Advantages of Cloud Bigtable
Several significant benefits of Bigtable's robust backend servers over a self-managed HBase installation include:
Incredible scalability: In direct proportion to the number of machines in your cluster, Bigtable scales. After a certain point, a self-managed HBase system has a design bottleneck that restricts performance. This bottleneck is not present with Bigtable, allowing you to build up your cluster to support additional reads and writes.
Simple administration: Bigtable maintains excellent data durability automatically and manages upgrades and restarts transparently. Simply add a second cluster to your instance to begin replicating your data; replication will start immediately. Just create your table schemas, and Bigtable will take care of managing replicas and regions for you.
Cluster resizing without downtime: Without any downtime, a Cloud Bigtable cluster's size can be increased for a few hours to accommodate a heavy load and then decreased again. Under load, Bigtable usually balances performance across all of the nodes in your cluster within a few minutes after you modify the size of a cluster.
Cloud Bigtable storage model
Cloud Bigtable stores data in sorted key/value maps that are enormously scalable tables. The table is made up of columns that contain unique values for each row and rows that typically describe a single object each. A single row key is used to index each row, and a column family is often formed out of related columns. The column family and a column qualifier, a distinctive name within the column family, are combined to identify each column.
Multiple cells may be present at each row/column intersection. A distinct timestamped copy of the data for that row and column is present in each cell. When many cells are put in a column, a history of the recorded data for that row and column is preserved. Bigtable tables are sparse, taking up no room if a column is not used in a given row.
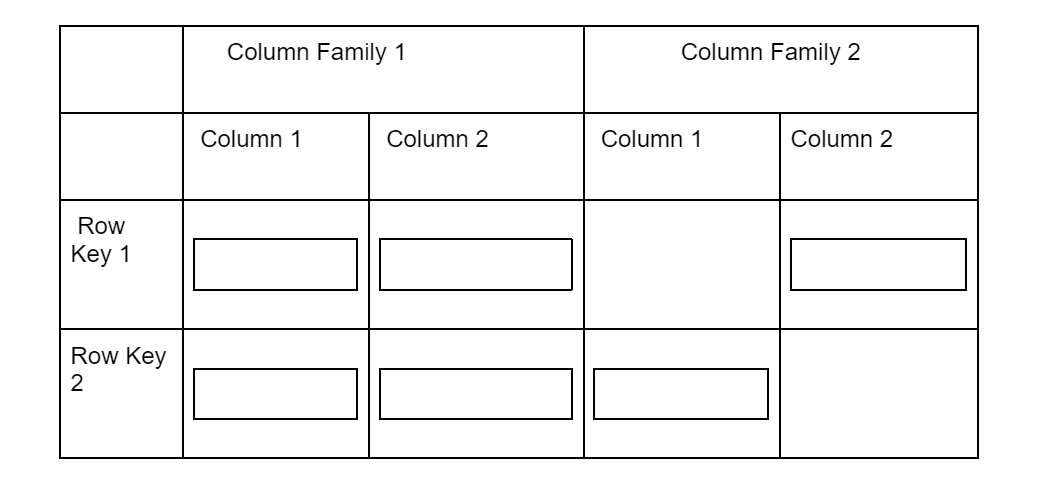
Observe the following in this illustration:
Rows of columns could be empty.
There is a distinct timestamp for each cell in a particular row and column (t).
Bigtable Architecture
Bigtable Instance is a Cluster container that organizes Nodes. Cloud Bigtable uses Google's Colossus file system to store its data. Before being forwarded to a Bigtable node, all client requests are sent through a frontend server. The nodes are arranged as a Bigtable cluster, which is contained within a Bigtable instance.
A portion of the requests made to the cluster is handled by each node. The number of simultaneous requests that a cluster can handle can be increased by adding nodes. The cluster's maximum throughput rises as more nodes are added. You can send various types of traffic to multiple clusters if replication is enabled by adding more clusters. Then you can fail over to another cluster if one cluster is unavailable.
In order to distribute the workload of queries, a Bigtable table is sharded into tablets, which are groups of adjacent rows. (Tablets and HBase areas are comparable.) On Google's Colossus file system, tablets are kept in SSTable format. A durable, ordered, immutable map from keys to values, where both the keys and the values are random byte strings, is provided by an SSTable. Each tablet has a unique Bigtable node assigned to it. In addition to the SSTable files, for improved durability, all writes are recorded in Colossus' shared log as soon as they are acknowledged by Bigtable.
