Do you think IIT Guwahati certified course can help you in your career?
Introduction
Unsupervised learning is a magnificent term, and it consists of a lot of algorithms. In this article, we're going to discuss the mean shift clustering. It lies under the category of Unsupervised Learning. It's a flexible and straightforward clustering technique with several advantages over other approaches.
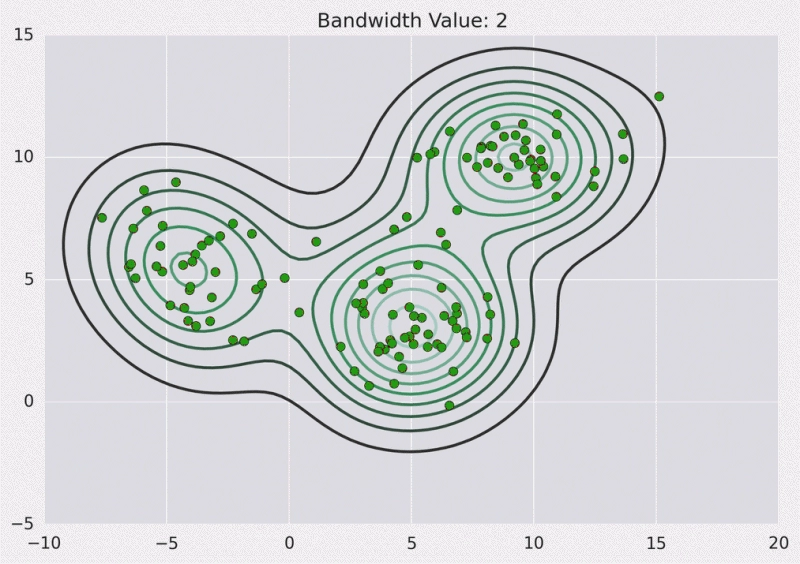
Mean shift clustering, also known as the mode-seeking algorithm, allocates the data points to the cluster sequentially by shifting towards the mode. Mode is known to be the highest density of data points in the region.
The mean shift clustering does not need to specify the number of clusters in advance, unlike the K-means cluster.
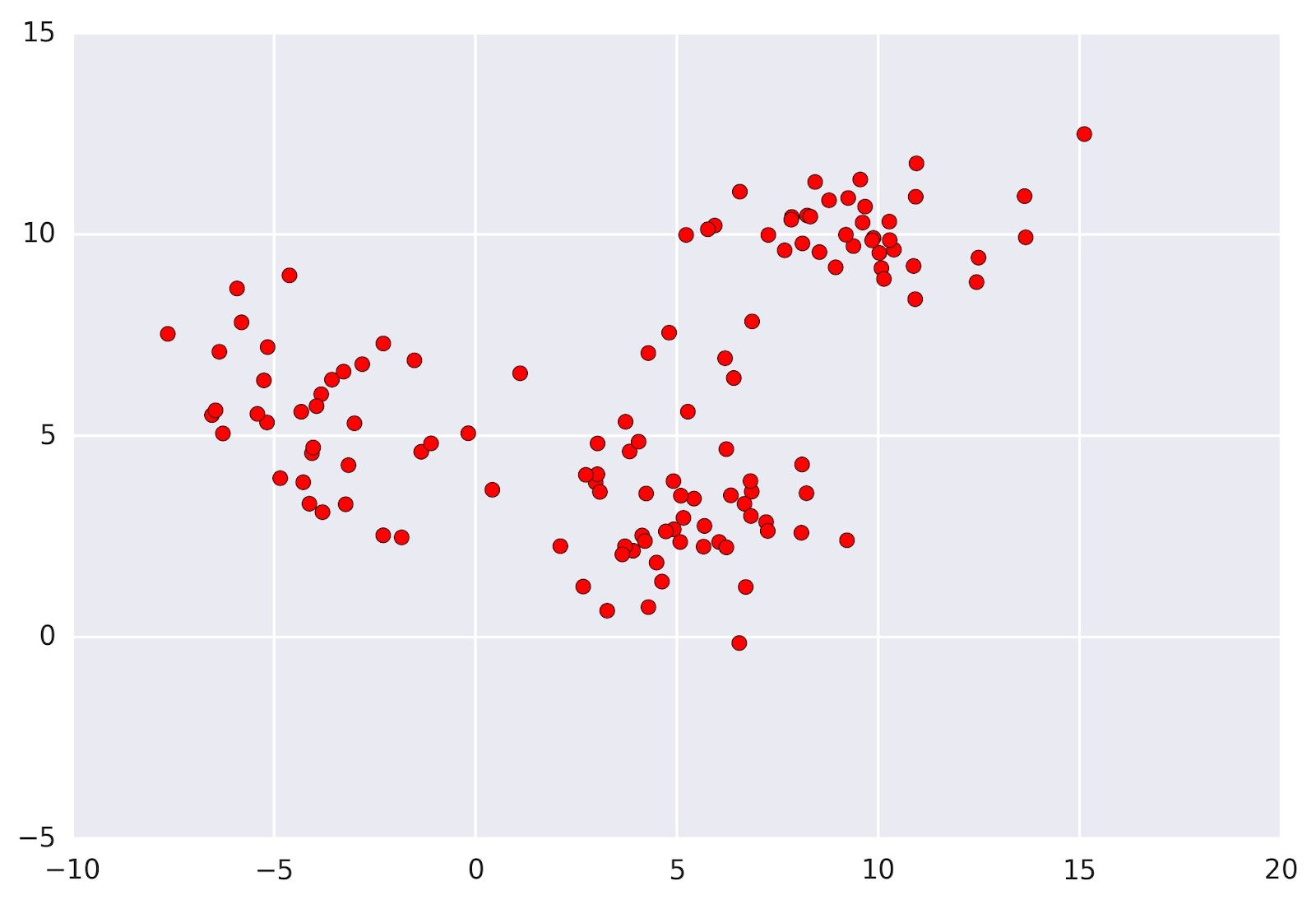
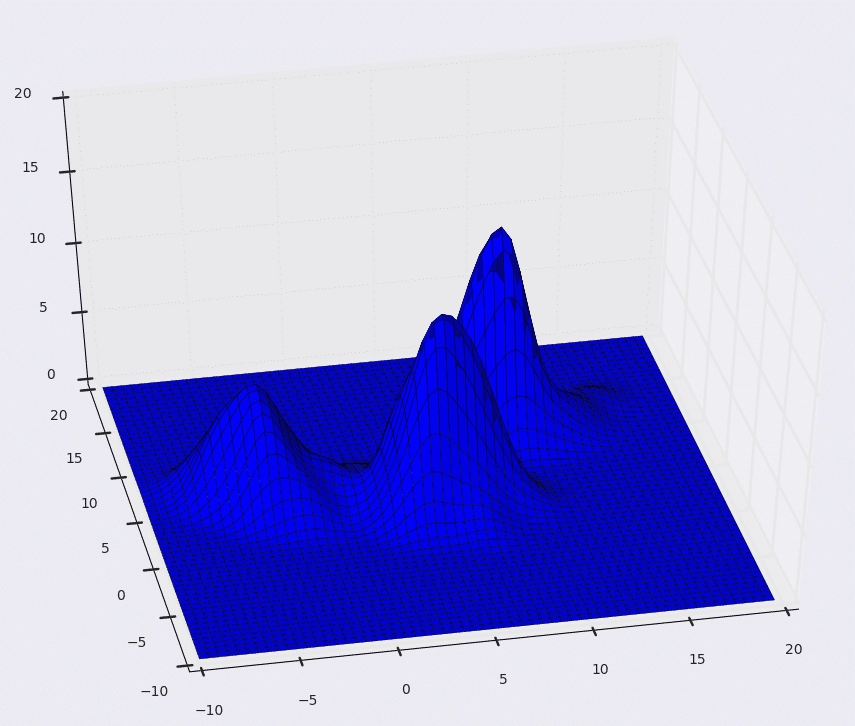
Mean Shift Clustering created the concept of kernel density estimation. Suppose that the above dataset was sampled from a probability distribution. Kernel Distribution Estimation is a process to estimate the underlying distribution, also called the probability density function for a data set.
The kernel is a fancy mathematical word for a weighting function generally used in convolution. There are various types of kernels, but the most widely used is the Gaussian kernel. Adding up all individual kernels generates a probability surface. The resultant density function will vary depending on the kernel bandwidth parameter used. The above data points can be divided into two parts
Just a single parameter where h has a physical meaning
It is model-free and doesn't assume any prior shape like spherical, elliptical, etc. on data clusters
Disadvantages of Mean Shift Clustering
The output depends on window size
The window size selection is not trivial
It is computationally expensive
