


























Introduction to Natural Language Processing (NLP)
The study of how computers interact with human language is called natural language processing (NLP), and it focuses on how to build computers that can process and analyze enormous volumes of natural language data. Examples of natural language processing include Siri speech recognition from Apple and Google Assistant from Google.

NLP combines statistical, machine learning, and deep learning models with computational linguistics or rule-based human language modeling. When these technologies are combined, computers are able to interpret human language in the form of text or audio data and fully "understand" its meaning, including the writer's or speaker's purpose and mood. Computer programs that translate text between languages reply to spoken commands, and instantly summarise massive volumes of information even in real-time are all powered by NLP. NLP is, however, rapidly being used in commercial solutions to assist organizations in streamlining operations, enhancing staff productivity, and streamlining crucial business procedures. Furthermore, we will be covering NLP Interview Questions that are frequently asked.
Basic Level NLP Interview Questions for Fresher
1. What are the areas of NLP?
NLP can be used in the following areas:
- Semantic analysis
- Automatic synthesis
- Text categorization
- Answering inquiries
- Language modeling
- Topic modeling
- Information Extraction
The Google Assistant, Amazon Echo, and IOS Siri are some examples of NLP in action.
2. What is ambiguity in NLP?
Ambiguity is a state where a word might be misconstrued due to its ability to have several meanings. Because natural languages are ambiguous, applying NLP techniques to them can be challenging and provide incorrect results.
3. How to find word similarity in NLP?
When determining word similarity in NLP, the word vectors of the words are computed in the vector space, and the similarity is then determined on a scale from 0 to 1.
4. What is NLTK?
Natural Language Toolkit, a Python library, is the abbreviation for this. To process data in human-spoken languages, we employ NLTK. We may use NLTK to comprehend natural languages by using methods like parsing, lemmatization, tokenization, stemming, and more. It aids in text classification, linguistic structure parsing, document analysis, etc.
5. What is the difference between NLTK and openNLP?
NTLK and openNLP differ slightly in that NLTK is developed in Python, whereas openNLP is based on Java. Another distinction is that NTLK offers the option of downloading corpora via an integrated technique.
6. List some components of NLP.
The few main NLP components are listed below.
- Entity extraction: It is the process of segmenting a phrase to find and extract entities, such as actual or made-up people, organizations, places, things that happened, etc.
- Syntactic analysis: This is the study of how words are placed in sentences.
- Pragmatic analysis: The process of obtaining information from text includes pragmatic analysis.
7. What is flexible string matching?
Finding strings that are likely to match a particular pattern can be done using flexible string matching, also known as fuzzy string matching. The approximation used to identify patterns between strings is also known as approximate string matching.
8. What is text-generation, and when is it done?
The technique of autonomously producing natural language texts in response to communication is known as text-generation. To accomplish this job, it makes use of computational linguistic expertise and artificial intelligence.
9. What is the meaning of N-gram in NLP?
Natural language processing and text mining frequently employ text N-grams. They are simply a group of words that frequently appear together in a frame, and when calculating the n-grams, you typically advance one word (although you can move X words forward in more advanced scenarios).
10. What is parsing in the context of NLP?
Finding the grammatical structure of sentences, such as which words belong together (as "phrases") and which words are the subject or object of a verb, is the process of parsing a text. Probabilistic parsers attempt to generate the most likely analysis of incoming phrases by using linguistic information gleaned from manually parsed sentences.
11. What is Named Entity Recognition(NER)?
A technique for categorizing a sentence is named entity recognition.
The 1969 lunar landing by US astronaut Neil Armstong will be classified as
Name: Neil Armstong; nation: The US; year: 1969 (temporal token).
The goal of NER is to provide the computer with the ability to extract entities such as persons, places, items, locations, money amounts, and more.
12. What are some popular Python libraries used for NLP?
Stanford's CoreNLP, NLTK, SpaCy, and TextBlob.
There is much to learn about NLP. A transformer network is preferred over a CNN or RNN in innovations like Google's BERT. Each word is examined and given attention evaluations (weights) by a Transformer network's self-attention mechanism. Homonyms, for instance, will score better because of their ambiguity. After that, a weighted average is created using these weights, which depict the same word in many ways.

