What is Normalization?
The process of arranging the data in a database is known as Normalization. It is a scaling technique used to reduce redundancy in which the values are shifted and scaled in a range of 0 and 1. Normalization is used to remove the unwanted characteristics from the dataset, and it is useful when there are no outliers as it can not handle them. Mathematically, Normalisation is denoted as:

Source: Link
To know in-depth knowledge of Normalisation, visit this article.
Min-Max Scaling
Min-Max scaling, also known as normalization, is a data preprocessing technique commonly used in machine learning and statistical analysis to rescale features to a specific range, typically between 0 and 1. The goal of Min-Max scaling is to transform numerical features so that they have the same scale, preventing certain features from dominating others due to their original magnitude.
What is Standardisation?
Data standardization is a process in which the data is restructured in a uniform format. In statistics, standardization compares the variables by putting all the variables on the same scale. It is done by transforming the features by subtracting from the mean and dividing by the standard deviation. This process is also known as the Z-score. Mathematically, Standardisation is denoted as:
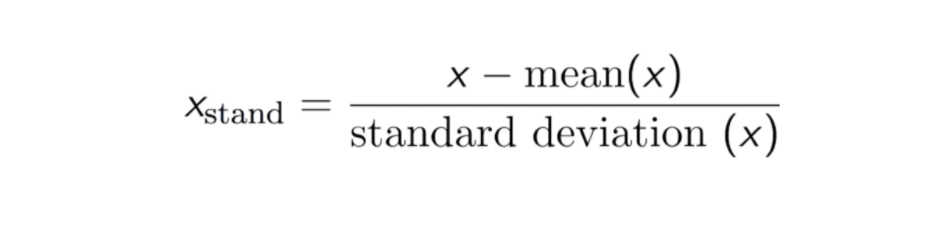
Source: Link
Formula of Standardization
Standardization, also known as z-score normalization, is a data preprocessing technique used to transform numerical features by rescaling them to have a mean of 0 and a standard deviation of 1. This process allows data to conform to a standard distribution, making it easier to compare and analyze different features.
The formula for standardization is as follows:
𝑋new=𝑋old−𝜇/𝜎
Where:
- 𝑋new is the standardized value.
- 𝑋old is the original value.
- 𝜇 is the mean of the feature.
- 𝜎 is the standard deviation of the feature.
Normalisation vs. Standardisation
Normalisation vs. standardisation is an ultimate doubt among machine learning beginners.
Normalisation is suitable to use when the data does not follow Gaussian Distribution principles. It can be used in algorithms that do not assume data distribution, such as K-Nearest Neighbors and Neural Networks.
On the other hand, standardisation is beneficial in cases where the dataset follows the Gaussian distribution. Unlike Normalization, Standardisation is not affected by the outliers in the dataset as it does not have any bounding range.
Applying Normalization or Standardisation depends on the problem and the machine learning algorithm. There are no definite rules as to when to use Normalization or Standardisation. One can fit the normalized or standardized dataset into the model and compare the two.
It is always advisable to first fit the scaler on the training data and then transform the testing data. This would prohibit data leakage during the model testing process, and the scaling of target values is generally not required.
Must read topic, IEnumerable vs IQueryable
Normalisation vs. Standardisation using sklearn library
Implementing Normalisation
#importing the Normalizer from sklearn
from sklearn.preprocessing import Normalizer
#Creating a sample data array
X = [[4, 1, 2, 2],[1, 3, 9, 3],[5, 7, 5, 1]]
transformer = Normalizer().fit(X) # fit does nothing.
transformer
Normalizer()
transformer.transform(X)
Output:

Implementing Standardisation
#importing the StandardScaler from sklearn
from sklearn.preprocessing import StandardScaler
#Creating a sample data array
data = [[0, 0], [0, 0], [1, 1], [1, 1]]
scaler = StandardScaler()
print(scaler.fit(data))
print(scaler.mean_)
print(scaler.transform(data))
print(scaler.transform([[2, 2]]))
Output:

In Normalisation, the change in values is that they are at a standard scale without distorting the differences in the values. Whereas, Standardisation assumes that the dataset is in Gaussian distribution and measures the variable at different scales, making all the variables equally contribute to the analysis.
When to use Normalization?
- When the distribution of data does not follow a normal distribution.
- When the magnitude of features varies widely, and you want to scale them to a specific range, such as [0, 1].
- When the algorithm you are using (e.g., neural networks with sigmoid or softmax activation functions) requires input features to be on a similar scale.
- When interpreting the magnitudes of features is important, and you want to preserve the original units of measurement.
- When dealing with distance-based algorithms like k-nearest neighbors (KNN) or clustering algorithms where the distance between data points matters.
When to use Standardization?
- When the distribution of data approximately follows a normal distribution.
- When comparing features with different units of measurement, as standardization makes the features comparable by removing the units.
- When using algorithms that assume features are normally distributed or have zero mean and unit variance, such as linear regression, logistic regression, and linear discriminant analysis (LDA).
- When dealing with principal component analysis (PCA), as standardization is a prerequisite for PCA to ensure that each feature contributes equally to the analysis.
- When outliers are present in the data, as standardization is robust to outliers since it is based on the mean and standard deviation.
Frequently Asked Questions
Should we normalize or standardize images?
If the image dataset is too small, then Standardisation is preferred because if we apply Normalisation, the dataset values will compress get decrease.
Does Normalisation changes the standard deviation?
Normalization reduces the values of standard deviation as the values are compressed; hence standard deviation is also shortened.
Does Normalisation affect variance?
After normalizing, the variance is decreased massively.
Conclusion
This article summarised the significant differences between normalisai\tiona and Standardisation, including the sklearn implementation of both. You can also consider our Online Coding Courses such as the Machine Learning Course to give your career an edge over others.































 6+ registered
6+ registered 

