Do you think IIT Guwahati certified course can help you in your career?
Introduction
MongoDB GridFS is a file storage system in the MongoDB database. It makes addressing the growing need for handling multimedia content, such as images, videos, and documents, in various applications and industries easier. It handles huge files and makes them available for a variety of use cases by offering integrated solutions.
In this blog, we will discuss the collection, index, sharding, limitation, reading and writing files, etc., in MongoDB GridFS.
GridFS in MongoDB
In Mongodb, GridFS is a technology that stores big files larger than the 16 MB size limit for BSON documents. It is a specification for storing and retrieving files larger than the allowed document size by breaking them up into smaller pieces, or "chunks," and storing each as a new document in a MongoDB collection.
You can use MongoDB's drivers or libraries in various computer languages, including Python, JavaScript (Node.js), and others, to communicate with GridFS in MongoDB.
You can upload, download, delete, and query files stored in GridFS using these drivers' unique APIs and techniques for working with MongoDB GridFS.
In MongoDB GridFS, by default, there are two collections:-
fs.chunks
fs.files
Collections in MongoDB GridFS
In MongoDB GridFS, there are two collections used to store the data.
Chunks Collection
The Chunks Collections stores the actual file data in chunks. Every file is broken up into fixed-size pieces except the final chunk, which can be smaller. Every chunk is kept in the chunks collection as a separate document.
Format
The chunk collections document takes the following format:-
The fields in the chunks collection document are:-
files_id: The unique file identification to which the chunk belongs.
n: the chunk's internal sequence number in the file.
data: The chunk's binary contents.
Files Collection
In the files collection, each file is represented as a single document. The file metadata is kept in this collection. In this collection, the files' names, sizes, upload dates, and any other custom metadata you want to add are all stored as metadata.
Format
The files collections document takes the following format:-
The fields in the chunks collection document are:-
_id: The file's special identification number.
filename: The file's name.
length: The overall length or file size.
chunkSize: The number of bytes in each chunk.
uploadDate: The timestamp that shows when the file was submitted.
contentType: This refers to the file's MIME type or content type.
Indexes in MongoDB GridFS
In MongoDB, each chunk and file collection in GridFS uses an index. Drivers that follow the GridFS specification construct these indexes for convenience automatically. MongoDB uses indexes to find and retrieve the needed data effectively. In MongoDB GridFS, two types of indexes are chunk and file indexes.
Chunks Index
The chunks collection's unique compound index is built by GridFS using the files_id and n fields. This enhances the efficiency of operations and inquiries.
Command
Command to create a compound index on the "files_id" and "n" fields is:-
MongoDB GridFS support sharding and enables you to distribute your file data across various MongoDB shards for scalability and high-performance file storage. By sharding the "fs.files" and "fs.chunks" collections, MongoDB GridFS implements sharding.
To shard the chunks collection, use {files_id : 1, n : 1} or {files_id : 1} as the shard key index.
The choice of sharding key for the "fs.files" collection in GridFS might affect how file metadata records are distributed among shards. The "fs.files" collection can benefit from even distributing the file metadata records among shards by selecting a suitable sharding key.
Reading and Writing Files in MongoDB GridFS
Let’s see the code to read and write files in MongoDB GridFS.
