Do you think IIT Guwahati certified course can help you in your career?
Introduction
Music can be defined as an arrangement of sounds combined in such a way as to produce beauty of form, harmony, and expression of emotions. It is an intangible part of our life that affects all of us in some form or another.
“Music is the strongest form of magic.” - Marilyn Manson
Let us explore this magic through deep learning. Deep Learning has changed our lives in many ways. Driverless cars, AI assistants, and many more tasks that were previously thought impossible were made possible because of deep learning. Deep learning can be used to create a sequence of nodes entangled with each other to create music.
Deep learning models can take a sequence of musical notes as input and predict the next note. We process the musical notes in a way that the computer can process. The input to the model is a series of musical notes on which our model can train. LSTMs and RNNs have proved to be helpful in music generation because of their ability to handle sequential data. We will look at how we can use LSTM to create music.
LSTM and RNN
RNN
RNN uses the output from the previous step and the current input to get the output. It has an internal memory that saves all the inputs. It uses the same functions on all the inputs and is hence called ‘recurrent’.
When we want to generate music, we consider the previous notes. As RNN process the previous inputs, it performs well on our musical notes input.
But due to this repeated calculation on all the inputs, the problem of ‘vanishing gradient’ or ‘exploding gradient’ arises. It fails to handle “long-term dependencies” as the inputs stored a long time ago can vanish and become useless. To overcome this problem, we use LSTM.
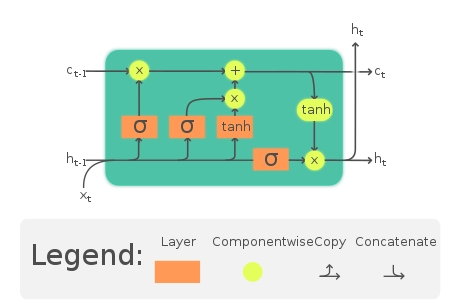
LSTM
LSTM is a modified RNN. It stands for Long Short Term Memory. RNN has a single layer of tanh, while LSTM has three sigmoid gates and one tanh layer. The gates in LSTM decide the information to be sent to the next layer and the information that is to be rejected. The gates allow the gradients to flow unchanged without any calculation, solving the problem.
To generate music, we need to predict the subsequent notes. Since the notes are related to the previous notes, we can use LSTM. LSTM can predict the following note and the time of that note, essentially generating music. To predict the notes, we need to train the model on some musical data to predict the notes. The musical data can be represented by the MIDI file format. After training the LSTM, it can be used to create new musical sequences.
Understanding the data
Musical data representation
Representing musical data for the training input is a challenging task. We can use a Musical Instrument Digital Interface (MIDI) file. It does not contain the actual musical data but the musical instructions that command a musical application to play accordingly. MIDI file is commonly used, and a large number of datasets are available.
How a musical note is determined
The musical note can be determined by the pitch, octave, and offset of that note.
Pitch
It is the frequency of the sound. It determines how high or low the sound of a particular note is.
Octave
An octave is a musical interval. It is the distance between two notes where the frequency of one note is twice that of the other.
Offset
Offset is the location of the note in a musical piece.
Chord
A chord is a set of notes that are played simultaneously.
MIDI file contains all of the above information about the notes. This information is used to train the model and predict the pitch, octave, and offset of the next note.
Encoding the information
The information in the MIDI file is generally string-based categorical data. However, neural networks perform better when the information is in integer form. We can use encoding to change the categorical string-based data into an integral form. It is basically a mapping function that maps the string-based categories into integers. An example of this transformation can be seen below.
With these inputs, the LSTM can learn about the mapping and correlation between notes and their projection.
LSTM architecture
After understanding our data, we can jump to our LSTM model. A typical LSTM model consists of four layers:
LSTM layers
The input to these layers is a sequence of notes. It is seen that two LSTM layers are sufficient to work on complex features. The number of layers can also be increased, but it will make our model harder to train.
