Do you think IIT Guwahati certified course can help you in your career?
Introduction
Do you know a Graph has multiple applications, such as social networks and language modeling? Graphx is a graph processing framework that is used for analyzing and processing large graphs in a distributed manner in big data
Do you know how we can aggregate information in graph analytics about each vertex’s neighborhood? If not, then don't worry, in this article, we will understand about neighbourhood aggregation in GraphX, aggregating messages, collecting neighbors, and computing degrees in GraphX.
Moving forward, let's understand what is neighborhood aggregation in GraphX.
About GraphX
Using GraphX, we can analyze graph data structure and perform multiple operations and computations like traversing, running graph algorithms, performing graph analytics, and calculating graph metrics. GraphX can process large-scale graphs and is used in multiple tasks such as social network analysis, bioinformatics, recommendation systems, collecting information about neighborhood vertex, etc.
Before moving on to topics such as ‘neighbourhood aggregation in GraphX’, one must have a basic understanding of graph data structure and its fundamentals, graph algorithms, programming, and data processing, knowledge of computing frameworks such as Apache Spark, graph algorithms involving linear algebra and matrix operations and Pregel computation model that is used in large scale graph processing. It helps developers to solve custom problems by plugging in some logic.
Moving forward, let's understand what is neighbourhood aggregation in GraphX.
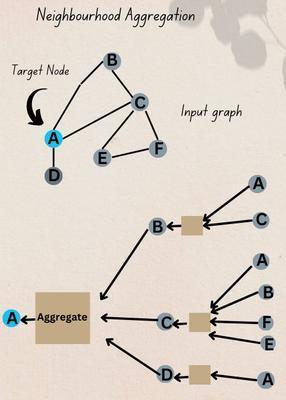
What is Neighbourhood Aggregation in GraphX?
Gathering information about the neighbourhood of each vertex is known as neighbourhood aggregation in GraphX. GraphX is a framework built on top of Apache Spark for doing computations related to graphs.
In a graph, the neighbourhood of a vertex refers to an immediate set of vertices directly connected by edges. In Neighbourhood aggregation, we propagate the graph and collect information among the neighbourhood of a vertex in a graph.
Iterative algorithms, such as PageRank, Shortest Age, and connected components, etc., are used repeatedly for aggregating the properties of the vertices in the neighbourhood.
Neighbourhood aggregation uses a message-passing mechanism as a key mechanism, in which information exchange occurs, usually by sending specific messages to their neighbors.
For implementing neighbourhood aggregation in GraphX, we use the ‘aggregateMessages’ operator. The ‘aggregateMessages’ operator improves the performance by aggregating the information of the vertices and eliminating the need for mapping, thus reducing steps and providing a streamlined approach for implementing message passing.
Aggregating Messages in GraphX
As we have discussed above that aggregateMessages is a core aggregation operation provided by GraphX that uses two methods, one for sending a message to each edge triplet (sendMessage) and another method for merging the message at the destination vertex (mergeMessage).
For example, We may consider neighbourhood aggregation as groups of students sitting in a particular pattern and communicating by passing a note. Each student adds their contribution by writing the information to the note, and the note returns to one student who can aggregate the information from all the students. Here students can be considered a vertex, and the mechanism can be stated as message passing.
The general syntax for defining our own ‘sendMessage’ and ‘mergeMessage’ is mentioned below:
val aggregatedNinjaGraph=graph.aggregrateMessage[Message](
sendNinjaMessage=triplet=>{
// logic for sending a message
// returning the message that is to be sent
},
mergeNinjaMessage=(message1, message2){
// logic for merging the received messages
// returning the merged messages
}
)
In the above syntax, the ‘aggregateMesaages’ is an operator provided by GraphX for performing the specific neighbourhood operation. It accepts arguments: ‘sendNinjaMessage’ and ‘mergeNinjaMessage’.
