Working
The working of the Naive Bayes Algorithm is based on some of the fundamental assumptions:
- Independent: We assume that no two attributes are mutually exclusive. In simple words, no two features are dependent on each other.
-
Equal: Each component has the same level of importance. None of the features are irrelevant, and they are all expected to play a similar role in the outcome.
The working of the Naive Bayes Algorithm comprises the following steps:
Step 1: Conversion of the given Datasets into frequency tables.
Step 2: Creation of a Likelihood table by finding the probabilities of a given dataset.
Step 3: Finally, the posterior probability for each class is calculated using the Bayesian equation.
The outcome of prediction is the class with the highest posterior probability.
Implementation
A given dataset contains a list of 1000 students enrolled in three different courses in Coding Ninjas, namely Data Analytics Course, Web Development, and Android Development.
These are three possible A variables. We have data for the B variables depending on the skills and study tools for variable A. These are SQL, Node.js, and Kotlin, all of which are binary(0 or 1).
The dataset's first few rows look like this:
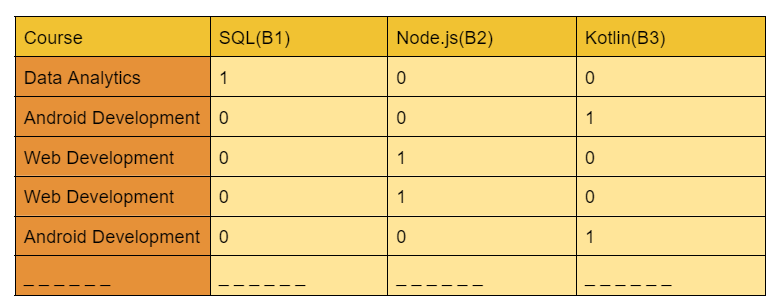
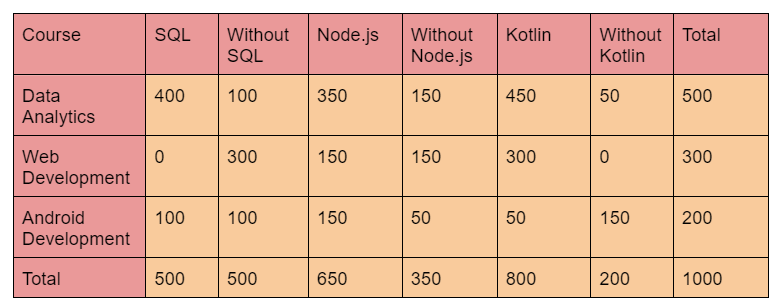
Let's aggregate the above data into a counts table below to determine the probability.
The classifier's goal is to predict the outcome for the given courses when three skills are known.
Let's try to solve it manually with Naive Bayes. The goal is to calculate the three probabilities: the course's possibilities in data analytics, web development, or Android development. Whichever course type with the most significant likelihood of winning is the winner.
Step 1: For each class of courses, compute the 'Prior' probability.
That is the percentage of each course class in the total number of courses in the population.
We can use Prior information on the people to provide the 'Priors.' Otherwise, it can be calculated using the first data set.
The above table contains all of the information needed to compute these probabilities.
For this case, let’s compute from the given dataset. Out of 1000 records in training data, you have 500 for Data Analytics, 300 for Web Development, and 200 for Android Development.
So the respective priors are 0.5, 0.3, and 0.2. P(A= D.A) = 500 / 1000 = 0.50 P(A = W.D) = 300 / 1000 = 0.30 P(A=A.D) = 200 / 1000 = 0.20.
Step 2: Calculate the probability of each piece of evidence in the denominator.
For all B, this is nothing more than the product of P of Bs. Because the denominator is the same for all classes, this is an optional step that will not affect the probability.
P(B1=SQL) = 500 / 1000 = 0.50 P(B2=Node.js) = 650 / 1000 = 0.65 P(B3=Kotlin) = 800 / 1000 = 0.80.
Step 3: Calculate the numerator's probability of likelihood of the evidence.
It's the product of the three features' conditional probabilities. If you look at the formula again, it states P(B1| A=k).
B1 stands for 'SQL,' while k stands for 'Data Analytics.'