This is how we can add an LSTM layer to our model:
model = Sequential().
model.add(LSTM(256,return_sequences=True,input_shape=(data.shape[1],data.shape[2])))
The first parameter in the LSTM() determines the number of nodes in the layer. Hence 256 means that there are 256 nodes. ‘input_shape’ tells our network about the shape of our input.
Lstm layers
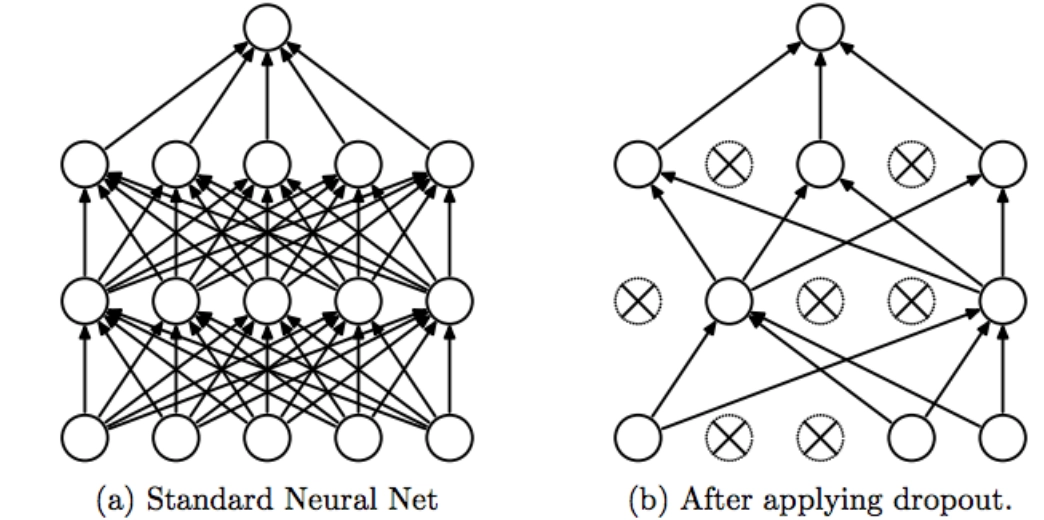
Dropout layers
It is a common regularization technique used to tackle overfitting. It sets some parts of our input to zero.
The dropout layers can be added as:
model.add(Dropout(0.1))
Here, 0.1 means 10 percent of the total neurons are dropped from our model.
Activation functions are used to determine the output of a node. The activation layer is used to set the activation function to be used in our network.
model.add(Activation('softmax'))
Here we can use the ‘Softmax activation function’ to determine the output. Softmax is used when there is a multinomial probability distribution.
'model_Input’ and ‘model_output’ are the inputs to our model and their corresponding outputs. ‘Epochs’ are the number of iterations we want to train, and ‘batch_size’ determines the number of samples we want to iterate in each epoch.
Generating music from the trained model
After training, the model is ready to generate a new sequence of musical notes. We should use a large and varied dataset to ensure better predictions.
We can start from any sequence of notes and set the next number of notes that we want to predict.
We can get the predictions of the next note and extract the note with the highest probability and add it to our sequence. The sequence created is then used to determine the next note. We can see below the probability of ‘D’ is highest, so we put it in our sequence.
Pros and Cons of LSTM
Frequently Asked Questions
Can we use some other deep learning algorithms to generate music?
Yes, CNNs such as WaveNet can also generate music with great success.
What are some other uses of LSTM?
LSTM can be used whenever our input is sequential. Some common examples are speech recognition and translators.
Should we always use two LSTM layers?
There is no fixed number of layers that can be specified to any network. It depends on our data and what we want to achieve from it. We can try a different number of layers to
Conclusion
This article looked into a creative use-case of deep learning - Music generation. We learned about LSTM and looked into how it handles sequential data. We understood how musical notes could be represented using MIDI files. We also talked about a simple LSTM architecture that can generate music. There are a lot more amazing applications of deep learning. To know more, check out our machine learning course at coding ninjas.






































 9+ registered
9+ registered 

