Depth-wise Separable Convolution
Depth-wise separable convolutions form the backbone of MobileNet. The main idea behind depth-wise separable convolution is that the image input and the filter can be separated and processed individually, thus the name separable. Depth-wise separable convolutions are made of two layers, depth-wise convolution and point-wise convolution.
Depth-wise convolution
Typical image input is not two-dimensional. It has different channels and has a three-dimensional shape. We can say that our image and filter have depth in them. A depth-wise convolution breaks down the image into its constituent channels and then applies a filter to each channel.
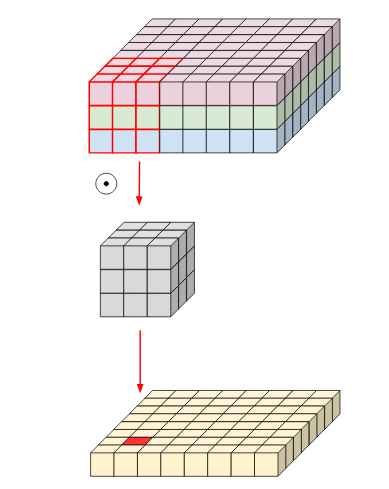
Normal Convolution network
For example: if we have an image with three channels. A regular convolution network applies the filter to the whole input while in depth-wise convolution, a single filter is applied to each input channel. The output of a standard convolution is a single layer while in the depth-wise convolution, the number of output layers equals the number of input channels.

