



























Introduction
Natural Language Processing (NLP) aims to understand and interpret human language. Natural Language Toolkit (NLTK) is a beautiful package in Python, having multiple datasets, pre-trained models to carry out NLP tasks easily. NLTK helps in the tokenization of text, sentences, removing stopwords, searching, counting, plotting frequency distributions, etc. If you are new to NLTK, feel free to refer to this blog, to know more about NLTK, its use cases, and installation.
Methods in NLTK
Corpus operations
import nltk
nltk.download('brown')
from nltk.corpus import brown
print("Words are")
print(brown.words())
print("Total number of words is",len(brown.words()))
print("Sentences are")
print(brown.sents())
print("Total number of sentences is",len(brown.sents()))
print("Fileids are")
print(brown.fileids())Output
[nltk_data] Downloading package brown to /root/nltk_data...
[nltk_data] Package brown is already up-to-date!
Words are
['The', 'Fulton', 'County', 'Grand', 'Jury', 'said', ...]
Total number of words is 1161192
Sentences are
[['The', 'Fulton', 'County', 'Grand', 'Jury', 'said', 'Friday', 'an', 'investigation', 'of', "Atlanta's", 'recent', 'primary', 'election', 'produced', '``', 'no', 'evidence', "''", 'that', 'any', 'irregularities', 'took', 'place', '.'], ['The', 'jury', 'further', 'said', 'in', 'term-end', 'presentments', 'that', 'the', 'City', 'Executive', 'Committee', ',', 'which', 'had', 'over-all', 'charge', 'of', 'the', 'election', ',', '``', 'deserves', 'the', 'praise', 'and', 'thanks', 'of', 'the', 'City', 'of', 'Atlanta', "''", 'for', 'the', 'manner', 'in', 'which', 'the', 'election', 'was', 'conducted', '.'], ...]
Total number of sentences is 57340
Fileids are
['ca01', 'ca02', 'ca03', 'ca04', 'ca05', 'ca06', 'ca07', 'ca08', 'ca09', 'ca10']We can also access the data using fileids.
brown.sents(fileids='ca01') #we can access data using fileids as well.Output
[['The', 'Fulton', 'County', 'Grand', 'Jury', 'said', 'Friday', 'an', 'investigation', 'of', "Atlanta's", 'recent', 'primary', 'election', 'produced', '``', 'no', 'evidence', "''", 'that', 'any', 'irregularities', 'took', 'place', '.'], ['The', 'jury', 'further', 'said', 'in', 'term-end', 'presentments', 'that', 'the', 'City', 'Executive', 'Committee', ',', 'which', 'had', 'over-all', 'charge', 'of', 'the', 'election', ',', '``', 'deserves', 'the', 'praise', 'and', 'thanks', 'of', 'the', 'City', 'of', 'Atlanta', "''", 'for', 'the', 'manner', 'in', 'which', 'the', 'election', 'was', 'conducted', '.'], ...]If we have our custom text file, then we can use NLTK corpus reader to read and process it.
from nltk.corpus import PlaintextCorpusReader
corp_txt = PlaintextCorpusReader(r'C:/', 'NLTK.txt') #mention the text file directory
#now we can use corp_txt just like we used brown before.
Searching
We can search a word in a corpus using concordance function.
