


























Introduction
MapReduce and Spark are powerful data processing frameworks widely used in the industry. While both can handle large-space data processing, do you know there are some key differences between them? Do you know how we can efficiently process vast amounts of data in the applications with a parallel distributed algorithm on a cluster?

In this article, we will discuss MapReduce vs. Spark by discussing their applications, pros, and cons. In the end, we will also outline some key differences between the two in tabular format. Moving forward, let’s first understand about MapReduce.
MapReduce
MapReduce is a framework used in distributed data processing. This programming model was primarily designed for processing distributed data introduced by Google. This framework helps to write applications for processing large amounts of data on multiple interconnected computers that work together and form a cluster.
Cluster means collections of computers (nodes) that are networked together for performing parallel computations on large data sets.
MapReduce is a component of Hadoop. The large dataset is split and combined in MapReduce for parallel processing to give a final result. Its libraries are written in various programming languages with the needed optimizations. It is used for mapping each job and reducing it to the equivalent tasks. This provides less overhead over a cluster network and reduces the processing power. This means the large data sets are divided into smaller tasks known as maps. These are then combined to give results known as ‘reduce’. This process reduces the overhead/workload over the cluster network and helps to minimize the power used to process the information.
MapReduce Processing Flow
Below are the steps of processing flow (Data flow) in MapReduce.
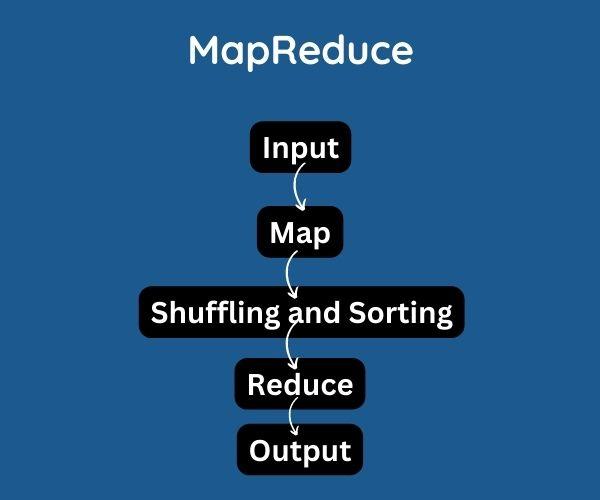
-
As an initial step, the input reader reads the upcoming data and splits it into required size data blocks where each data block is associated with a Map function. After the input reads the data, corresponding key-value pairs are generated, and the input files reside in HDFS.
-
The coping key-value pairs are processed by the map function, and the corresponding output key-value pairs are generated. Also, the map input and output type need not be the same each time.
-
As a next step, the output of each Map function is assigned to the appropriate reducer by the partition function. This function is provided by the available key and value pairs. The index of the reducers is returned.
-
The next step is shuffling and sorting, in which the data is shuffled between nodes to enable it to process for reduced function. On input data, the sorting operation is performed, where the data is compared through the comparison function and is arranged in a sorted manner.
Recommended article- Hadoop MapReduce
Pros of MapReduce
Below are some of the Pros of using MapReduce.
-
MapReduce is scalable due to its simple design.
-
At any step of execution, we have the control of the process.
-
MapReduce is parallel in nature. Therefore, it is efficient if we want to work with both structured and unstructured data.
-
MapReduce doesn't require very high memory compared to Hadoop’s other ecosystem components. Therefore it can work at high speed with minimal memory.
-
MapReduce is useful in computation and graph problems such as Geospatial query problems.
-
MapReduce is cost-effective as it enables users to store the data cost-effectively.
- MapReduce supports parallel processing through which multiple tasks of the same dataset can be processed parallelly.
Cons of MapReduce
Some of the cons of MapReduce are mentioned below.
-
Using MapReduce, one might face a big challenge, which takes a sequential multi-process approach to run a job and writes the output back in HDFS (Hadoop Distributed File System). As each step requires reading and writing, Its jobs are usually slower because of the latency or delay of disk I/O as this affects the performance and execution time.
-
Even for common operations such as join, filter, sorting, etc., a lot of manual coding is required.
-
It is challenging to maintain as the semantics are hidden inside the reduced functions and map.
-
It is a rigid framework.
- MapReduce is inefficient in real-time processing, such as OLAP and OLTAP.
Applications of MapReduce
Below are some of the applications of MapReduce.
-
MapReduce is used to distinguish the most loved items according to a client or customer's purchase history in multiple e-commerce suppliers like Amazon, Walmart, and eBay.
-
MapReduce is used in data warehouses for analyzing large data volumes in the data warehouse by implementing the required business logic and getting data insights.
-
MapReduce can handle failures without downtime.
-
MapReduce provides a scalable framework by allowing users to run an application from multiple nodes.
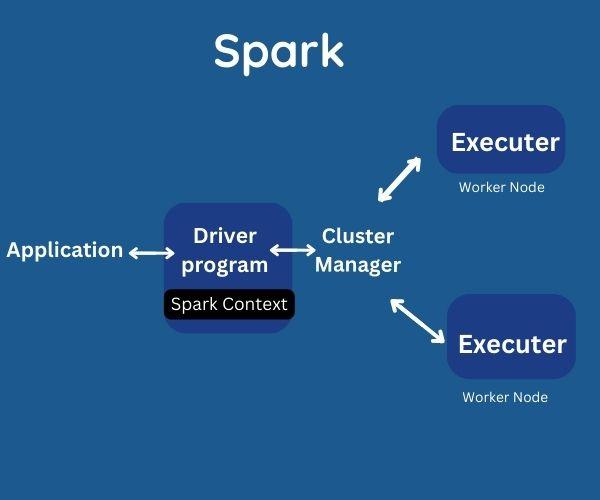
Moving forward, let’s understand about Spark.

 9+ registered
9+ registered 

