Do you think IIT Guwahati certified course can help you in your career?
Introduction
Data structures and algorithms, the most important thing to practice, is incomplete without trees. A tree can be understood as a data structure that stores data in a hierarchical structure of nodes, having a root, edges, leaves, etc.
Let us increase our understanding of trees by discussing Mo’s algorithm and SQRT Decomposition for trees. It will help us to solve questions related to trees that require the use of advanced topics.
SQRT Decomposition is a query optimization algorithm that is used to solve offline query-based problems efficiently. The main idea for SQRT Decomposition is it splits the given array into smaller parts, specifically of size √N, where ‘N’ is the size of the given array so that the processing of queries decreases by a factor of √N.
This decomposition is frequently used in the case of arrays, but it can be used for trees also.
SQRT-Decomposition for trees
Similar to SQRT-Decomposition for arrays, in sqrt-decomposition for trees, we divide the nodes into ‘D’ smaller blocks and consider two pointers ‘L’ and ‘R’ for processing the queries block-wise. For the queries which are allotted the same block, the movement of pointer ‘R’ is shared such that it moves for maximum ‘N * D’ times. Similarly, the pointer ‘L’ moves for maximum ‘N / D’ times when moving from one query to the next.
To divide the nodes into ‘D’ blocks, we can implement another function, which will take the help of Depth First Search(DFS Algorithm) to assign block ids to the nodes. Every time we assign the current block ids to the nodes, and when the nodes in the current block exceed more than ‘D’, we make another block.
The pseudo-code for the above idea is as follows:
// Variables to store data.
int N, D, count = 0;
vector<int> blockID(N);
// DFS function for grouping the vertices.
vector<int> DFS(int node, int par)
{
// Vector to store nodes which are free and not in any group.
vector<int> freeNodes;
// Traversing the subtree of node.
for (auto x : edges[node])
{
// If the node is parent.
if (x == par)
continue;
// Vector to store the ungrouped nodes of subtree of node x.
vector<int> subTree = DFS(x, node);
// Transferring the ungrouped nodes into the final vector.
for (auto y : subTree)
freeNodes.push_back(y);
// If the size of the group is enough, we make it a block.
if (freeNodes.size() >= D)
{
// Assigning the block ID.
for (auto y : freeNodes)
blockID[y] = count;
// Updating the count.
count++;
// Clearing the vector.
freeNodes.clear();
}
}
// Pushing current node to be grouped with its parent node.
freeNodes.push_back(node);
// Finally returning the ungrouped nodes.
return freeNodes;
}
// Function used to group the free nodes.
void verticesGroup(int root)
{
vector<int> freeNodes = DFS(root);
// Assigning a new block id to the rest of the nodes.
for (auto node : freeNodes)
blockID[node] = count;
}
You can also try this code with Online C++ Compiler
For the problems where we are asked to solve queries in which the task is to find distinct elements in a given range, solving each query separately becomes expensive with respect to time complexity. So for these cases, Mo’s algorithm is proved to be the savior.
Mo’s algorithm precomputes all the queries in such a way that the results of previous queries are useful for the current queries.
This algorithm is always useful for solving offline queries related to arrays. Now let us discuss Mo’s algorithm for trees.
Mo’s algorithm for trees is mainly meant for finding path-related queries. Using Mo’s algorithm for trees we can find the number of distinct elements in the path from one node to another node in a very efficient manner. Mo’s algorithm for trees also uses the SQRT- decomposition method to decompose the tree into small blocks and then it sorts the queries based on it.
To find the nodes in the path between two nodes ‘x’ and ‘y’, we need to separately store the nodes occurring from root node to node ‘x’ and root node to node ‘y’. Then the symmetric difference between both the collection of nodes will be our collection of nodes that occurred on the path between the given nodes.
Let us understand this concept with the below example:
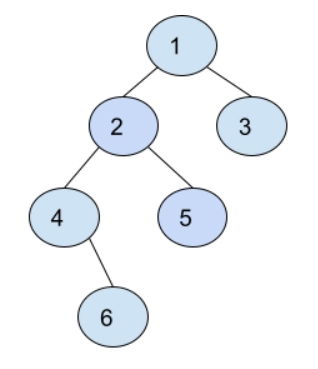
An arbitrary tree with 6 nodes.
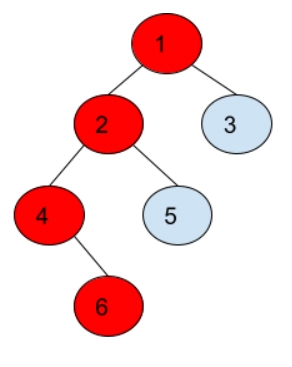
Path from the root node to node 6
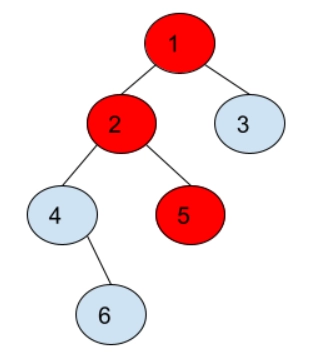
Path from the root node to node 5
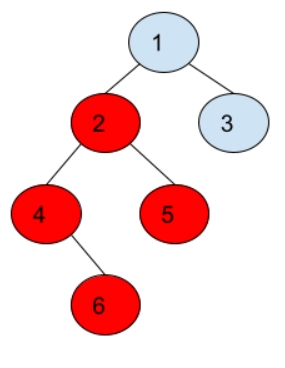
After taking the symmetric difference of both the path nodes, the path between nodes 5 and 6 is left.
