Do you think IIT Guwahati certified course can help you in your career?
Introduction
Hadoop is an open-source framework that is used to create data processing apps in a distributed computing environment. A lot of bigger data sets are distributed across various clusters. These clusters are commodity computers and apps built with Hadoop are used to execute them. Oozie is one of the components of the Hadoop ecosystem which manages the Hadoop jobs.
In this blog, we will learn all about the basic components of Oozie, along with some examples. So without further due, let’s start learning.
Apache Oozie is an open-source application that comes under Apache license 2.0. It is a workflow scheduler software that enables us to run the workflow of dependent jobs. It is used to run and manage Hadoop jobs in a distributed platform. Oozie can combine multiple jobs to execute in a sequential order to reach a bigger task.
Apache Oozie is integrated with the Hadoop stack backing many Hadoop jobs. A few examples of them are Hive, Pig, Sqoop, etc. Another important feature of Oozie is that it allows multiple jobs to run parallelly in Hadoop.
Oozie triggers the workflow action that executes various tasks using the Hadoop execution engine. It leverages Hadoop’s latest machinery for failover, load balancing, etc.
Oozie Jobs
Oozie performs control of complex multi-stage Hadoop jobs. Thus, many multi-stage Hadoop jobs can be treated as a single Hadoop job. Therefore, we just need to manage the Oozie job. Oozie jobs are mainly categorized into three parts which we will discuss further.
The command for running a workflow, coordinator, or bundle job:
$ oozie job -oozie http://localhost:8080/oozie -config <path to the job>.properties -run
Here, the run command starts a workflow job, coordinator job, or bundle job.
The job parameters are provided in the Java properties file (.properties). This file should be specified with the config option.
Workflow Jobs
A workflow is used to specify the set of actions to be performed along with the orders and conditions for these actions. Oozie workflow jobs are DAGs (Directed Acyclic Graphs) which specify the actions that need to be addressed. These actions include a Java program, MapReduce job, Pig query, etc.
Oozie workflows consist of the following:
Control nodes
Action nodes
Global configuration
Control Nodes: These nodes control the basic execution, the start, and the end of the workflow. A few examples of control nodes are <start>, <end>, <kill>, <error>, etc.
Action Nodes: Action nodes are used to specify the units of workflow execution. A few examples of action nodes are <map-reduce>, <pig>, <hive>, etc.
Global Configuration: These are used to avoid repetitions of actions in the workflow.
Coordinator Jobs
The coordinators are used to schedule the execution of workflow with data availability. If the workflow's input data is unavailable, then the workflow is halted until the data becomes available. Oozie coordinators trigger the workflow jobs at a specified time and/or at a set frequency. Whenever the given conditions are fulfilled, the workflow inside the job coordinator starts.
Definitions
Some definitions required for coordinator jobs are:
Start: It starts the DateTime for the job.
End: It ends the DateTime for the job.
Timezone: It is the timezone of the coordinator applications.
Frequency: It is the frequency in minutes of the execution of jobs.
Control Information
Some properties for control information are:
timeout: It is the maximum time in minutes in which an action will satisfy the additional conditions before getting discarded completely.
0 indicates that the actions should be timeout immediately. This happens if all the input events are not satisfied during action materialization.
-1 indicates no timeout, and the actions will wait forever until other conditions are not satisfied. By default, the value is set to -1.
concurrency: It is the maximum number of actions for this job that can be running at the same time. By default, the value is set to 1.
execution: It is used to specify the execution order whenever multiple coordinator job fulfilled their execution criteria. The valid values are:
FIFO default (oldest first)
LIFO (newest first)
LAST_ONLY
Bundle Job
The coordinator jobs and bundle jobs are present as a package in the Oozie bundle. Oozie bundle allows the user to run a bunch of coordinator applications, often called a data pipeline. The data pipeline is the process in which the output of one coordinator job can be the input to another coordinator job.
Kick-off-time: It is the time when a bundle should start and submit coordinator applications.
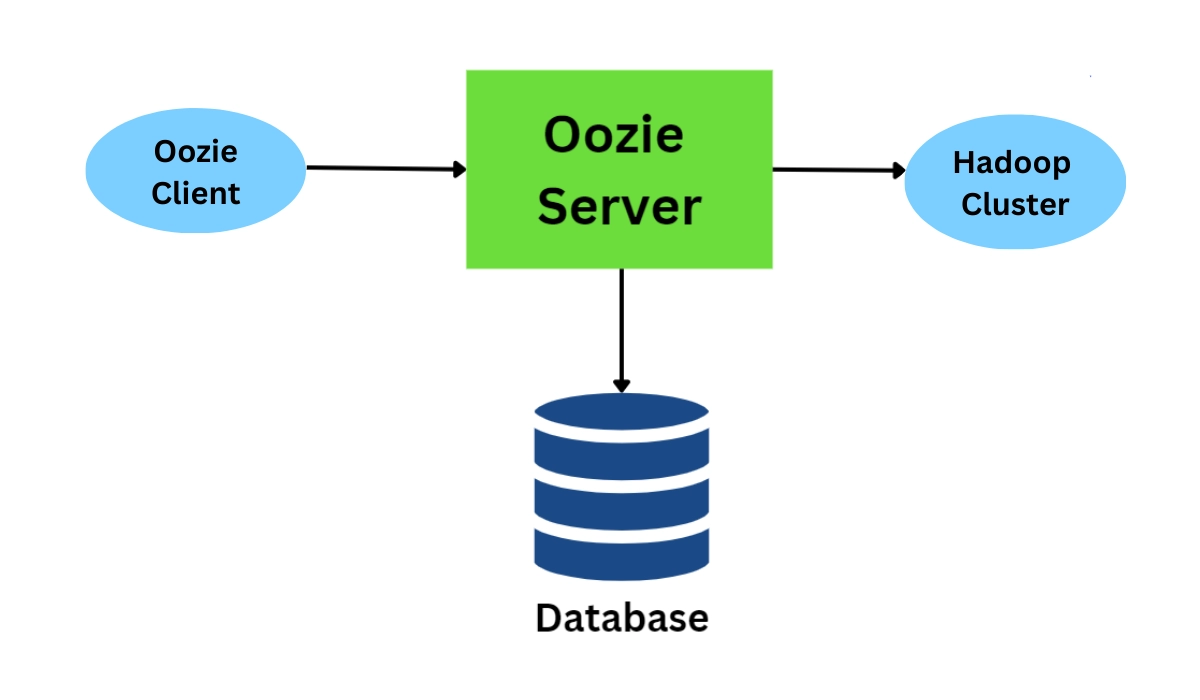
Oozie Architecture
Let us now look at the architecture and components of Apache Oozie.
