Do you think IIT Guwahati certified course can help you in your career?
Introduction
In machine learning and data science, preparing data for algorithms is just as important as building the models themselves. One common data preprocessing technique is one-hot encoding, which is widely used to convert categorical data into a numerical format that models can understand. Categorical data—such as names of cities, product types, or user preferences—must be represented numerically for most machine learning algorithms. One-hot encoding achieves this by creating binary vectors, transforming categories into a format that retains their meaning without introducing unintended relationships. In this blog, we’ll dive into the mechanics of one-hot encoding, when to use it, and why it’s so essential for effective model training.
Why One Hot Encoding?
Categorical data encoding is an essential and unavoidable step in data preprocessing. There are various techniques for data encoding. One such technique is one-hot encoding. Let us take the gender feature example again. For every entry in the dataset, we have a gender associated with it, either ‘Male’ or ‘Female’ (assuming there are no empty values). These string values need to be converted to numerical values for our model to make use of the feature.
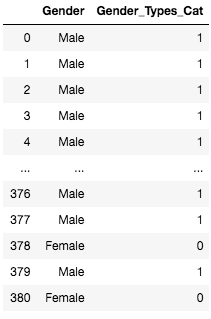
Let’s say we label encode the gender feature where ‘Male’ is assigned 1 and Female is assigned 0 as shown below.
Now, We may have converted string variables to corresponding machine-friendly numerals. But as humans we know, there is no specific order in this. That 1 for ‘Male’ is just a numeric representation of the string. However, while training, the machine may assign a higher weight to datapoints with Gender value as ‘1’ compared to those with ’0’. But genders themselves don’t have any hierarchical order whatsoever. Hence Label encoding isn’t the best way to categorically encode features that don’t have any specific order among themselves. It’s best to use One hot encoding in this case.
However, in case of ordered categorical features, Label encoding may make more sense. Suppose we have a dataset of athletes where we have ‘Pace’ as a feature with Categorical variables as ‘Low’ ,’ Medium’, and ‘High’.
In this case we might assign
Low : 0
Medium : 1
High : 2
Since the variables themselves have some order.
One-Hot Encoding
One hot encoding is a data encoding technique that creates a feature for every unique value in the column. These columns are called dummy variables. This will create both ‘Male’ and ‘Female’ columns for every entry in the dataset. So suppose for an entry we have the gender feature as ‘male’. This will enable the ‘Male’ column with 1 and the ‘Female’ column would still be 0.
Now let us consider a bit more complex example. Suppose we have a dataset of animals where we have a feature called ‘Species’. Let’s say our dataset has only 5 types of animal species namely ‘Dogs’, ‘Cats’, ‘Sheep’, ‘Horse’, and ‘Lion’. After one-hot encoding, our table will look like this -
We have 5 new dummy variables for every unique species of animal. This helps us efficiently categorize our features.
When to Use One-Hot Encoding?
When categorical data has no ordinal relationship (e.g., colors, product categories).
For machine learning models that require numerical input.
When there are a manageable number of categories, avoiding high-dimensional data.
How to Convert Categorical Data to Numerical Data?
To convert categorical data into a numerical format, several encoding techniques are available, with one-hot encoding being the most common. In one-hot encoding, each category in the data is transformed into a binary vector, where each category has its own column. A value of 1 in a column indicates the presence of that category, while 0 represents its absence. Another approach is label encoding, where categories are assigned integer values. However, this can introduce unintended ordinal relationships, making one-hot encoding a safer choice for non-ordinal data. With tools like Python’s pandas library, get_dummies() and LabelEncoder simplify this conversion, providing options to adapt categorical data for machine learning models effectively.
Implementation of one-hot encoding in python
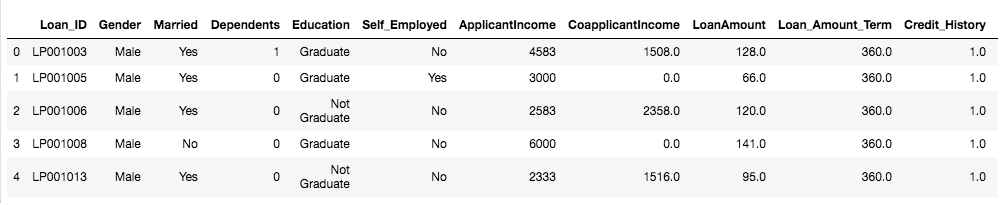
Let us implement one-hot encoding in python. You can find the dataset here.