Below is the implementation of the above explanation.
// Pseudo code template for Mo's algorithm in trees.
// Variables to store data.
int n, Q;
int TO[ N ], NEXT[ N ], hd[ N ];
struct Query {
int u, v, ID;
} query[ N ];
int blockID[ N ], dfn[ N ], dfn_, block_;
int stk[ N ], stk_;
// Using DFS to decompose the tree into blocks.
void DFS( int node, int par ) {
dfn[ node ] = dfn_++;
int saved_rbp = stk_;
for ( int v_ = hd[ node ] ; v_ ; v_ = NEXT[ v_ ] )
{
if ( TO[ v_ ] == par )
continue;
DFS( TO[ v_ ], node );
if ( stk_ - saved_rbp < SQRT_N )
continue;
for ( ++ block_ ; stk_ != saved_rbp ; )
blockID[ stk[ -- stk_ ] ] = block_;
}
stk[ stk_ ++ ] = node;
}
bool pathNode[ N ];
void SymmetricDifference( int u ) {
if ( pathNode[ u ] )
{
// remove this edge
}
else
{
// add this edge
}
pathNode[ u ] ^= 1;
}
void traverse( int& origin_u, int u ) {
for ( int g = LCA( origin_u, u ) ; origin_u != g ; origin_u = parent_of[ origin_u ] )
SymmetricDifference( origin_u );
for ( int v = u ; v != origin_u ; v = parent_of[ v ] )
SymmetricDifference( v );
origin_u = u;
}
// Solving by sorting the queries and applying Mo's algorithm.
void MosAlgo() {
// Decomposing the tree into blocks with the help of DFS.
DFS( 1, 1 );
while ( stk_ )
blockID[ stk[ -- stk_ ] ] = block_;
// Sorting the queries.
sort( query, query + Q, [] ( const Query & x, const Query & y ) {
return tie( blockID[ x.u ], dfn[ x.v ] ) < tie( blockID[ y.u ], dfn[ y.v ] );
} );
// Finally applying Mo's algorithm.
int U = 1, V = 1;
for ( int i = 0 ; i < Q ; ++ i ) {
pass( U, query[ i ].u );
pass( V, query[ i ].v );
// we could our answer of que[ i ].ID
}
}
// Main Function.
int main()
{
// Taking input of n and number of queries.
cin >> n >> Q;
// Constructing the graph.
for ( int i = 1 ; i < n ; ++ i )
{
int u, v;
cin >> u >> v;
// Saving the tree edges.
NEXT[ i << 1 | 0 ] = hd[ u ];
TO[ i << 1 | 0 ] = v;
hd[ u ] = i << 1 | 0;
NEXT[ i << 1 | 1 ] = hd[ v ];
TO[ i << 1 | 1 ] = u;
hd[ v ] = i << 1 | 1;
}
// Reading and storing input.
for ( int i = 0 ; i < Q ; ++ i )
{
cin >> query[ i ].u >> query[ i ].v;
query[ i ].ID = i;
}
MosAlgo();
return 0;
}
You can also try this code with Online C++ Compiler
What is the main difference between SQRT Decomposition and Mo’s algorithm for trees? In sqrt root decomposition, the sorting of queries is not necessary but for Mo’s algorithm, the queries must be sorted in a specific order as it is the key of the algorithm.
What is the time complexity of Mo’s algorithm? The time complexity of Mo’s algorithm is O((N + Q) * √N), where ‘N’ is the number of elements in the array and ‘Q’ is the number of total queries.
What are trees? A tree can be understood as a data structure that stores data in a hierarchical structure of nodes, having a root, edges, leaves, etc.
What is SQRT Decomposition? SQRT Decomposition is a query optimization algorithm, that is used to solve offline query-based problems efficiently. The main idea for SQRT Decomposition is it splits the given array into smaller parts, specifically of size √N, where ‘N’ is the size of the given array so that the processing of queries decreases by a factor of √N.
Why Mo’s algorithm involves sorting of the queries? In Mo’s algorithm, the queries are sorted so that the array which is decomposed into blocks remains in an order such that calculation of a query is helpful for other queries.
Key Takeaways
The above article involves an interesting discussion regarding the SQRT-decomposition and Mo’s Algorithm for trees. Both methods are quite important for path-related queries.
Find more such interesting questions on our practice platform Coding Ninjas Studio if you want to learn more before jumping into practicing, head over to our library section for many such interesting blogs. Keep learning.































 9+ registered
9+ registered 