Depth-wise Convolution
Point-wise convolution
Depth-wise convolution is very efficient in comparison to normal convolution. However, the output contains different channels, and we need to combine them for further processing. A 1X1 convolution known as point-wise convolution is applied to the output of depth-wise convolution. The image below shows that point-wise convolution transformed the three channels into a single layer.
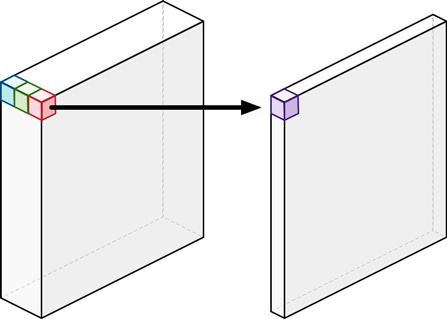
Point-wise convolution
A depth-wise separable convolution is formed by combining a depth-wise convolution with a point-wise convolution. Using depth-wise separable convolutions, the number of parameters used is reduced drastically. According to the original paper, the reduction in computation in a depth-wise separable convolution in comparison to a normal convolution is given by:
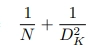
Where DK is the spatial dimension of the kernel assumed to be a square and N is the number of output channels.
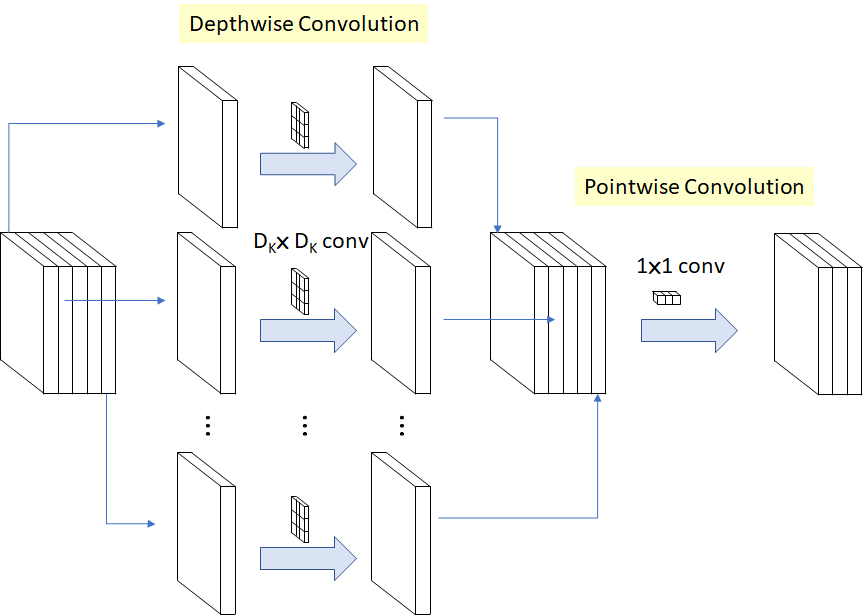
Depth-wise separable convolution
MobileNet Architecture
MobileNet uses 3 X 3 depth-wise separable convolutions that save the computation cost up to 8 to 9 times while the reduction in accuracy is minor.
A standard MobileNet block looks like:
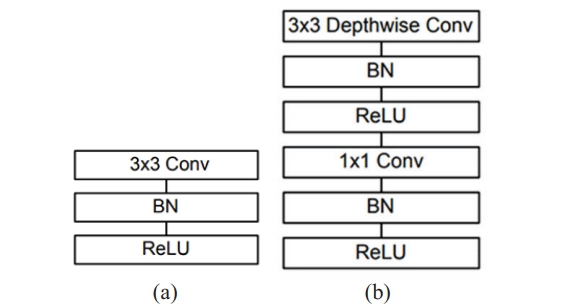
A MobileNet block vs a standard convolution
- A normal convolution layer with batch normalization and ReLU activation function.
- A depthwise separable convolution layer with 3X3 depth-wise convolution followed by batch normalization and ReLU activation layer and a pointwise convolution followed by batch normalization and ReLU.
Complete MobileNet architecture:
If we take depthwise and pointwise convolution as different layers. MobileNet has 28 layers.
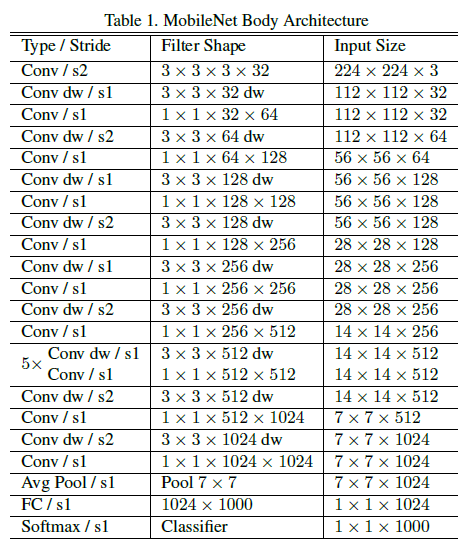
source
Performance of MobileNet
We can see below that a MobileNet uses much fewer parameters than a standard convolution network with only a 1.1% reduction in accuracy.
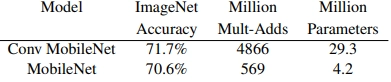
Standard convolution vs MobileNet
MobileNet performs at par with other popular methods despite having significantly fewer parameters:
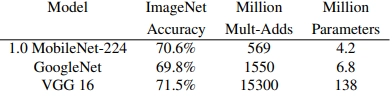
MobileNet vs popular models
Implementation of MobileNet
To implement a MobileNet block:
First, we need to insert a 3X3 depth-wise separable convolution layer:
x = DepthwiseConv2D(kernel_size = 3, strides = 2, padding = 'same')(x)

You can also try this code with Online Python Compiler
Adding Batch Normalization and ReLU:
x = BatchNormalization()(x)
x = ReLU() (x)
You can also try this code with Online Python Compiler
Then, we have to add point-wise convolution layer which is basically a 1X1 convolution:
x = Conv2D(filters = 64, kernel_size = 1, strides = 1)(x)
You can also try this code with Online Python Compiler
Adding batch normalization and ReLU:
x = BatchNormalization()(x)
x = ReLU()(x)
You can also try this code with Online Python Compiler
Frequently Asked Questions
-
Are there more models requiring less computational power than the standard convolution network?
Yes, there are more such models—for example, ResNet-50.
-
How can MobileNet work on smartphones?
Any mobile application that can use a TensorFlow library can be used to implement MobileNet.
-
How many versions of MobileNet are there?
There are total three versions of MobileNet.
Conclusion
This blog discussed the need for a light neural network model that can perform well with less computational power and how MobileNet caters to that need. We learned about Depth-wise separable convolution, which is the backbone of MobileNet. We saw the architecture of MobileNet and how we can implement a standard MobileNet block in our code. You can learn more about other popular models like AlexNet, ResNet, and ZFNet at coding ninjas. To get a complete understanding of various machine learning algorithms, check out our Machine learning course.




























 Deep learning models are coming to our smartphones
Deep learning models are coming to our smartphones


 9+ registered
9+ registered 