Load balancing
A central process oversees each Cloud Bigtable zone, balancing workload and data volume within clusters. By dividing busier/larger tablets in half and combining less-used/smaller tablets, this procedure moves tablets across nodes as necessary. Bigtable divides a tablet into two when it experiences a spike in traffic and then moves one of the new tablets to a different node. Bigtable handles the splitting, merging, and rebalancing automatically, saving you the time and work of managing your tablets by hand. Understanding performance offers more information about this procedure.
Distribute writes among nodes as evenly as you can to get the best write performance out of Bigtable. Using row keys with unpredictable ordering is one method to accomplish this. By placing a username at the beginning of the row key, for instance, writes will typically be scattered more or less uniformly throughout the alphabet.
Additionally, grouping comparable rows together and placing them next to one another makes it much easier to read multiple rows at once. If you were keeping various kinds of weather data across time, for instance, your row key may be the place where the data was gathered, followed by a timestamp (for instance, WashingtonDC#201803061617). A contiguous range of rows would be created using this kind of row key to combining all the data from one location. With several sites gathering data at the same rate, writes would still be dispersed uniformly between tablets. For other places, the row would begin with a new identifier.
Supported data types
For the majority of uses, Cloud Bigtable treats all data as raw byte strings. Only during increment operations, where the destination must be a 64-bit integer encoded as an 8-byte big-endian value, does Bigtable attempt to ascertain the type.
Memory and disk usage
The following sections go through how various Bigtable components impact your instance's memory and disc use.
Unused columns
In a Bigtable row, columns that aren't used don't take up any room. Each row is essentially made up of a set of key/value entries, where the key is made up of the timestamp, column family, and column qualifier. The key/value entry is just plain absent if a row doesn't have a value for a particular column.
Column qualifiers
Since each column qualifier used in a row is saved in that row; column qualifiers occupy space in rows. As a result, using column qualifiers as data is frequently adequate.
Compactions
To make reads and writes more effective and to remove removed entries from your tables, Bigtable performs periodic rewrites. This procedure is called compaction. Bigtable automatically compacts your data; there are no tuning options.
Mutations and deletions
Bigtable stores mutations, or changes, to a row sequentially and only occasionally compacts them, mutations, or changes to a row, require additional storage space. Values that are no longer needed are removed from a table when Bigtable compacts it. The original value and the updated value will both be kept on a disc until the data is compressed if you change a cell's value.
Because deletions are actually a particular kind of mutation, they also require more storage space, at least initially. A deletion consumes more storage rather than releasing space up until the database is compacted.
Data durability
When you use Bigtable, your data is kept on Colossus, a highly resilient internal file system developed by Google, on storage units located in Google's data centers. To use Bigtable, you don't need to run an HDFS cluster or any other kind of file system. Bigtable keeps a copy of your data in Colossus for each cluster in the instance if your replication instance uses it. Further enhancing endurance, each copy is situated in a different zone or area.
Beyond what conventional HDFS three-way replication offers, Google employs customized storage techniques to ensure data persistence. Additionally, we make duplicate copies of your data to enable disaster recovery and protection against catastrophic situations.
Frequently Asked Questions
What is reverse timestamp?
You can create a row key where the most recent event starts the table rather than the end by flipping the timestamp. As a result, getting the first N rows of the table will provide you with the N most recent events.
What is the row key in HBase?
A row key serves as the table row's distinctive identification. A multi-dimensional map with one or more columns and rows of data makes up an HBase table. When creating an HBase table, you must define the entire set of column families.
Where is time series data stored?
A time series database (TSDB) designed expressly for processing time-stamped measurements and events is the ideal place to store time series data. This is because time series data is frequently absorbed in enormous amounts, necessitating a specially constructed database able to manage that size.
What is column family in HBase?
Column families, which are the logical and physical grouping of columns, are found in an HBase table. Within a column family, which are the columns, there are column qualifiers. Columns with time stamp variations can be found in column families. Because columns only exist after being inserted, HBase is a sparse database.
Conclusion
We covered cloud Bigtable its advantages, architecture, and storage model in this article. We hope this article helps you to learn something new. And if you're interested in learning more, see our posts on AWS vs. Azure and Google Cloud, Google BigQuery, AWS Vs Azure Vs Google Cloud: The Platform of Your Choice?, Java knowledge for your first coding job.
Visit our practice platform Coding Ninjas Studio to practice top problems, attempt mock tests, read interview experiences, and much more.!
Feel free to upvote and share this article if it has been useful for you.






























 9+ registered
9+ registered 

