Do you think IIT Guwahati certified course can help you in your career?
Introduction
Hey Ninjas. Do you know about the NoSQL database Cassandra? You can handle large amounts of data with Cassandra. We use Cassandra in many areas, such as social media, e-commerce, IoT, etc.
In this article, we will learn about modifying the keyspace in Cassandra. We will cover how to create keyspace, alter keyspace properties and some examples. So let's dive into studying modifying keyspace in Cassandra.
Overview of Cassandra
Cassandra is a distributed NoSQL database. It gives high performance and throughput. It has a peer-to-peer architecture. Your data will get distributed in multiple nodes in a cluster. It uses a very flexible data model. Column families are similar to tables in an RDBMS. Here data is sorted by column, not by row. Cassandra is open-source and free to use. Companies like Netflix, Twitter, and eBay use it.
Data Model of Cassandra
This Cassandra data model gives a high write throughput and low write latency. Here we have data sorted by column, not by row, to improve query performance.
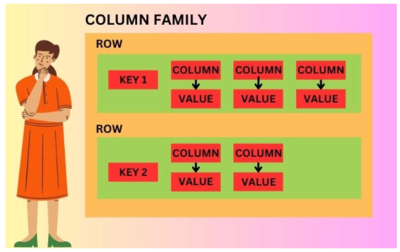
It has a column-family data model. A column family is a collection of rows that share the same structure.
A unique primary key identifies a row.
You can have any number of columns in a row. Each column will have some value and a name. You can actively add or remove a column, which won't affect other columns.
You can create secondary indexes on one or more columns.
Understanding Keyspaces
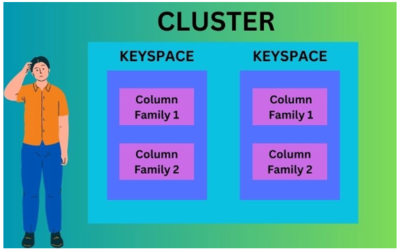
A keyspace is the highest-level container. We have multiple keyspaces within a cluster. It's similar to a schema in a relational database. A keyspace has one or more column families. You can actively create column families in a keyspace. Keyspaces support different data types, such as time series or wide-column data. You can isolate and secure your data in different keyspaces based on your requirements. You can back up, restore or migrate a keyspace.
Syntax
CREATE KEYSPACE Mykeyspace_name WITH replication = {'class': 'replication_strategy', 'replication_factor': any_value};
keyspace_name - It is the name of the keyspace
replication_strategy - It is the replication strategy (SimpleStrategy or NetworkTopologyStrategy). SimpleStrategyis the default. Use it when you want only one data centre. Use NetworkTopologyStrategy when you want to have multiple data centres.
replication_factor - It is the number of copies of each piece of data you want to store on different nodes in the network. If you set it to 4, each piece of your data gets stored on four nodes in the cluster. If one or two, or three nodes fail, the data will still be available on the remaining nodes.
any_value - It is the number of replicas.
Create Keyspace
You can create a new Keyspace to organize and store data within a cluster. Here is an example command to make a new keyspace:
CREATE KEYSPACE Ninja_keyspace WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 2} AND durable_writes = true;
First, use the CREATE KEYSPACE command to make a new keyspace.
Then give the name of the keyspace after CREATE KEYSPACE (Ninja_keyspace).
Next, use the WITH keyword to specify replication settings for your keyspace.
Now, choose your replication strategy (SimpleStrategy).
Next, mention the number of replicas for the keyspace (2).
durable_writes will ensure whether write operations will get stored in the commit log on disk. By default, durable_writes is true.
Use a semicolon to close your command.
EXAMPLE
We have created a Keyspace ‘ninja_keyspace’ with ‘SimpleStrategy’ having ‘replication_factor’ one using CREATE KEYSPACE command.
Drop Keyspace
It means deleting the keyspace, including all objects stored within it, such as tables, functions, and data. Here is an example command to drop a keyspace:
DROP KEYSPACE Ninja_keyspace;
First, use the DROP KEYSPACE command and the keyspace name you wish to drop.
It will remove the ‘Ninja_keyspace’ keyspace and all data you have stored in it.
But dropping a keyspace will permanently delete all your stored data. So only do it if you don't need the data any longer.
We have learned a lot about keyspaces in Cassandra. Now let’s start to study modifying keyspaces in Cassandra.
EXAMPLE
We deleted our entire ‘ninja_keyspace’ Keyspace using the DROP command.
