Google Cloud Spanner Architecture
Spanner is a worldwide database system with a minimum of three shards per area. Each shard will be in a different zone. A shard is known as a Split in Spanner. If you provision a single Node Spanner cluster, you will receive two more Nodes in a separate zone that are invisible to you. Furthermore, the compute and storage layers are separated. The Paxos algorithm is used to keep one leader at a time and the rest of the nodes as followers.
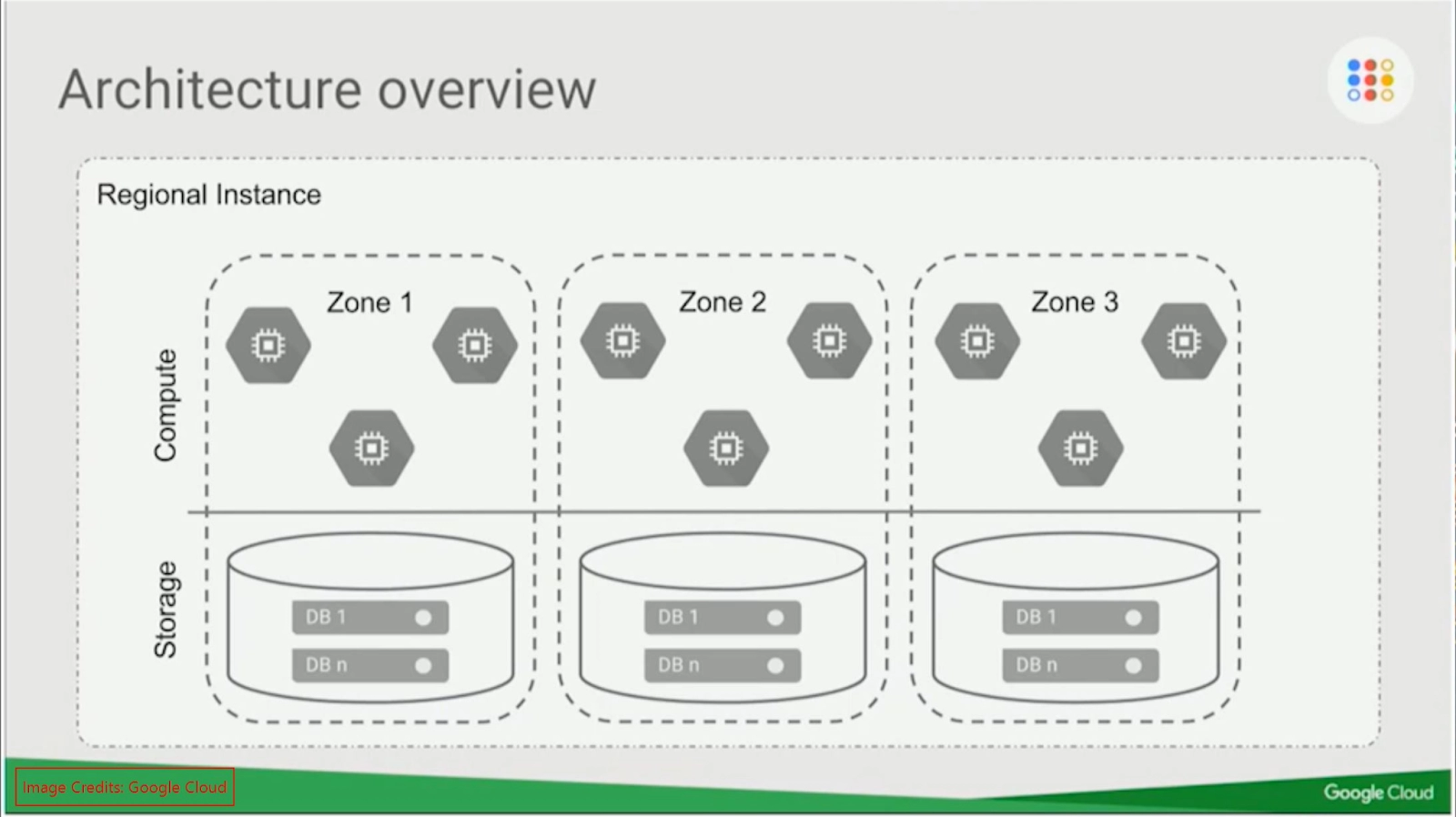
Image Source: thedataguy
We'll have more Splits (shards) in the storage layer based on the partitions. Each shard will be replicated across all Zones. For example, if you have S1 on Zone A, it will be replicated to Zones B and C. The replication method is based on the leader-follower model. As a result, the Paxos will assist in maintaining the quorum and in selecting a new Leader during the failure. The Spanner APIs are aware of the Leaders if you write something on this Split. As a result, the write is sent directly to the zone with the Leader Split. Each Split has its own zone for leaders.