‘Message’ refers to the type of message passed between the vertices of a graph while performing aggregation. It can be a string, integer, etc.
‘sendNinjaMessage’ refers to a user-defined argument function that defines logic for sending messages from a vertex to the neighbors by taking a ‘triplet’ object as input representing source, destination vertex, and edge information.
‘mergeMessageNinja’ is a user-defined argument function that contains logic for merging (aggregating) the received messages at each vertex.
The syntax varies according to the version one uses of GraphX and Spark.
Assume a class ‘Graph[VertexType, EdgeType]’ that represents a graph data structure. ‘VertexType’ refers to the type of vertex, and ‘EdgeType’ refers to the type of edge data. This class defines various methods for working with graph data structure, such as the ‘aggregateMessages’ method.
Below is the code snippet that depicts the same.
class Graph[VertexType, EdgeType] {
// function for aggregating the messages
def aggregateMessages[NinjaMessage: ClassTag](
// defining the method for sending the message
sendNinjaMessage: EdgeContext[VertexType, EdgeType, NinjaMessage] => Unit,
// defining the method for merging messages
mergeNinjaMessage: (NinjaMessage, NinjaMessage) => NinjaMessage,
tripletFields: TripletFields = TripletFields.All): VertexRDD[NinjaMessage]
}
In the above code, the ‘aggregateMessages’ is a method for aggregating the information, and ‘VertexRDD[NinjaMessage]’ is the return type.
‘ sendNinjaMessage’, ‘mergeNinjaMessage’, and ‘tripletFields’ are the three parameters. The tripletFields is an optional parameter where the default value is ‘TrippletFields.All’. It is used for specifying which triplet fields are to be accessible in the ‘sendNinjaMessage’ function.
‘tripletFields’ is a variable defined as a parameter in the ‘aggregateMessages’ method, whereas ‘TrippletFields’ is a pre-defined class provided by GraphX. The source vertex, destination vertex, and edge are usually referred to as triplets.
The source vertex is the vertex from which the directed edge originates.
The destination vertex is the vertex to which a directed edge points.
An edge represents the path, connection, or relationship between the source and destination vertex.
The collection of vertices is returned using ‘VertexRDD[NinjaMessage]’ where ‘VertexRDD’ is used for representing the vertices collection specific to the data, here it is representing the result of the neighbourhood aggregation where every vertex is related to computed messages that are of the type ‘NinjaMessage’.
Collecting Neighbours and Computing Degree in GraphX
Computing Degree
GraphOps is a class consisting of operators for computing degrees of each vertex. Computing the degree of each vertex is a widely used aggregation task. In the case of directed graphs, we must know each vertex's in-degree, out-degree, and total degrees. The degree of each vertex is referred to as the number of edges adjacent to each vertex. Let's say we want to make a program for computing the highest degree vertex. To do this, we can perform the following steps:
Defining a user-defined function, ‘NinjaMax’, for comparing and selecting the highest degree vertex. It accepts two tuples of ‘(VertexId, Int)’. The function returns the tuple that has the highest degree.
We can use the pre-defined ‘inDegrees’ method to compute the maximum in-degree and call it on the ‘graph’ object. This will return the vertices with their respective in-degrees.
The ‘reduce’ operation is used for reducing the collection of vertices with their in-degrees using the ‘NinjaMax’ function. Therefore we will get the vertex with the maximum in-degree in the form of a tuple ‘(VertexId, Int),’ and store it in the variable ‘NinjaMaxInDegree’.
Similarly, we can compute the maximum out-degree and overall degree.
The ‘reduce’ operation reduces elements to a single value based on a particular function.
The code snippet below demonstrates the above explanation.
