Do you think IIT Guwahati certified course can help you in your career?
Introduction
Python MapReduce is a programming model. It enables the processing and creation of large amounts of data by separating work into discrete jobs. It also allows work to be performed in parallel across a cluster of machines. The functional programming constructs map and reduce inspired the MapReduce programming model.
This article will present the MapReduce programming model in Python. Also, explain how data flows across the model's various stages.
What is MapReduce?
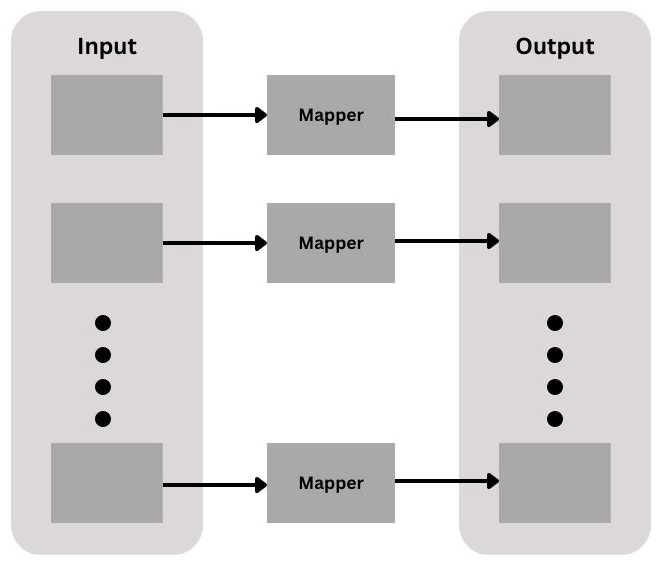
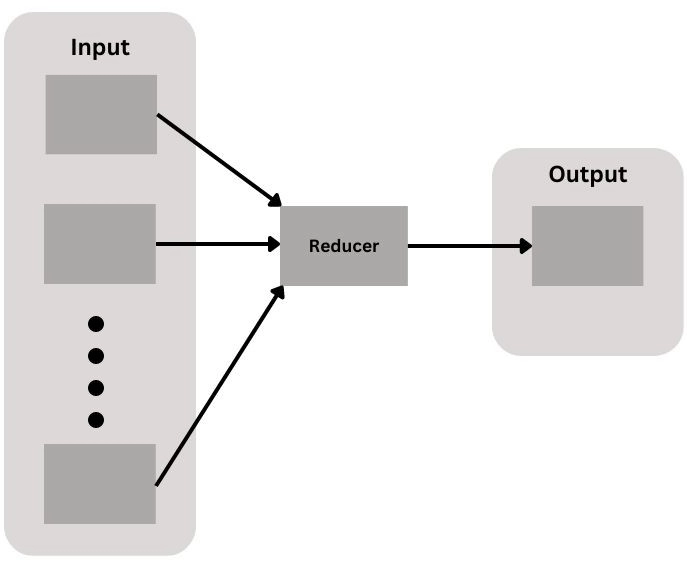
MapReduce is a method of programming that offers great scalability over a Hadoopcluster's hundreds or thousands of machines. MapReduce, as the processing component, lies at the heart of Apache Hadoop. The phrase MapReduce refers to two independent functions performed by Hadoop programs. The first is a map task, which takes one set of data and changes it into another set of data in which individual items are broken down into tuples (key/value pairs). The reduce job takes a map's output as input and merges those data tuples into a smaller collection of tuples. The reduction job is always executed after the map job, as the term MapReduce implies.
To speed up processing, MapReduce performs logic on the server where the data already resides rather than transporting the data to the location of the application or logic. MapReduce initially appeared as a tool for analyzing Google search results. However, It quickly gained popularity due to its ability to partition and analyze terabytes of data in parallel, resulting in faster results.
Features of MapReduce
Some of the features of MapReduce are discussed below:
MapReduce is a highly scalable framework. This is due to its ability to distribute and store huge amounts of data across multiple servers. These servers can all run at the same time and are economically priced.
MapReduce provides high security. The security mechanisms used by the MapReduce programming model are HBase and HDFS. Only authenticated users can read and manipulate the data.
Big data volumes can be stored and handled extremely affordably with the MapReduce programming framework and Hadoop's scalable design. This type of system is extremely cost-effective and scalable.
The MapReduce program runs faster because of the parallel processing. It makes it simpler for the processes to handle each job. Parallel processing allows many processors to carry out these broken-down tasks.
Hadoop MapReduce is built on a simple programming model and is one of the technology’s many worthy features. As a result, programmers may make efficient MapReduce applications that can handle tasks fast.