Oozie Client
The Oozie client is the utility that interacts with the Oozie server. The Oozie client uses HTTP REST API to communicate with the Oozie server.
Oozie Server
Oozie server is a Java web application that runs in a Java servlet container. By default, Oozie uses an open-source Java servlet called Tomcat. Whenever a user request to process a job, the Oozie server fetches the conforming job state from the database. After performing the requested operations, it then updates the database with the new state of the job.
Oozie Database
Oozie stores all the job-related data in the database. Oozie supports databases such as Derby, MySQL, PostgreSQL, and Oracle. By default, Oozie supports the Derby database.
Oozie Cluster
Apache Oozie uses this cluster to run all the jobs in the system. Oozie is built on a modular and extensible architecture that allows users to make changes and extend its features.
Working of Oozie
Let’s now learn about the working of Apache Oozie. Oozie runs the services in clusters submitted by the user for immediate or later processing. The workflow of Oozie mainly consists of two nodes, i.e., action nodes and control-flow nodes.
The action nodes represent the working tasks of Oozie. These tasks include MapReduce tasks, Pig jobs, Hive jobs, importing data using Sqoop, etc.
The control-flow nodes control the workflow execution between different actions. It is done with the help of conditional logic construct. The control flow node includes a start node, an end node, and an error node.
As we can see from the above diagram, we have a start node at first and an end node at the last position. In between, we have a Map-reduce program and an error node. The working of a job starts at the start node and ends at the end node. If the Map-reduce job encounters an error, then the job will be terminated using the kill node. If the Map-reduce job succeeds, then the control goes to the end node.
Features of Oozie
Now that you know the working of Oozie, let us look at various features of Apache Oozie.
It has features like a command line interface and client API which make control and monitoring of jobs from Java applications possible.
Web service APIs of Oozie have removed the location barrier for the users.
The jobs which are scheduled to run periodically can now be executed with the help of Oozie.
Oozie can notify the users through email notifications about job completion.
Oozie is scalable and can perform large-scale data processing in distributed computing environments.
Use Cases of Oozie
Some use cases of Apache Oozie are given below:
Hadoop System administrators use Apache Oozie to run complex log analysis on HDFS (Hadoop Distributed File System).
Hadoop developers use Oozie to do ETL (Extract, Transform, Load) operations on data and to save the output in HDFS.
Oozie is used in various workflows which involve image and video processing. It schedules different tasks such as object detection, image recognition, etc.
In most enterprises, Oozie jobs are scheduled as bundles or coordinators.
Frequently Asked Questions
What is Hadoop?
Apache Hadoop is an open-source framework that is used to store and process a high volume of data efficiently.
What is Oozie?
Apache Oozie is an open-source workflow scheduler system that runs the workflow of dependent jobs. It runs and manages Hadoop jobs in a distributed environment.
Which languages are used in Hadoop?
Most of the Hadoop framework is written in Java programming language. Apart from that, some native code is written in C.
What ETL tool is used for Hadoop?
ETL stands for extract, transform, and load. Apache Sqoop and Apache Flume are the two most popular ETL tools used in Hadoop.
What is HDFS?
The HDFS stands for Hadoop distributed file system. It is one of the major components of Apache Hadoop that handles massive data sets running on commodity hardware.
Conclusion
This article discusses the workflow scheduler Apache Oozie with its architecture. We also discussed the features and use cases of Apache Oozie. We hope this blog has helped you enhance your knowledge about the open-source job scheduler Apache Oozie. If you want to learn more, then check out our articles.
But suppose you have just started your learning process and are looking for questions from tech giants like Amazon, Microsoft, Uber, etc. In that case, you must look at the problems, interview experiences, and interview bundles for placement preparations.
However, you may consider our paid courses to give your career an edge over others!
Happy Learning!
Live masterclass
Amazon Data Analyst Roadmap – From Resume to Interview
by Abhishek Soni
08 Jul, 2026
12:30 PM
Zero to GenAI Developer: Amazon SDE Roadmap for 30L+ CTC
by Sumit Shukla
07 Jul, 2026
12:30 PM
Interview-Ready RAG Project Walkthrough by Google SWE3
by Saurav Prateek
09 Jul, 2026
11:30 AM
Amazon-Ready Excel & AI Skills: Ace 20L+ Data Analyst Roles
by Prerita Agarwal
06 Jul, 2026
11:30 AM
Amazon Data Analyst Roadmap – From Resume to Interview
by Abhishek Soni
08 Jul, 2026
12:30 PM
Zero to GenAI Developer: Amazon SDE Roadmap for 30L+ CTC
































 18+ registered
18+ registered 