Given that it is a Data Analytics course, this suggests the likelihood that the course is 'SQL.' We have 500 Data Analytics in the table above. A total of 400 of them have SQL as a feature.
Here, I have done it for Data Analytics alone.
Probability of Likelihood for Data Analytics :
P(B1|A) = 400 / 500 = 0.80
P(B2|A) = 350 / 500 = 0.70
P(B3|A) = 450 / 500 = 0.90.
So, the overall probability of Likelihood of evidence for Data Analytics = 0.8 * 0.7 * 0.9 = 0.504.
Step 4: To get the probability, input all three equations into the Naive Bayes formula.
Let’s find out the probability for the Data Analytics course when the skill given is SQL:
P(A1 |B1, B2, and B3)
= {P(B1|D.A)* P(B2| D.A) * P(B3| D.A)* P(A1)} / {P(B1) * P(B2)* P(B3)}.
=( 0.8* 0.7* 0.9* 0.5) / P(evidence).
=(0.252) / P(evidence).
P(A2 |B1, B2, and B3) = 0, because P(B1|A2) = 0.
P(A3 |B1, B2, and B3) = (0.01875) / P(evidence).
The Probability of Data Analytics course is the highest, so the course with SQL is Data Analytics.
Pros and Cons
Pros: The advantages of the Naive Bayes Algorithm are as follows,
- Naive Bayes is a fast and simple machine learning technique
- It works for both binary and multi-class classifications.
- It is the most often used method for text classification.
-
In comparison to numerical input variables, it performs well with categorical input variables (s).
Cons: The disadvantages of the Naive Bayes Algorithm are as follows,
- The assumption of independent predictors is a drawback of Naive Bayes.
- Because Naive Bayes implies that all features are independent, it is unable to learn the relationship between them.
Applications
- One can use this technique to make real-time forecasts because it is fast and efficient.
- For multi-class predictions, this approach is widely used. Using this approach, we can quickly determine the probability of many target classes.
- This algorithm is fantastic at detecting spam.
- To create recommendation systems, Collaborative Filtering and the Naive Bayes algorithm work together.
Types
There are various types of this algorithm. Here are the most important:
Bernoulli Naive Bayes
The predictors are boolean variables in this case. So our only options are 'True' and 'False'. When the data follows a multivariate Bernoulli distribution, we use it.
Multinomial Naive Bayes
This algorithm is used to solve document classification issues. For example, if you want to figure out whether a document falls in the 'Legal' or 'Human Resources' category, you can use this approach. The frequency of the current words is used as a characteristic.
Gaussian Naive Bayes
We assume the predictors are a sample from a Gaussian distribution if they aren't discrete but have a continuous value.
Frequently Asked Questions
Is Naive Bayes Supervised or Unsupervised Algorithm?
Based on Bayes' theorem, naive Bayes methods are a collection of supervised learning algorithms.
Can Naive Bayes be used for Multiclass Classification?
The Naive Bayes algorithm is a classification algorithm that may be used to classify binary and multiclass data.
What is Gaussian Naive Bayes?
Gaussian Naive Bayes is a Naive Bayes variation that allows continuous data and follows the Gaussian normal distribution.
Can Naive Bayes be used for Regression?
Yes. It was designed for classification jobs, but we can also use it for Regression with a few modifications.
Can Naive Bayes be used for Clustering?
Naive Bayes is a mixture model used for classification or Clustering (or both). It depends on which labels for items are observed.
Conclusion
This article has discussed the Naive Bayes Algorithm, and the Key Concepts of the algorithm, such as the Bayes Theorem, Conditional Probability. We also discussed the Working, Implementation, Applications, and types of the Naive Bayes algorithm.
We hope this article helped you in increasing your knowledge of Data Mining. You can learn more about data mining by visiting this article on Data Mining. You can also enrol in Machine Learning Course.
Head over to our practice platform Coding Ninjas Studio to practise top problems, attempt mock tests, read interview experiences, interview bundle, follow guided paths for placement preparations, and much more!!
We wish you Good Luck! Keep coding and keep reading Ninja!!





























 8+ registered
8+ registered 

