


























Introduction
The demand for machine learning in the market is increasing day by day. It is becoming popular daily, so having good knowledge of machine learning algorithms is essential. Therefore, this blog will discuss multiclass and multioutput classification using scikit-learn.

In this article, we will cover the topic of multiclass, multilabel, and multioutput classification, and after that, we will also look at their implementations using scikit-learn. Now let us first look at what exactly multiclass classification is.
Multiclass Classification
As we all know, classification means categorizing data and forming groups based on similarities. In a particular dataset, the independent variables or features play an important role in classifying the data. A classification problem includes more than two classes, such as classifying a series of car brands based on photographs, where the car can be a Mercedes, BMW, or Toyota.
Multiclass classification assumes that each sample can be only assigned to only one class, i.e, a car be either a Mercedes or a BMW it cannot be both at the same time. In multiclass classification, we will train a classifier using our training data and then use this classifier to classify new examples.
Implementation of multiclass classification using scikit-learn
Now, we will use the KNN (K-nearest neighbors) classifier to solve this problem. KNN is one of the simplest classification algorithms of machine learning. Whenever new data set is encountered, its k-nearest neighbors from the training data are examined. The distance between two different datasets can be calculated by finding the Euclidean distance between their two feature vectors.
# importing required libraries such as sklearn for preparation of our model
from sklearn import datasets
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# we require iris dataset for our model and we are loading the dataset
iris_dataset = datasets.load_iris()
# X is defined as features
#y is defined as labels
X = iris_dataset.data
y = iris_dataset.target
# spliting X, y data into train data and test data
x_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
# training a KNN classifier by importing KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 7).fit(x_train, y_train)
# accuracy on X_test data
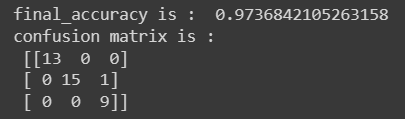
final_accuracy = knn.score(X_test, y_test)
print("final_accuracy is : ",final_accuracy)
# creating a confusion matrix for determining and visualizing the accuracy score
knn_predict = knn.predict(X_test)
confusion_matrix = confusion_matrix(y_test, knn_predict)
print("confusion matrix is : \n",confusion_matrix)
Output:




 9+ registered
9+ registered 