Instance
The location and allocation of resources are determined by the instance. Instance creation involves two critical options:
-
Instance configuration
- Specifies the geographical positioning of the databases, i.e. their location and replication
- The location can be regional or multi-regional
-
Node count
- Identifies the maximum amount of serving and storage resources that can be modified for the instance
To deliver high performance and availability, Cloud Spanner spreads an instance across zones in one or more regions. Instances of Cloud Spanner include:
- At least three read-write database replicas, each in a distinct zone
- Each zone represents a distinct isolation fault domain
- The Paxos distributed consensus protocol is utilised for writes/transaction commits
- Writes are replicated synchronously to all zones across all regions.
- Even if one zone fails, the database remains operational (99.999% availability SLA for multi-region and 99.99% availability SLA for regional)
Regional vs Multi-Regional Configuration
Following are the benefits of choosing regional and multi-regional configurations:
Regional Configuration
- Provides 99.99% availability
- Cloud Spanner keeps three read-write replicas in that region, each in a distinct Google Cloud zone.
- Each read-write replica has a complete copy of the operational database that can serve both read-write and read-only requests.
- Every Cloud Spanner mutation necessitates a write quorum consisting of a majority of voting replicas. Write quorums are generated by combining two of the three regional replicas.
- Cloud Spanner employs replicas in several zones to ensure that the database remains available even if a single zone fails.
Multi-Regional Configuration
- Provides 99.999% availability
- Multi-region configurations allow the database's data to be replicated not just across several zones but throughout multiple regions.
- Multi-region configurations allow the application to perform faster reads in more locations at the expense of a slight increase in write latency.
- Additional replicas provide for low-latency data reading from multiple sites around or inside the configuration's regions.
- Because the quorum (read-write) replicas are distributed across multiple regions, additional network latency occurs when these replicas interact with one another to vote on writes.
Google Cloud Spanner Pricing
The cost for Google Cloud Spanner is based on three infrastructure components:
The pricing for nodes (or processing) in Cloud Spanner is established on an hourly basis, based on the maximum number of nodes used in any given hour in a project. Cloud Spanner storage is priced each month based on the average quantity of data in Cloud Spanner tables and secondary indexes during that month. Google Cloud Spanner network bandwidth cost is set per month based on the quantity used during that month.
Check this out, Spring Boot Architecture
Frequently Asked Questions
How many databases and tables can a Cloud Spanner Instance have?
A Cloud Spanner Instance may contain one or more databases and tables.
How to avoid single-region dependency for the workloads?
Place important compute resources in at least two areas to avoid workloads becoming dependent on a single region.
How does Cloud Spanner get replication?
Cloud Spanner obtains byte-level replication from the underlying distributed filesystem automatically.
Compare the latency in regional and multi-region configurations.
Regional setups offer lower write latencies within an area, and multi-region configurations offer lower read latencies from different geographic regions.
Conclusion
In this article, we have extensively discussed the Google Cloud Spanner. We hope that this blog has helped you enhance your knowledge, to learn more, check out the awesome content on the Coding Ninjas Website:
Android Development, Coding Ninjas Studio Problems, Coding Ninjas Studio Interview Bundle, Coding Ninjas Studio Interview Experiences, Coding Ninjas Courses, Coding Ninjas Studio Contests, and Coding Ninjas Studio Test Series. Do upvote our blog to help other ninjas grow. Happy Coding!






























 8+ registered
8+ registered 