Writing Files in MongoDB GridFS
//1. Loading the Mongoose driver
var mongooseDv = require("mongoose");
//2. Connecting to MongoDB Database
mongooseDv.connect('mongodb://localhost/filesDB', {
useMongoClient: true
});
//3. The Connection Object
var connection = mongooseDv.connection;
if (connection !== "undefined") {
console.log(connection.readyState.toString());
//4. Loading the Path object
var path = require("path");
//5. Loading the grid-stream
var grid = require("gridfs-stream");
//6. Loading the File-System module
var fs = require("fs");
//7. Read the video/image file from the video read folder
var filesrc = path.join(__dirname, "./filestoread/cn.png");
//8. Establishing a connection between Mongo and GridFS
grid.mongo = mongooseDv.mongo;
//9. Open the connection and write the file
connection.once("open", () => {
console.log("Connection Open");
var gridfs = grid(connection.db);
if (gridfs) {
/* Create a stream; this will be
used to store files in a database*/
var streamwrite = gridfs.createWriteStream({
//the file will be stored with the name
filename: "cn.png"
});
/* Create a read stream to read the file
from the file stored folder
and pipe into the database
*/
fs.createReadStream(filesrc).pipe(streamwrite);
// Complete the write operation
streamwrite.on("close", function(file) {
console.log("successfully written in database");
});
}
else {
console.log("No Grid FS Object");
}
});
}
else {
console.log('Not connected');
}
console.log("done");
Reading Files in MongoDB GridFS
var mongooseDrv = require("mongoose");
var schema = mongooseDrv.Schema;
mongooseDrv.connect('mongodb://localhost/filesDB', {
useMongoClient: true
});
var connection = mongooseDrv.connection;
if (connection !== "undefined") {
console.log(connection.readyState.toString());
var path = require("path");
var grid = require("gridfs-stream");
var fs = require("fs");
var videosrc = path.join(__dirname, "./filestowrite/coding.mp4");
Grid.mongo = mongooseDrv.mongo;
connection.once("open", () => {
console.log("Connection Open");
var gridfs = grid(example.db);
if (gridfs) {
var fsstreamwrite = fs.createWriteStream(
path.join(__dirname, "./filestowrite/codingninjas.png")
);
var readstream = gridfs.createReadStream({
filename: "codingnninjas.png"
});
readstream.pipe(fsstreamwrite);
readstream.on("close", function(file) {
console.log("File Read successfully from database");
});
}
else {
console.log("No Grid FS Object");
}
});
}
else {
console.log('Not connected');
}
console.log("done");
Adding Files in MongoDB GridFS
MongoDB command-line tool “MongoFiles” is used to add files in GridFS. By default, GridFX will store the files in the database name “test”.
Command
mongofiles put path/to/file_name
Output
To store the files, a specific database command is:-
mongofiles put path/tp//file_name –db database_name
Output
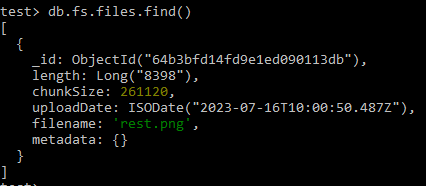
Now, to view the files in the document, write the below command.
db.fs.file.find()
Output
Limitations of MongoDB GridFS
The few limitations of MongoDB GirdFS are:-
GridFS requires more storage because file data is stored in chunks instead of storing files directly in a standard file system.
When files are stored in GridFS, more documents are produced than in the conventional file system. With more documents to handle, this may affect some operations like querying and indexing performance.
MongoDB GridFS may have a higher latency than serving files straight from a file system due to the need to retrieve and assemble several pieces, serving files through it.
File management and manipulation may be more difficult because files are kept in pieces across many pages, especially when multiple chunks are involved.
GridFS does not fully support transactions. While atomic operations are possible within a single chunk, transactions are incomplete when they include many chunks or files.
Frequently Asked Questions
How are files stored in MongoDB using GridFS?
In MongoDB, GridFS separates data files into smaller pieces and saves each as a document in two collections, one for file metadata and the other for file fragments.
How does GridFS offer high availability and data redundancy?
The replica set design of MongoDB GridFS offers high availability and data redundancy by ensuring that file chunks are automatically duplicated over several nodes, reducing the possibility of data loss and assuring data availability.
What is the procedure for directly accessing GridFS files over HTTP URLs?
You must set up your application server to handle requests for MongoDB GridFS files and provide them to clients directly to access GridFS files using HTTP URLs.
What is the difference between multer and GridFS?
The main difference between both of them is multer is NodeJS middleware that uploads files whereas GridFS is a storage engine for multer to upload files to MongoDB.
Conclusion
MongoDB GridFS allows you to retrieve and store big files in a database. GridFS splits files into smaller chunks and stores them separately as a document.
Do not stop learning! We recommend you read some articles related to MongoDB GridFS:
But suppose you have just started your learning process and are looking for questions from tech giants like Amazon, Microsoft, Uber, etc. For placement preparations, you must look at the problems, interview experiences, and interview bundles.


































 9+ registered
9+ registered 