There are 2 popular methods to implement one-hot encoding on categorical features using pandas as well as sklearn libraries. We will look at both these approaches.
one-hot encoding Using pandas
import pandas as pd
import numpy as np
data = pd.read_csv('clustering.csv')
data.head()
Using sklearn one hot encoder, we first label encode the categorical variables
from sklearn.preprocessing import LabelEncoder
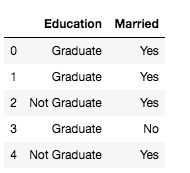
# creating initial dataframe
Ed_df = pd.DataFrame(X, columns=['Education'])
# creating instance of labelencoder
labelencoder = LabelEncoder()
# Assigning numerical values and storing in another column
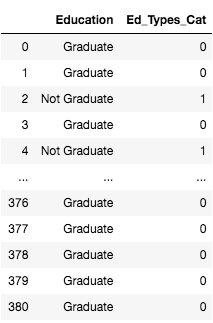
Ed_df['Ed_Types_Cat'] = labelencoder.fit_transform(Ed_df['Education'])
Ed_df
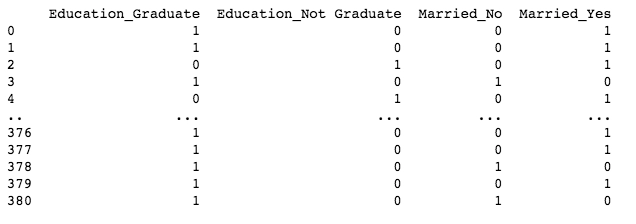
Here, since we have only 2 variables in the Education column, we generate 2 label encoded variables 0 and 1.
from sklearn.preprocessing import OneHotEncoder
# creating instance of one-hot-encoder
enc = OneHotEncoder(handle_unknown='ignore')
# passing bridge-types-cat column (label encoded values of bridge_types)
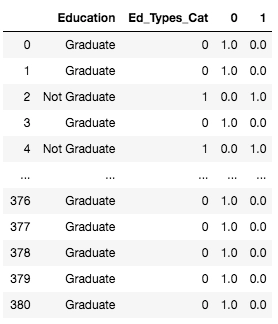
enc_df = pd.DataFrame(enc.fit_transform(Ed_df[['Ed_Types_Cat']]).toarray())
# merge with main df bridge_df on key values
Ed_df = Ed_df.join(enc_df)
Ed_df
We then make dummy variables from the generated labels and then one hot encode the feature.
We can then concatenate the new data frames to the original data frame for the training phase.
Frequently Asked Questions
What is one-hot encoding in Python?
One-hot encoding in Python is a method to convert categorical data into binary vectors, where each unique category is represented as a separate column. Libraries like pandas and scikit-learn offer functions like get_dummies() and OneHotEncoder to perform this transformation efficiently.
What is the principle of one-hot encoding?
The principle of one-hot encoding is to represent each categorical variable as a binary vector, where only one position is marked as 1 to indicate the presence of a specific category, while all other positions are 0. This helps eliminate ordinal relationships in non-ordinal data.
What is better than one-hot encoding?
For datasets with high cardinality (many unique categories), embedding layers or target encoding can be more efficient than one-hot encoding, as they reduce dimensionality and often perform better in models, especially for text data or deep learning applications.
What is the difference between label and one-hot encoding?
Label encoding assigns each category a unique integer, which may introduce unintended ordinal relationships. One-hot encoding, in contrast, represents each category as an independent binary vector, preventing ordinal assumptions and making it better suited for non-ordinal categorical data.
Is one-hot encoding used in NLP?
Yes, one-hot encoding is used in Natural Language Processing (NLP) to represent words or tokens as binary vectors, especially in smaller vocabularies. However, with large vocabularies, techniques like word embeddings (e.g., Word2Vec or GloVe) are often preferred due to their efficiency and context-awareness.
Conclusion
Data processing is essential before developing any machine learning model. Encoding the categorical data is a vital step in the data processing. One hot encoding is a very commonly used encoding technique. Therefore it’s essential to have in-depth knowledge about it and where it can be employed. You can check out our expert-curated data science course if you want to prepare for your next data science interview.
































 9+ registered
9+ registered 

