Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
Whenever a transaction T is needed to access the database, a locking protocol locks the entire database. Now, if another transaction S happens simultaneously that requires accessing the data from the same database, it will not perform the transaction due to the locking of the entire database.
Locking the entire database is unnecessary and costs us the loss of concurrency. The concept of multiple granularity in DBMS talks about resolving this issue. Now let’s first understand granularity.
This article will help you understand Multiple Granularity in DBMS in depth.
So let us begin to understand this topic in depth.
What is Granularity?
Granularity in database management refers to the level of detail at which data is stored in a database. It specifies whether the data is fine- or coarse-grained. A fine granularity database stores data very detailedly, whereas a coarse granularity database stores data at a high-level overview. The application determines granularity needs as well as the size and complexity of the database. Selecting the appropriate granularity is critical for creating an efficient and productive database.
What is Multiple Granularity in DBMS?
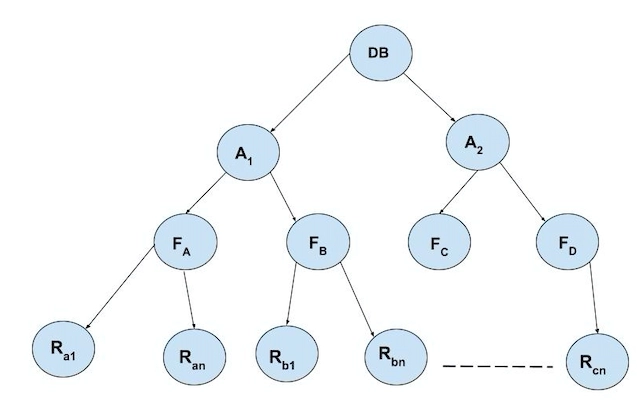
Multiple Granularity in DBMS refers to the ability of a database system to support various levels of data abstraction, allowing different users to view data at different levels of detail. It means hierarchically breaking up the database into blocks that can be locked. Multiple granularity increases concurrency and reduces the lock overhead. It makes it easy to decide which data should be locked and which is not. A tree can represent the hierarchy of multiple granularity.
For example: Consider a tree that has four levels of nodes.
The root level or the top-level represents the entire database.
The second level represents a node of the type area. The database consists of precisely these areas.
The area has children nodes known as files. Any file cannot be present in more than one area.
Each file has child nodes known as records. The file precisely consists of those records that are its child nodes. No records can be present in more than one file. Therefore, levels starting from the highest level are
Database
Area
File
Record
Explanation
Consider the above diagram, each node in the tree can be locked individually. According to the 2-phase locking protocol, it will use shared and exclusive locks.
When a transaction locks a node, it is either in shared or exclusive mode. The transaction implicitly locks descendants of that node in the same lock mode.
Locks on files and records are made simple, but the lock on the root is still not determined.
One way to know about a lock on the root is to search the entire tree. But it nullifies the whole concept of multiple granularity locking schemes.
A more efficient way to achieve this is by using a new type of lock called intention mode lock.
What are the Different Types of Intention Mode Locks in Multiple Granularity?
In addition to shared and exclusive lock modes, other three lock modes are available.
Intention-shared (IS): In the context of multiple granularity locks, the "Intention-shared (IS)" mode indicates an intention to acquire a shared lock at a higher level. It signals the desire to read or access shared resources in the higher-level structure while allowing other transactions to hold shared locks at lower levels.
Intention-Exclusive (IX): explicit lock with exclusive or shared locks at a lower level.
Shared & Intention-Exclusive (SIX): In this lock, the node is locked in shared mode, and some nodes are locked in exclusive mode by the same transaction.
S
X
IS
IX
IX
S
Yes
No
Yes
No
No
X
No
No
No
No
No
IS
Yes
No
Yes
Yes
No
SIX
No
No
Yes
No
No
IX
No
No
Yes
No
Yes
Intention lock modes are used in multiple-granularity locking protocol uses to ensure serializability. In this protocol, if a transaction T that attempts to lock a node need to follow these protocols:
Transaction Ti must follow the lock-compatibility matrix.
At first, Transaction Ti must lock the tree’s root in any mode.
Transaction Ti will lock a node in S or IS mode only if Ti has locked that node’s parent in either IS or IX mode.
Transaction Ti will lock a node in IX, SIX, or X mode only if Ti currently has the parent of the locked node in either SIX or IX modes.