13. Explain the Masked Language Model?
The method of extracting the output from the faulty input is known as "masked language modeling." With the use of this model, students can grasp deep representations in subsequent tasks. Using this technique, you may anticipate a word based on the other words in a phrase.
14. What is perplexity in NLP?
Given that the term "perplexed" implies "puzzled" or "confused", perplexity often refers to the inability to deal with a situation that is difficult to define. Perplexity in NLP is a means to assess the degree of ambiguity in text prediction.
Perplexity is a metric used in NLP to assess language models. Perplexity can range from high to low; excessive perplexity is horrible because it increases the likelihood of failing to handle a difficult issue. Low perplexity is moral since it reduces the likelihood of being unable to handle any complicated issues.
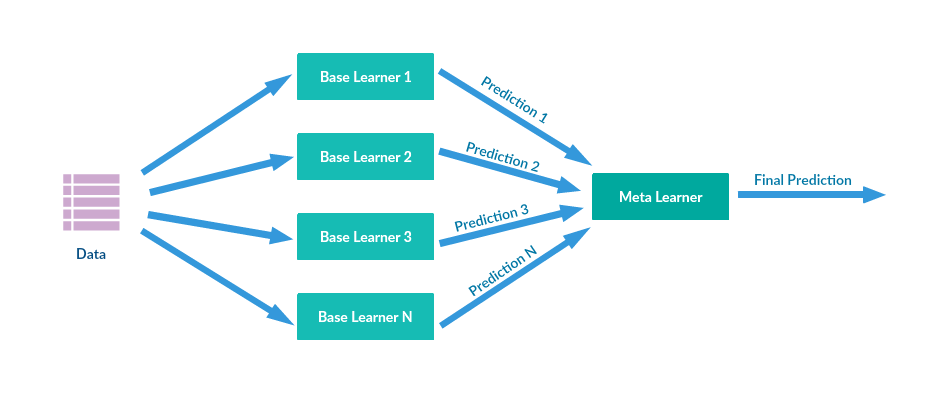
15. What is an ensemble method?
A type of machine learning method known as an ensemble approach combines many base models into a single most accurate predictive model. To achieve better outcomes, multi-model methods called ensemble techniques are applied. In most cases, ensemble approaches yield more accurate results than a single model.
16. What is the meaning of Pragmatic Analysis in NLP?
Pragmatic Analysis is concerned with outside word knowledge, which refers to information that is not contained in the documents and/or questions. A study of pragmatics that focuses on what was reported and reinterpreted by what it actually meant can be used to determine the numerous aspects of the language that call for practical knowledge.
17. What are the steps of text processing?
Text preparation steps may be categorized into three main categories:
- Tokenization: It is the process of breaking up a collection of texts into smaller units or tokens. Sentences are tokenized into paragraphs, and words are tokenized into sentences.
- Database normalization: It is the process of converting a database's structure into a number of normal forms. It organizes the data such that it looks consistent across all records and fields. Similar to this, normalization in the context of NLP might refer to the process of changing every word to lowercase. This simplifies the machine learning method while making all the phrases and tokens appear to be the same.
- Noise removal: It is the procedure used to tidy up the text. Eliminating characters such as white spaces, digits, special characters, and others that are not necessary.
18. What is the difference between lemmatization and stemming?

Stemming: It just takes off the final few letters of a word, which frequently results in inaccurate spellings and meanings. Eg. eating -> eat, Caring -> Car.
Lemmatization: It takes context into account and transforms the word into its lemma, or meaningful basic form. Eg. Stripes -> Strip (verb) -or- Stripe (noun), better -> good.
Also see, Amazon Hirepro


 9+ registered
9+ registered 