// For reducing the collection on vertices with their in-degrees by defining the ‘NinjaMax’ function
def NinjaMax(NinjaVar1: (VertexId, Int), NinjaVar2: (VertexId, Int)): (VertexId, Int) = {
if (NinjaVar1._2 > NinjaVar2._2) NinjaVar1 else NinjaVar2
}
// For returning maximum in-degree.
val NinjaMaxInDegree: (VertexId, Int)= graph.inDegrees.reduce(NinjaMax)
// For returning maximum out-degree.
val NinjaMaxOutDegree: (VertexId, Int)= graph.outDegrees.reduce(NinjaMax)
// For returning maximum overall degree.
val NinjaMaxDegrees: (VertexId, Int)= graph.degrees.reduce(NinjaMax)
In the above code snippet, ‘reduce’, ‘inDegrees’, and ‘outDegrees’ are the pre-defined functions.
‘(VertexId, Int)’ is the user-defined tuple type used for representing a vertex's ID with its corresponding degree. Therefore the tuple here is storing the vertexID and the value of the degree.
Collecting Neighbors
Collecting neighbours refers to accessing the adjacent vertices of the provided vertex of the graph. Graph algorithms usually use this operation for analyzing the local connectivity and relationship of the vertices in a given graph.
For implementing this, we can use collectNeighborIds and the collectNeigbors operator provided by the ‘Graph’ class to aggregate the neighboring vertices and edge data associated with each graph vertex.
Below is a sample command for collecting neighbors:
val NeighboursCollected=graph.collectNeighbors( edgeDirection: EdgeDirection)
Below is how collectNeighborIds and collectNeigbors are defined in the graph class.
class GraphOps[VD, ED] {
// method for collecting neighbor IDs
def collectNeighborIds(NinjaEdgeDirection: EdgeDirection): VertexRDD[Array[VertexId]]
// method for collecting neighbor
def collectNeighbors(NinjaEdgeDirection: EdgeDirection): VertexRDD[ Array[(VertexId, VD)]]
}
In the code above, the class ‘GraphOps[VD, ED]’ consists of two user-defined methods collectNeighborIds and collectNeighbors.
In the collectNeighborIds and collectNeighbors functions, the logic is defined for collecting neighboring vertex IDs and their corresponding attribute values of each vertex.
Frequently Asked Questions
What is Neighbourhood Aggregation in GraphX?
Gathering information about the neighbourhood of each vertex is known as neighbourhood aggregation in GraphX. A graph's neighbourhood of a vertex refers to an immediate set of vertices directly connected by edges. In Neighbourhood aggregation, we propagate the graph and collect information among the neighbourhood of a vertex in a graph.
What are aggregating messages in GraphX?
The aggregateMessages is a core aggregation operation provided by GraphX that uses two methods, one for sending a message (sendMessage) and another method for merging the message at the destination vertex (mergeMessage).
What is GraphX?
GraphX is a graph processing framework provided by Spark, using which we can analyze graph data structure and perform multiple operations and computations like traversing, running graph algorithms, performing graph analytics, and calculating graph metrics.
How can we compute degree in GraphX?
GraphOps is a class consisting of operators for computing the degree of each vertex. The number of edges adjacent to each vertex is called the degree of each vertex. Computing the degree of each vertex is a common aggregation task. In the case of directed graphs, we must know each vertex's in-degree, out-degree, and total degrees.
What are Graph Operators?
Basic filtering and mapping functions can be applied to collections of edges and vertices using GraphX.Also, custom functions can be defined, which can be used in a similar way as built-in operations in GraphX.
Conclusion
In this article, we have discussed about neighbourhood aggregation in GraphX, aggregating messages, collecting neighbors, and computing degrees in GraphX. Therefore GraphX is a very important graph processing framework with a variety of uses, such as social network analysis, graph-based machine algorithms, community detection, etc. You can also refer to our other articles to learn more about Spark and its subtopics:
You can read more such articles on our platform, Coding Ninjas Studio.You will find straightforward explanations of almost every topic on this platform. So take your coding journey to the next level using Coding Ninjas.






























 8+ registered
8+ registered 

