


























Introduction
Welcome back, Ninja! We hope you all are doing well. Predicting the next use of a variable's value is crucial for writing effective code. A register can be assigned to another variable if the value of a variable that is now stored there won't ever be used again.

The fundamental ideas of flow graphs and next-use information are covered in this article. The produced code's effectiveness, functionality, and security can all be enhanced by incorporating next-use information into compiler design.
Basic Blocks and Flow Graphs
An instruction block with exactly one entry point and one exit point is called a basic block. If branch instructions are considered, there may be multiple exit points. A control flow graph (CFG) is a directed graph with basic blocks. Bi as its vertices and edges Bi->Bj if and only if Bj is capable of being performed right after Bi.
The scanner and parser of the compiler provide an intermediate representation of the source code during the front-end phase of compilation, which frequently takes the shape of a control flow graph. The control flow graph depicts the program's control flow by breaking it down into fundamental building parts and showing the control flow between them.
An example of a flow graph for the vector dot product is given as follows:
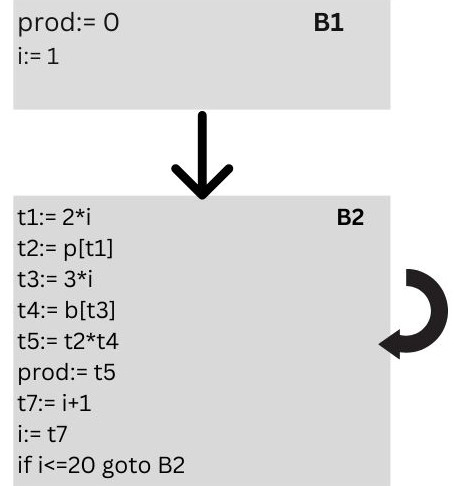
The initial node is B1. There is an edge from B1 to B2 because B2 comes after B1 immediately. There is an edge from B1 (final statement) to B2 (first statement), as the objective of the jump from B1's last statement is B2's first statement. B1 is the predecessor of B2, while B2 is a successor of B1.
Loops
A flow graph comprises fundamental building components that indicate the control flow direction. This flow graph can occasionally create a loop that circles back around to the fundamental building elements. A loop is made from building blocks so that;
-
The collection's blocks are all strongly related. A tightly connected loop is one in which there is a path of length one or more from each node to any other node inside the loop.
-
The collection of blocks has a singular entry, and using this entry is the only way to access a block in the loop.
Inner loops are loops that do not contain any other loops. An outside loop is a loop that has one or more inside loops.
Structure-Preserving Transformation
-
Elimination of Frequently Used Sub-Expressions: If a specific expression appears multiple times in a block, it is considered common. This could be eliminated to avoid unnecessary computation. For example, consider the given set of statements:
a:=b+c
b:=a-d
c:=b+c
d:=a-d
In the above example, the second and fourth expressions compute the same expression, so the basic block can be transformed by replacing the (a-d) with b. So the set of set statements can be represented as:
a:=b+c
b:=a-d
c:=b+c
d:=b
-
Removal of dead code: An instruction is considered dead in a basic block if a specific variable or assignment isn't going to be used. Assume that x is dead, or never used again, at the time the fundamental block phrase x: = y + z appears. The basic block's value can then be safely left unchanged by removing this sentence.
-
Temporary variable renaming: Temporary variables are defined to translate instructions into three-address codes. To efficiently optimize the finished code, these variables are renamed. For example, the statement a:=p+q can be changed to b:=p+q where b is the new temporary variable.
-
Changing two separate, neighboring statements: An optimized code is produced by rearranging the instructions, and this transformation enables the swapping of two adjacent independent statements. As an example, let's suppose a block has the two adjacent sentences given below:
P1 : = b + c
P2 : = x + y
We can swap the two lines without changing the value if and only if neither x nor y is P1 and neither b nor c is P2.


 8+ registered
8+ registered 

