Do you think IIT Guwahati certified course can help you in your career?
Introduction
Of course, we all know how a human brain works, right? The message is passed on with the help of neurons; after some electrical signals are passed, the brain takes the final decision.
Well, neurons do not just work in human brains; they are also responsible for the decision-making of a model in deep learning called perceptrons. Let us get an in-depth understanding of it.
What is Perceptron?
Biologically, neurons take some electrical signals, process them, and produce a result in electrical signals. The input and output are binary, i.e., 0 and 1.
Similarly, in neural networks, the perceptron is the building block of the network and acts as an artificial neuron to behave like a human brain. It performs binary classification, and it is the task of a perceptron to understand whether a function is input and classify them in either of the classes.
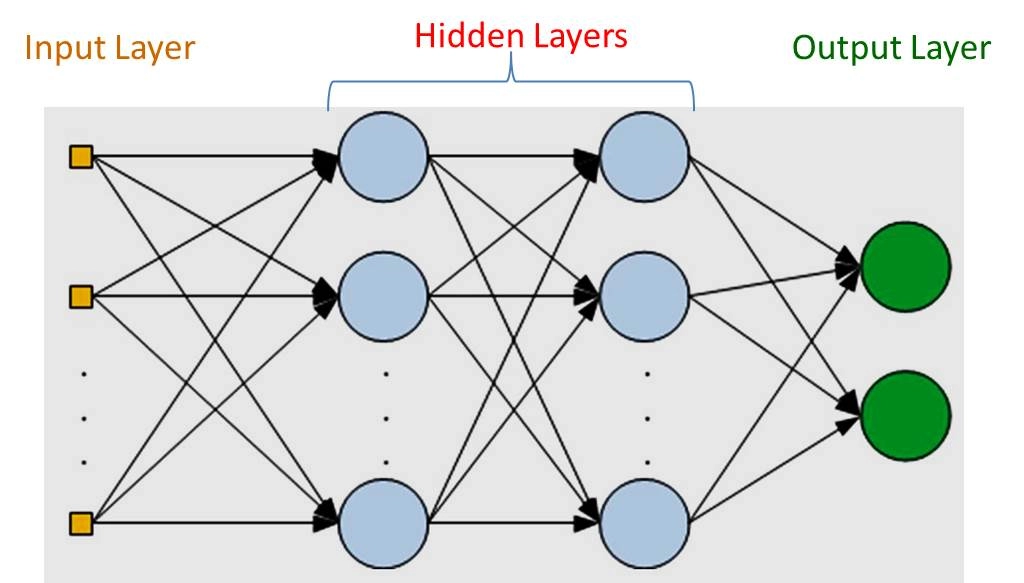
In the above image, X1 and X2 are the input values, and Ө1 and Ө2 are the weights. The value is passed through the perceptron/ neuron to give the desired output y.
A perceptron is known to be a linear classifier that classifies the input by separating it into two categories with a straight line.
The Multilayer perceptron consists of more than one perceptron layer. It consists of an input layer to receive the signal, an output layer that makes the decision, and the hidden layers, in between are responsible for decision-making. The MLP is also known as a feed-forward neural network.
MLP trains on a set of input and output pairs and learns to model the dependencies between them. To minimize the errors, adjustments of parameters, wights, or bias are made during the model's training time.
Training the model
There are three steps involved in training an MLP model, namely:
Forward pass
Calculate errors
Backward pass
Let us understand the training of a multilayer perceptron model with an example of XOR.
The truth table of XOR gate is:
X1
X2
Output
0
0
0
0
1
1
1
0
1
1
1
0
1. Forward pass
This is the first step of training the model. This step passes the input given at every perceptron and calculates the output by y=w*x+b.
There are two inputs in the XOR logic gate, i.e., X1 and X2. A single hidden layer with two neurons requires two decision planes and one output node. Hence, the neural network will look like this:
Now, we will apply the Sigmoid function, which acts as an activation function and decides which value to pass further. The mathematical representation is as follows:
y=11+e-(wixi+b)
Where wixi+b is known as the activation function.
This completes our first step, i.e., the forward pass; now, we will calculate the errors.
2. Calculate the errors
After we have calculated our predicted output, we will compare the predicted result with the actual or the expected output and calculate the errors and loss function we have to backpropagate.
The gradient of the sigmoid neuron is the squared error loss. We want to find the weight vector corresponding to the point where the error is minimum. Mathematically, it can be solved by the formula:
Error = 12(t-y)2
Where t is the target output, and y is the predicted output.
3. Backward pass
Now comes the essential step. After calculating the errors, we will backpropagate the loss and update the model's weight using the gradient. The weights will adjust according to the gradient flow. Multiple weights could contribute to the error; therefore, we will calculate the partial derivative concerning each importance; this could be written as:
Backpropagation will repeat this process until the predicted output is equivalent to the expected or target output. To get an in-depth knowledge of backpropagation, refer to this article.
What is a Multilayer perceptron used for? A multilayer perceptron is used for classification prediction problems where the data is labeled. It is also suitable for regression prediction problems.
Is multilayer perceptron fully connected? The multilayered perceptron is a fully connected hierarchical neural network.
What are the disadvantages of MLP? The multilayer perceptron consists of neurons that are interconnected in a deep network. Each node consists of tons of parameters, which results in redundancy and inefficiency.
Key takeaways
Multilayer perceptron consists of multiple layers of perceptrons responsible for making decisions. In this article, we got a piece of in-depth knowledge about perceptrons; we discussed what multilayer perceptrons are and how we train the MLP model with the help of the XOR gate example. Also, we examined its applications. If you are interested in knowing more, check out our industry-oriented deep learning course curated by our faculty from Stanford University and Industry experts.




































 9+ registered
9+ registered 