Transaction Ti will lock a node only if Ti has not unlocked any node before (i.e., Ti is two-phase).
Transaction Ti will unlock a node only if Ti has not locked its children nodes currently.
Multiple granularity protocol requires that locks are made in a top-down (root-to-leaf) manner, whereas locks must be released in a bottom-up (leaf to-root) manner.
Consider the given tree in the figure and the transactions:
Assume transaction T1 reads record Ra2 from file Fa. Then, T2 will lock the database, area A1, and Fa in IS mode (and in that order), and finally, it will lock Ra2 in S mode.
Assume transaction T2 modifies record Ra9 from file Fa. Then, T2 will lock the database, area A1, and file Fa (in that order) in IX mode and lock Ra9 in X mode.
Assume transaction T3 reads all the records from file Fa. Then, T3 will lock the database and area A1 (and in that order) in IS mode and lock Fa in S mode.
Assume transaction T4 reads the entire database. It can be done after locking the database in S mode.
Transactions T1, T3, and T4 can access the database together. Transaction T2 can execute concurrently with T1 but not with T3 or T4.
Deadlock is also possible in the multiple-granularity protocol, as it is in the two-phase locking protocol. These can be eliminated by using specific deadlock elimination techniques.
Implementation of Multiple Granularity Locking
Multiple Granularity Locking (MGL) is a concurrency control mechanism used in database management systems to handle locks at various levels of granularity. It allows locking different levels of data, such as entire tables, rows, or even specific fields within a row, to improve concurrency and reduce contention.
In MGL, locks can be acquired and released at different granularities depending on the operations being performed. For example, a transaction may require a shared lock on an entire table for reading, but a more restrictive exclusive lock on a specific row for updating. Implementing MGL involves managing a hierarchy of locks and ensuring compatibility between locks acquired by different transactions to prevent deadlocks.
Use Cases of Multiple Granularity Locking
Data Integrity: MGL ensures data integrity by allowing transactions to acquire locks at different granularities based on their needs. For example, a transaction may need to lock an entire table to perform bulk updates while preventing other transactions from modifying individual rows concurrently.
Concurrency Control: MGL improves concurrency by allowing transactions to acquire locks at varying levels of granularity. This allows multiple transactions to access and modify different parts of the database simultaneously without causing conflicts or contention.
Optimistic Concurrency Control: MGL can be used in optimistic concurrency control strategies, where transactions are allowed to proceed without acquiring locks initially. Before committing, the transaction checks for conflicts with other transactions and resolves them if necessary by acquiring appropriate locks. This approach reduces lock contention and improves throughput in systems with low update rates and high contention.
Partitioned Data: In distributed databases or systems with partitioned data, MGL allows transactions to acquire locks at different levels of granularity within each partition. This enables efficient access and modification of partitioned data while ensuring data consistency and integrity across partitions.
Frequently Asked Questions
Under what circumstances is Multiple Granularity used?
Multiple granularity is used to cater to different data analysis needs, optimize performance, and provide varying levels of detail in reporting, resource allocation, forecasting, and data privacy requirements.
What is multiple levels of granularity?
Multiple levels of granularity refer to the ability of a system or structure to operate and provide information at various levels of detail or abstraction, catering to different perspectives or needs.
What are the different levels of lock granularity?
The different levels of lock granularity include database-level locks, table-level locks, page-level locks, row-level locks, and field-level locks.
What is true about multiple granularity?
Multiple granularity allows acquiring locks at various levels, facilitating efficient concurrency control and reducing contention in database systems.
What are the lock modes used in Multiple Granularity?
In multiple granularity scenarios, the lock modes used are Shared Lock (S-lock) for reading and Exclusive Lock (X-lock) for writing to maintain data consistency during concurrent access.
Which lock granularity has the highest overhead?
Fine-grained lock granularity (e.g., row-level locking) typically has the highest overhead due to managing and tracking a more significant number of individual locks.
Conclusion
In this article, we learned about granularity and multiple granularity in dbms. We have also known how multiple granularity locking affects concurrency performances.
We discussed new locking modes to address multiple granularity locking.
Visit here to learn more about different topics related to database and management systems. Ninjas don’t stop here. Check out the Top 100 SQL Problems to master frequently asked questions in big companies and land your dream job. You can also consider our Database Management Course to give your career an edge over others.































 6+ registered
6+ registered 

