word can serve as the key, and its translation can serve as the value. The get function makes it simple to locate translations.
5. Storing User Preferences
Map techniques act as your memory bank when you're developing an app and want to remember user preferences. There may be a key-value pair for each setting.
Scenarios for Choosing Iterable Style Dataset Methods
The best approach to play with your toys is to choose the iterable style dataset techniques. Let's look at some enjoyable scenarios when these techniques are quite beneficial.
1. Sorting Your Toys
Assume you have a large collection of toys and wish to play with each one individually. Comparable to sorting them by kind or colour, iterative techniques. The iteration approach may be used to go through each toy and choose one to play with first.
2. Locating Your Favourite Book
Iterative techniques might be useful if you have a shelf full of books and are trying to identify your favourite. You can browse the books and choose the one that best suits your reading preferences.
3. Exploring a Treasure Map
Assume you have a treasure map with hints buried all over it. Iterable algorithms work like a map that must be followed step by step. The iteration approach may be used to find each hint and advance toward the reward.
4. Choosing Ingredients for a Recipe
Iterative approaches are similar to putting together your sandwich in the proper sequence when you're creating a sandwich and need to add each ingredient one at a time. The iteration process may be used to add lettuce, tomatoes, and so on.
5. Solving a problem
Iterative procedures are similar to placing each piece in its proper location when attempting to solve a puzzle. The puzzle may be put together piece by piece by iterating over the parts.
Challenges for Working with Map Style Dataset
While using map-style dataset approaches is similar to putting together puzzles, occasionally, you could come across a few challenging parts. Let's talk about some straightforward problems you could encounter!
1. Duplicate Keys
Picture having two toys in your toy box with the same name. Similar issues might arise with map techniques if you unintentionally use the same label (key) for several objects. Be cautious to use different keys for every item.
2. Memory Usage
If you add too many things to a map dataset, it might eat up a lot of memory, much like your toy box can become overflowing. Large datasets might cause mistakes in your software or even cause it to run slowly.
3. Finding Particular Items
On occasion, it might be like looking for a specific toy in a large collection. When using a map dataset, it might be difficult to locate a certain object if you can't recall the exact key. In order to receive what you desire, you must recall the proper label.
4. Modifying Data Structure
Picture converting a toy vehicle into a toy plane. If you use map approaches, it might be difficult and perhaps time-consuming to modify the way your data is arranged.
5. Iteration Order
The order in which items are iterated through a map dataset may not be what you expect in some programming languages. If you depend on a set order, this can be confusing.
Challenges for Working with Iterable Style Dataset
Using iterable style dataset techniques is similar to discovering a brand-new playground, although occasionally, you could run across some challenges. Let's find out, in plain language, some typical difficulties you could have!
1. Sequential processing
Imagine wanting to play with all of your toys at once, but you can only play with one toy at a time. This is called sequential processing. Similar to iterable procedures, you could want extra strategies if you need to process several objects at once.
2. Real-time Updates
If the dataset changes, iterable methods might not be able to update things in real-time, much like you can't change a toy's colour while you're playing with it. The iteration might need to be refreshed or restarted.
3. Sequence Dependency
Occasionally, a specified sequence in which various activities must be completed. If you use iterative approaches, you may need to do more preparation if you need to complete things out of order.
4. Iteration Efficiency
Iterable methods are excellent for step-by-step activities, but they may not be as effective as other techniques for other jobs, such as quickly discovering a single item.
5. Complexity with Nested Data
Iterating over deeply nested data can become challenging and need careful navigation if your data is organised like a series of toy boxes inside of other toy boxes.
Map Style Dataset Vs Iterable Style Dataset
Aspect
Map Style Dataset
Iterable Style Dataset
Definition
A dataset that organises data using key-value pairs, where each key is unique, allowing for direct access to values using keys.
A dataset that focuses on sequential processing, allowing for step-by-step access and manipulation of data.
Purpose
Organises data with key-value pairs for easy access.
Processes and manages data sequentially, step by step.
Access Method
Access data directly by using keys to retrieve specific values associated with those keys.
Access data by iterating through the dataset, processing each item sequentially in the order they appear.
Adding Items
Uses the add method to assign values to specific keys.
Data items are added to the dataset for sequential access.
Retrieving Items
Uses the get method to retrieve values using keys.
Accessed one by one through iteration using loop structures.
Complexity of Retrieval
Fast, as accessing values by key is optimised.
Slower, as each item is accessed sequentially.
Dynamic Handling
Not very adaptable to changes in processing order, as data is primarily accessed through keys.
Highly adaptive, allowing for real-time analysis and dynamic processing as data is processed on-the-fly.
Example
Imagine a library catalogue where each book's title is a key, and its details (author, genre, etc.) are values. You can quickly retrieve book details by searching with the title (key)
Picture a list of tasks where you want to go through each task one by one. You use iteration to process each task sequentially.
Frequently Asked Questions
Which style is more memory-efficient?
For large datasets, the Iterable Style Dataset is generally more efficient. This approach prevents memory overload and maintains smoother processing compared to the Map Style Dataset, which might become less efficient as the dataset grows due to memory usage and direct access limitations.
Can I switch between styles within a project?
Depending on your needs, you may choose between a Map Style Dataset and an Iterable Style Dataset inside a project. It's comparable to having many tools in your toolbox for various jobs. Use Map Style Dataset techniques if direct access and speedy retrieval utilising keys are required.
How do the styles handle complex transformations?
Map Style Dataset
You may change certain values within items using the update function with a Map Style Dataset.
Iterable Style Dataset
Each item may be processed and modified using operations like filtering, mapping, and reducing. The processed and altered results are then used to create a new iterable dataset.
Conclusion
The Iterable style excels at sequential processing, whereas the Map style offers direct access using key-value pairs. Depending on your particular demands for data transformation, you can choose among them. Utilising the various tools in your toolbox judiciously might result in efficient and successful data management for your project. Each item in your toolbox has its advantages.
But suppose you have just started your learning process and are looking for questions from tech giants like Amazon, Microsoft, Uber, etc. For placement preparations, you must look at the problems, interview experiences, and interview bundles.































 9+ registered
9+ registered 