Modify Replication Strategy
It involves changing how data is replicated across nodes within a cluster. You can do it for better performance and fault tolerance. You can do it using specific commands. It needs careful testing to avoid data loss.
Here is an example command with SimpleStrategy that alters the replication factor.
ALTER KEYSPACE Ninja_keyspace WITH REPLICATION = {'class': 'SimpleStrategy', 'replication_factor': 4};
You can use the ALTER KEYSPACE command with the WITH to specify the new replication settings.
This command will change the replication factor to 4.
EXAMPLE
We are altering the properties of our Keyspace. We use ALTER KEYSPACE to change the ‘replication_factor’ from two to one.
Here is another example command with NetworkStrategy that alters the replication factor.
ALTER KEYSPACE Ninja_keyspace
WITH replication = {'class': 'NetworkTopologyStrategy', 'd_c1': 4, 'd_c2': 4, 'd_c3': 4, 'd_c4’: 4 };
Start with ALTER KEYSPACE command.
We use data centres to control how many copies of the data we store in each location.
Here, we set the replication factor 4 for four data centres.
EXAMPLE
First, we created a Keyspace ‘ninja_keyspace’ with 'NetworkTopologyStrategy'. Initially, the ‘replication_factor’ of datacentre ‘datacenter1’ is one. Then we used ALTER KEYSPACE command to change it from one to two. Later we are using DESC to describe our Keyspace.
Here we choose one particular column called the "primary key". My_colmn1 has unique values for each row. It will help us to identify each row in the table.
To modify a column family, we use ALTER COLUMN FAMILY. You will have options such as adding or dropping a column, changing the keyspace, etc. Here is an example command to add a new column to a column family:
ALTER COLUMN FAMILY colmn_fam_name
ADD colmn_name text;
We add a column (colmn_name) to a column family (colmn_fam_name).
Now you have learnt many commands of modifying keyspace in Cassandra. So let’s discuss some pros and limitations of using keyspace in Cassandra.
EXAMPLE
We are using ‘ninja_keyspace_one’ using the USE command. Then, we created a table ‘coder’ in the ‘ninja_keyspace_one’ using CREATE TABLE. We have three columns. We gave every column a name. ‘coder_name’ is the PRIMARY KEY.
Now, we are altering our table. We add one more column, ‘age’, using ALTER TABLE command. We are using the SELECT command to display our table.
Now, we are adding values to our table using the INSERT command. Again we use SELECT to display the table. Now we have one row with values.
Finally, we delete the entire ‘coder’ table using the DROP command.
Advantages of Keyspace
Here are a few pros of using Keyspace in Cassandra:
It will give you a way to group data related to each other.
You can distribute your data in multiple nodes.
You can use replication to ensure your data is available and durable.
It will give you various centres for use during disaster recovery.
You can specify the number of replicas for each data centre.
It reduces your storage needs.
Limitations of Keyspace
Here are a few limitations of keyspaces in Cassandra:
It has a fixed schema. It can sometimes limit flexibility in data modelling.
It has high maintenance and is more complex.
It needs careful planning for better performance.
It may not fit specific use cases requiring complex relationship models or heavy cross-row transactions.
You must have learned everything about modifying keyspaces in Cassandra. Now let’s go through some frequently asked questions.
A virtual node (vnode) is a way to distribute data evenly across nodes in a cluster. Each vnode is responsible for some range of partition keys. You can improve performance by adding more vnodes.
Why do we change the replication factor of a keyspace?
We modify it to control the number of copies of each data we store in the cluster. We can improve fault tolerance by increasing the replication factor. But also increases the storage and network traffic.
What is a snitch in Cassandra?
It determines the network location of each node in the cluster. It is essential for balancing the load across the nodes. There are many types of snitches. Each snitch has its algorithms.
What is replication?
We use it to create multiple copies of data in different nodes in a distributed system. It ensures fault tolerance and data duplicity. It improves performance.
Can you add a new data centre to Keyspace?
Yes, we can add a new data centre. We have to modify the replication factor of the existing keyspace. Then create new nodes in the new data centre. We can use the ALTER KEYSPACE command.
Conclusion
Modifying keyspace in Cassandra is a very flexible feature. By modifying keyspace in Cassandra, we can adjust settings without losing existing data. In this article, we learned about Cassandra and its data model. We discussed how to create, add and drop keyspaces in Cassandra. It would help if you referred to other resources and materials. They will amplify your learning of modifying keyspaces in Cassandra.





































 8+ registered
8+ registered 

