Do you think IIT Guwahati certified course can help you in your career?
Introduction
Traversing data structures is indeed one of the core and fundamental operations in computer science and programming. It's a fundamental building block for many algorithms and is essential for various tasks and applications. When we talk about tree traversal, then as the name suggests, it is the process of visiting all the nodes of a tree in a specific order.
You must have heard about In Order, Preorder, Postorder and Level Order Traversal. But in this article, we will be talking about one lesser known but elegant method for traversing binary trees, i.,e, Morris Traversal Postorder Algorithm.
So, let us start our journey:
Traditional Postorder Traversal
Before going to the Morris Traversal Postorder, let us first understand the traditional approach to deal with the Postorder technique:
Postorder traversal is a binary tree traversal algorithm. It traverses a binary tree in the following order: left => right => root.
Starting from the root, it recursively visits the left and right subtrees, and only after traversing both, it processes the current node.
Let us take an example to understand it in a better way:
The postorder of the above binary tree would be: 2 7 5 20 10.
Need of the Morris Traversal
So far we have discussed the traversals that are Iterative or Recursive. In the Iterative approach, we used Stack and in the recursive approach, the stack is implemented internally for maintaining the calls.
While these approaches work well, they require additional memory space for maintaining the call stack or an explicit stack data structure.
The Morris Traversal Algorithm aims to perform tree traversal without any extra memory usage, making it highly efficient in terms of space. So, we aim to achieve O(1) space complexity with the help of Morris Traversal Algorithm.
Understanding the Morris Traversal Postorder
Morris Traversal Postorder is a variation of the Morris Traversal algorithm that allows you to traverse a binary tree in Postorder (left-right-root) order without using additional memory structures like stacks.
It uses the Morris Link technique to achieve this.
The links which we will be generating between the nodes will be temporary, that means after successful traversal of the nodes, the changes are reverted back to restore the original tree.
Algorithm
Below are the following steps that are need to follow:
Step 1: Make the dummy node and update its left child as dummy.left = root
Step 2: Set the current node = dummy node
Step 3: If the left child of the current node is empty, use its right child as the current node
Step 4: If the left child of the current node is not empty, find the predecessor node of the current node
a) If the right child of the predecessor node is empty, set its right child to the current node. The current node is updated to be the left child of the current node
b) If the right child of the predecessor node is the current node, reset its right child to empty. Output all nodes on the path from the left child of the current node to the predecessor node in reverse order. The current node is updated to be the right child of the current node
Step 5: Repeat steps 3 and 4 above until the current node is empty
Pseudo Code
TreeNode dump( 0 )
dump.left = root
current = dump
while (cur)
if (cur.left == NULL)
cur = cur.right;
else
pre = cur.left;
while (pre.right is NOT NULL and pre.right is NOT cur)
pre = pre.right;
if (pre.right == NULL)
pre.right = cur;
cur = cur.left;
else
printReverse(cur.left, pre); // call print
pre.right = NULL;
cur = cur.right;
Time for an Example
Let us retake the above example and try to implement the Morris Traversal idea to find out the Postorder:
We have the following binary tree:
We will follow step by step:
First Iteration:
Step 1: Create the dummy node and update its left child to dump.left = root.
Make the current as the dump node.
Step 2: Iterate through the tree until the current node is not null.
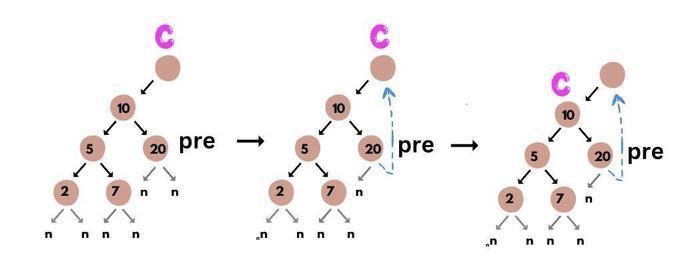
Step 3: In this step we check if the current.left is null or not. If null then, we update the current node to current.right. In our case, this is not true. So, we move to the else part.
In the else part, we find the predecessor of the current node. The predecessor of the current node is the rightmost node of its left node.
The predecessor of the current node will as following:
Now, we check:
if (pre.right == NULL)
pre.right = cur;
cur = cur.left;
In our case, pre.right is null so, we enter in the if block and execute the statements that says:
pre.right = current and update the current.
The result will look like this:
Second Iteration:
Again, the current is not null.
In this iteration also, we move to the else section. We again find the predecessor of the current node. The result will look like this:
Now, we check if the
if (pre.right == NULL)
pre.right = cur;
cur = cur.left;
In our case, pre.right is null. So, we update and execute the inner statements.
The result will look like this:
Third Iteration:
In this iteration, we will follow the same as above:
The result will look like this:
Fourth Iteration:
Here comes the interesting part. Here again our current is not null, so we go inside the loop and check for the conditions.
if (cur.left == NULL)
cur = cur.right;
In our case, it is true, so we update the current to current.right.
The result will look like this:
If you follow the same steps, this will result in the postorder traversal.
Here is the breakdown of the complexity analysis of Morris Traversal:
Time Complexity:
The time complexity of the Morris Traversal algorithm is O(n), where 'n' is the number of nodes in the binary tree.
This complexity analysis is based on the fact that each node is visited exactly twice: once when establishing the Morris links (in the worst case) and once when traversing the tree.
Space Complexity:
The Morris Traversal algorithm is renowned for its space efficiency because it uses only a constant amount of extra space, making it an in-place traversal method.
The space complexity is O(1), indicating that the amount of memory used by the algorithm is not dependent on the size of the input tree.
Frequently Asked Questions
Which one to use Morris Postorder Traversal or Traditional Postorder?
In practice, the choice of traversal method often depends on the specific use case, the characteristics of the binary tree, and the developer's familiarity with the algorithm. Many developers prefer more straightforward and widely understood traversal methods for most practical purposes.
Is Morris Postorder Traversal commonly used in practice?
Morris Postorder Traversal is not as commonly used in practice as other traversal methods like Morris Inorder Traversal, recursive postorder traversal, or iterative postorder traversal using a stack. While it is a space-efficient algorithm, it has some complexities and limitations that can make it less practical for many real-world scenarios.
Are there any limitations to Morris Postorder Traversal?
Morris Postorder Traversal is more complex to implement compared to Morris Inorder Traversal. It involves multiple steps and can be error-prone, making it harder to understand and maintain.
Conclusion
To summarise the discussion, we have extensively discussed the Morris Traversal Postorder. We have started with discussing the types of traversals followed by the need of the Morris Traversal. As we have seen that it eliminates the need of stack in the algorithm which is an elegant approach and undoubtedly memory efficient. Yet, this amazing algorithm is lesser known in the market but plays a crucial role in Interviews.
We have more for you. Give a read to the following articles to learn more about Traversals:








































 6+ registered
6+ registered 