Implementation of MapReduce in Python
There are three main phases in the MapReduce framework. These are the Map, Filter, and Reduce models of functional programming. They let the programmer write simpler, shorter code without having to worry about complexities such as loops and branching. The map and filter are built-in modules with Python (in the __builtins__ module) and do not need to be imported. Reduce, on the other hand, must be imported because it is found in the Functools package.
Map Phase
The map() method in Python has the following syntax:
map(func, *iterable)
Where func is the function that would be applied to each element in iterable (however many there are), before we move on to an example, keep the following in mind:
The map() method in Python 2 returns a list. However, in Python 3, the function produces a map object, which is a generator object. The built-in list() function on the map object can be used to receive the result as a list. Specifically, list(map(func, *iterable)).
The number of parameters passed to func must equal the number of iterables specified.
The below code shows the implementation of the map() function:
The above code converts the input lower case strings to upper case using map(). Note that with respect to the syntax of the map(), the func, in this case, is str.upper, and iterable is the my_pets list. More importantly, we only sent one iterable to the str.upper function because that method's definition calls for just one input. Therefore, you must pass two, three, or n iterables to the function you are passing if it requires two, three, or n arguments.
Shuffle and Sort
As the mappers finish, the intermediate outputs from the map stage are moved to the reducers. This process of shifting output from mappers to reducers is known as shuffling. The partitioner is a divider function that moves the shuffle. The partitioner is responsible for directing the flow of key-value pairs from mappers to reducers. It is given the mapper's output key as well as the number of reducers. The partitioner ensures that all values for the same key are routed to the appropriate reducer.
The sorting process is the final stage before the reducers begin processing data. The Hadoop framework organizes the intermediate keys and values for each partition before passing them on to the reducer.
Filter Phase
The filter() first requires the function to return boolean values (true or false), and then iterates through the function, filtering out those that are false. The syntax is as follows:
filter(func, iterable)
The following points should be observed about filter():
In contrast to map(), only one iterable is required.
The func argument must return a boolean type. If not, the filter just returns the iterable that was supplied to it. Since only one iterable is necessary, it follows that func can only accept one parameter.
The filter runs each iterable element through func and only returns those that evaluate to true.
The below code shows the implementation of filter():
In the above code, there is a list (iterable) of the scores of 10 students in an exam. The code filters out those who passed with scores more than 75 using filter().
Reduce Phase
reduce applies a function of two parameters cumulatively on the elements of an iterable, starting with an optional initial argument. The syntax is as follows:
reduce(func, iterable[, initial])
Where func is the function to which each iterable element is cumulatively applied, and initial is the optional value that is inserted before the iterable items in the calculation. It serves as a default when the iterable is empty. The following points should be noted about reduce():
The first argument to func is the first element in iterable (if the initial is not specified), and the second argument is the second element in iterable. If an initial is given, it becomes the first argument to func, and the first member of iterable becomes the second element.
“reduce” reduces the iterable to a single value.
The code implementation of reduce() is as follows:
from functools import reduce
numbers = [3, 4, 6, 9, 34, 12]
def custom_sum(first, second):
return first + second
result = reduce(custom_sum, numbers)
print(result)
You can also try this code with Online Python Compiler
In the above code, the sum() function returns the sum of all elements in the iterable that was supplied to it. Reduce takes the first and second elements in numbers and passes them to custom_sum. custom_sum computes and returns their sum to reduce. Reduce then uses that result as the first element in custom_sum and the third element in numbers as the second element in custom_sum. This is repeated indefinitely until the number is exhausted.
Frequently Asked Questions
What is a distributed cache in MapReduce Framework?
The MapReduce framework has an important feature called distributed cache. Distributed cache is used to share files across all nodes in a Hadoop Cluster. The files could be executable jar files or plain text files.
What is NameNode in Hadoop?
Hadoop's NameNode is the node where Hadoop keeps all file location information in HDFS(Hadoop Distributed File System). It serves as the hub of an HDFS file system. It maintains a record of all files in the file system, and tracks file data throughout the cluster or many machines.
What is a task tracker in Hadoop?
In Hadoop, a Task Tracker is a slave node daemon that accepts jobs from a JobTracker. It also sends the JobTracker heartbeat signals every few minutes to certify that the JobTracker is still alive.
What is Identity Mapper?
The Identity Mapper class is Hadoop's default Mapper class. Identify will be run if no other Mapper class is declared. It simply writes the input data to the output and makes no computations or calculations on the input data.
Conclusion
This article explains the concepts of MapReduce in Python, its features, and its complete implementation, along with some frequently asked questions related to the topic. I hope this article was beneficial and that you learned something new. To have a better understanding of the topic, you can further refer to MapReduce Fundamentals and Hadoop MapReduce.






























 6+ registered
6+ registered 