from nltk.corpus import brown
text = nltk.Text(brown.words())
print("Concordance:")
text.concordance("news")
print()
print("Distributionally similar words:")
text.similar("news")
print()
print("Vocabulary plot:")
text.plot(20)Output
Concordance:
Displaying 25 of 102 matches:
altimore's Florida Grapefruit League news ripened considerably late today when
. The appointment was announced at a news conference at which Skorich said he
who will be the unhappiest over the news that Musial probably will sit out mo
ts win a dramatic pennant . Romantic news concerns Mrs. Joan Monroe Armour and
entific training , he added . `` The news of their experiments reaches the far
resented in the averages . Some good news Although it looked like a routine te
ters it was accompanied by some good news . A substantial rise in new orders a
New York Social Register which made news last week . Published annually by Wi
ut to President Kennedy at his first news conference last January was about hi
ead as an exaggeration ( see foreign news ) , and the U.S. was agreeing with i
to his private office and broke the news : he would lead the fight to oust Co
to regard as `` an inferior man '' . News of Rayburn's commitment soon leaked
moment . In 1920 , as the startling news that the 1919 White Sox had conspire
embles . Soon after Loper leaked the news that Frankie had ordered `` two of e
ation . The editorial was based on a news association dispatch which said that
d . According to The Chicago Tribune News Service , State Atty. Gen. Stanley M
unese , much of each day's deluge of news will become clearer . At least , I h
stify its arms drive '' . The Soviet news agency TASS datelined from New York
Providence Journal is desperate for news . Usually a veteran has to hang hims
s Downers Grove , Aug. 8 -- A recent news story reported that Frank Sinatra an
ey should be examples . Church finds news features are helpful to the editor :
as made of material from The Detroit News on the King James version of the New
y helpful . We feel that The Detroit News is to be complimented upon arranging
enn T. Seaborg , `` admitted '' to a news conference in Las Vegas , Nevada , t
d . Mercenary : term of honor ? ? In news broadcasts I consistently hear the f
Distributionally similar words:
time house years state one night man people world door place and
audience word children idea president trial way heart
Vocabulary plot: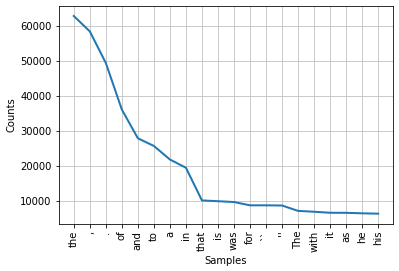
Counting
We can also perform essential tasks like counting the frequency of a particular word in a corpus, its relative frequency, and counting the total number of words using FreqDist class in NLTK.
from nltk.probability import FreqDist
fdist = FreqDist(brown.words()[0:50]) #taking small part of corpus
print("fdist")
print(fdist)
print()
print("Total number of tokens is", fdist.N())
print("The number of times said occured in the corpus is",fdist['said'])
print("The relative frequency of said is",fdist.freq('said'))Output
Total number of tokens is 50
The number of times said occured in the corpus is 2
The relative frequency of said is 0.04
fdist
FreqDist({"''": 1,
',': 2,
'.': 1,
"Atlanta's": 1,
'City': 1,
'Committee': 1,
'County': 1,
'Executive': 1,
'Friday': 1,
'Fulton': 1,
'Grand': 1,
'Jury': 1,
'The': 2,
'``': 2,
'an': 1,
'any': 1,
'charge': 1,
'deserves': 1,
'election': 2,
'evidence': 1,
'further': 1,
'had': 1,
'in': 1,
'investigation': 1,
'irregularities': 1,
'jury': 1,
'no': 1,
'of': 2,
'over-all': 1,
'place': 1,
'praise': 1,
'presentments': 1,
'primary': 1,
'produced': 1,
'recent': 1,
'said': 2,
'term-end': 1,
'that': 2,
'the': 3,
'took': 1,
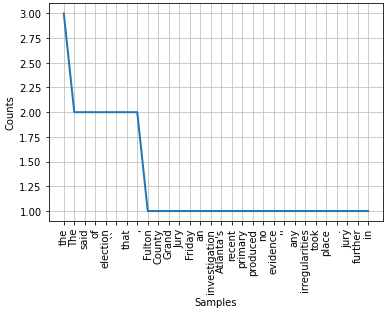
'which': 1})Plotting the frequency of words
fdist.plot(30)Output
Lexical Dispersion Plot
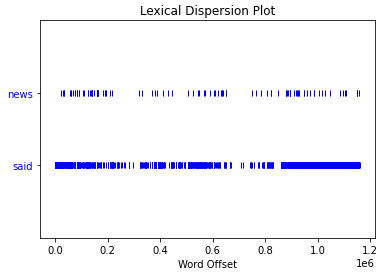
This helps to visualize the location of words in multiple sentences.
from nltk.draw.dispersion import dispersion_plot
from nltk.corpus import brown
text = nltk.Text(brown.words())
dispersion_plot(text, ['news','said'], ignore_case=True, title='Lexical Dispersion Plot')Output
 +
+

 9+ registered
9+ registered 