It doesn’t scale well with dimension of feature space.
Frequently Asked Questions
What is mean shift clustering used for?
Mean shift clustering is an unsupervised learning algorithm mainly used for clustering. It is primarily used in real-world data analysis as it's non-parametric and doesn't need any predefined shape of the clusters.
Is mean shift density-based?
Mean Shift clustering is an unsupervised clustering algorithm that discovers spots in a smooth density of samples. It is a centroid-based algorithm that works by updating candidates for centroids to be the mean of the points within a given region.
Is mean Shift a clustering algorithm?
Mean Shift Clustering is a hierarchical clustering algorithm. Unlike supervised machine learning algorithms, clustering attempts to group data without having first been trained on labeled data. Clustering is used in various applications such as search engines, academic rankings, and medicine.
Conclusion
In this article, we have extensively discussed Mean Shift Clustering and its features. We hope that this blog has helped you enhance your knowledge regarding Mean Shift Clustering and if you would like to learn more, check out our articles here. Do upvote our blog to help other ninjas grow. Happy Coding!
Live masterclass
Prompt Engineering: Must-have GenAI Skill for 30L+ Roles at Amazon
by Anubhav Sinha
16 Jul, 2026
12:30 PM
Using Netflix Data to Master Power BI
by Ashwin Goyal
13 Jul, 2026
12:30 PM
Top GenAI Skills to crack 30L+ CTC at Amazon & Google
by Sumit Shukla
14 Jul, 2026
11:30 AM
JioHotstar Sports Analytics using IPL Dataset
by Prerita Agarwal
15 Jul, 2026
12:30 PM
Prompt Engineering: Must-have GenAI Skill for 30L+ Roles at Amazon






























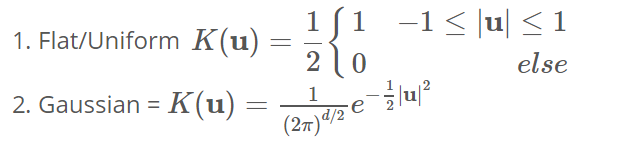

 9+ registered
9+ registered 

