Do you think IIT Guwahati certified course can help you in your career?
Introduction
MapReduce is an integral component of the Hadoop framework. It is a scalable and cost-effective program that helps developers process huge amounts of data. But have you ever wondered what MapReduce Architecture looks like ?
In this article, we will learn about MapReduce Architecture and the various phases involved with the help of an example. We will also see some of the benefits of MapReduce in Hadoop.
What is MapReduce?
MapReduce is a part of the Apache Hadoop ecosystem. It is a software framework that processes huge amounts of data across computer clusters. It does parallel processing and stores data in distributed form.
The MapReduce program involves two phases, namely: Map and Reduce. These are sometimes also referred to as Mapper and Reducer Phase. Input to each phase is given as key-value pairs. The Mapper phase splits the data into chunks and processes these chunks parallelly. The output of the mapper phase is fed as an input for the reducer phase. Reducer shuffles and reduces the data. The output of the reducer phase is the final output.
How MapReduce Works?
The entire process is divided into four steps of execution which are splitting, mapping, shuffling and reducing.
MapReduce Architecture
MapReduce Architecture is a parallel processing framework for efficiently analyzing and processing large datasets across distributed computing clusters. The entire job is divided into tasks. There are two types of tasks namely, Mapping tasks and Reducing tasks. Mapping tasks splits the input data and performs mapping while reducing tasks performs shuffling and aggregates the shuffling values and returns a single output value, thereby reducing the data.
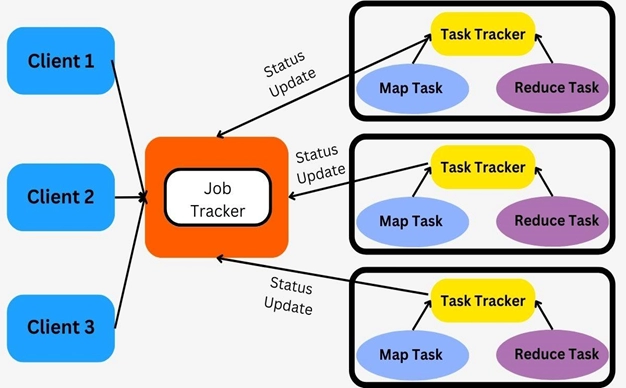
The execution of these two tasks is controlled by two entities:
Job Tracker - It acts like a master and plays the role of scheduling jobs and tracking the jobs assigned to Task Tracker.
Multiple Task Tracker - It acts like slaves. It tracks the jobs and reports the status of the jobs to the master (job tracker).
Working of Job and Task Trackers
Below points shows the working of job and task trackers.
Each job is divided into multiple tasks, which are executed on multiple data nodes in a cluster.
The Job tracker schedules the tasks to run on different data nodes.
The task tracker executes the task assigned to it by the job tracker. Task trackers are present on every data node executing a part of the job.
Task Tracker is also responsible for sending status updates to the job tracker.
Task Tracker periodically sends heartbeat signals to the Job tracker to notify it about the system's current state.
Hence, the Job tracker tracks the progress of each job with the help of task trackers. In case of task failure, the job tracker reschedules the task to a different task tracker.
Components of MapReduce Architecture
It is an essential tool for efficiently managing large datasets across multiple computers and features crucial components that collaborate to expedite data processing. The Job Tracker organizes tasks and assigns them to available computers. Task Trackers on each computer report progress and execute assigned tasks. The Map Function processes data, generating pairs of numbers that act as computer-interpretable signals. The Reduce Function subsequently combines these pairs, producing the final outcomes. MapReduce understands diverse data types through input and output formats and enables compatibility with varying data structures. The framework ensures reliability and fault tolerance by distributing data across computers and creating copies.
Phases of MapReduce
There are three main phases involved : Mapping phase, Shuffling and Sorting phase, Reducing Phase.
Consider the example where we feed the below input data to MapReduce
Welcome Ninja
Become a Coding Ninja
Ninja Coder
Mapping Phase
This is the first phase which involves splitting and mapping. The input data set is split into equal units called input splits or chunks. These input splits are then passed to a mapping function to generate output key-value pairs.
In our example, the job of the mapping phase is to count the frequency of each word from the input splits.
Shuffling and Sorting Phase
This is the second phase which takes place after the completion of the mapping phase. The two primary functions of this phase are sorting and merging. The key-value pairs received as an output from the Mapping Phase are sorted using the keys. These sorted key-value pairs are then merged in the merging step.
Shuffling helps remove duplicate values and even helps in grouping them.
Reducing Phase
The output from the shuffling phase is used as an input for the Reducing Phase. It aggregates/combines the shuffling values and gives a single output value.
The reducer processes the input by reducing the intermediate values into smaller values.
Benefits of MapReduce
Below are the benefits of mapreduce.
Faster Processing: MapReduce processes huge unstructured data in a short span of time as it has faster processing.
Scalable: MapReduce allows us to run applications on many different data nodes.
Reliable: In case of task failure, the job tracker in MapReduce reschedules the task to a different task tracker. This makes MapReduce more reliable and fault tolerant.
Parallel Processing: MapReduce does parallel processing by processing multiple job-parts of the same datasets parallelly.
Problems Solved by MapReduce
MapReduce considers the role of a data superhero expert in resolving complex challenges from processing substantial datasets. It excels in three key problem areas. It manages the overwhelming volume of data that traditional computers struggle to handle. MapReduce organizes tasks and harnesses multiple computers to expedite processing. It addresses computer failures by distributing data copies across machines. This safeguards against data loss, as another computer can seamlessly take over tasks in the event of a failure. MapReduce thrives in solving complex mathematical problems tied to data analysis. It adeptly identifies essential patterns, organizes information, and even makes predictions based on data behaviors.
Frequently Asked Questions
What are the two phases of MapReduce?
MapReduce has two phases: the Map phase, where data is divided and processed, and the Reduce phase, where the results from the Map phase are combined and summarized.
What is the difference between MapReduce and Hadoop?
MapReduce is a programming model for processing big data, while Hadoop is a framework that implements MapReduce and provides storage and resource management.
What happens inside the Mapping Phase?
Mapping Phase is the first phase which involves splitting and mapping. The input data set is split into equal units called input splits or chunks. These input splits are then passed to a mapping function to generate output key-value pairs.
What is the role of Job and Task Tracker in MapReduce?
Job Tracker acts like a master and plays the role of scheduling jobs and tracking the jobs assigned to Task Tracker while Task Tracker acts like slaves. It tracks the jobs and reports the status of the jobs to the master (job tracker).
Which is faster, Spark or MapReduce?
Spark is generally faster than MapReduce due to in-memory processing and optimized data sharing. It keeps data in memory and reduces disk I/O, and boosts performance.
Conclusion
In this article, we have discussed MapReduce and its architecture in detail. To learn more about MapReduce and its features, you can refer to the below-mentioned articles:































 9+ registered
9+ registered 

