Do you think IIT Guwahati certified course can help you in your career?
Introduction
In today's world, shifting the data within the DataFrame is one of the common requirements. It is also one of the most important steps in terms of data analysis and data manipulation. This is where Pandas introduced a very important function dataframe.shift(), which can become our survivor to shift the data.
In this article, we will discuss about Pandas dataframe.shift(). Firstly, we will discuss about what Pandas is. Then we will understand the syntax, parameters, and some examples based on the dataframe.shift() function.
So, let's get started!!
A Brief about Pandas
Pandas is one of the most used libraries of Python. It is used to work with data sets. It provides several functions which we can use in Data Manipulation, Data Cleaning, and Data Analysis.
Pandas consist of two data structures, these data structures help to handle and analyze the tabular data:
Series: It looks like a column in a table. It is a 1D(One Dimensional) array. It can hold any type of data
DataFrame: It looks like a table which is having rows and columns. It is a 2D(Two Dimensional) array
What is Pandas dataframe.shift()?
In real-time, there are so many chances where we want to shift the data within the DataFrame. So, to resolve this problem, Pandas provides a function, i.e., dataframe.shift(). This function helps us to move the elements of a DataFrame along the specified axis by a specified number of steps. This function will return a DataFrame.
Pandas dataframe.shift() does not modify the original DataFrame. It will return a new DataFrame after shifting the data accordingly. It will not affect the original DataFrame.
Suppose we want to calculate the daily percentage change of a stock. So, to calculate this, we need to find the days on which the price was decreased or increased. To find the past days or past information, we can use dataframe.shift().
Now, we have a better understanding of dataframe.shift() function, let us understand its syntax.
Syntax
The syntax of Pandas dataframe.shift() is mentioned below:
There are three parameters we have mentioned in the syntax:
periods: It is of integer type. It shows the number of positions to shift the data. If the value is negative, it means data will shift upwards or left. On the other hand, if the value is positive, it means data will shift downwards or right
fill_value: It is an optional parameter in this function. It is used when we have to fill in the missing values that are created by the shift operations
axis: It shows the direction in which we need to shift the data. It is 0 for shifting along rows and 1 for columns. So, by default, it is 0
Now, you might be wondering how we can implement this. Let us understand this with the help of some examples.
Pandas dataframe.shift() Examples :
There are some examples to understand Pandas dataframe.shift():
Example 1
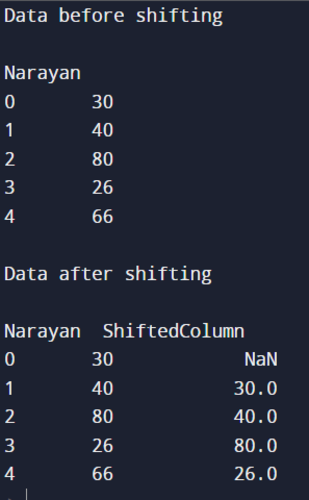
Suppose we want to shift the data of the student along rows. So, we need to write the following program:
Python
Python
# Importing Pandas library import pandas as pd
# Data
studentData = {'Narayan': [30, 40, 80, 26, 66]}
# Creating a DataFrame using the data of the student
dataframe = pd.DataFrame(studentData)
# Printing the DataFrame before shifting
print("Data before shifting\n")
print(dataframe)
# Calculating and adding a new column 'ShiftedColumn' with values shifted by 1 position
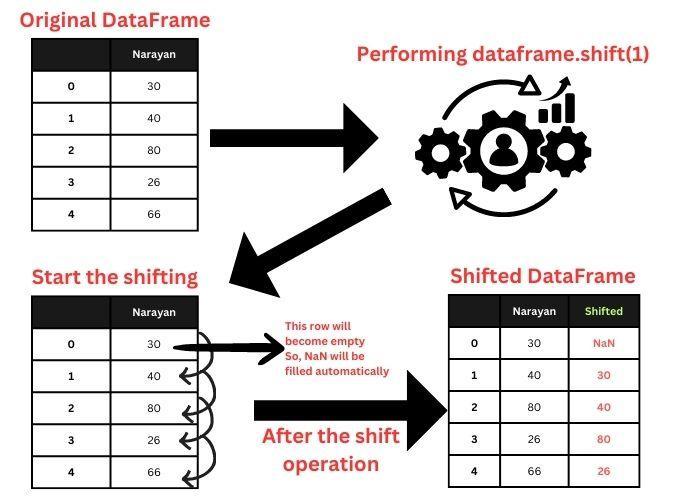
In this example, we are shifting the data of the student by 1 position. Firstly, we imported the Pandas library, and then we created studentData. Then we created a DataFrame of the studentData. Then we have used this DataFrame to shift along with the row by 1 position and produced a new column ShiftedColumn. The 1st row in the new column will have a NaN value which means not a number. This is because there is no value before the first row. Let us see how this is happening in a pictorial representation:
Example 2
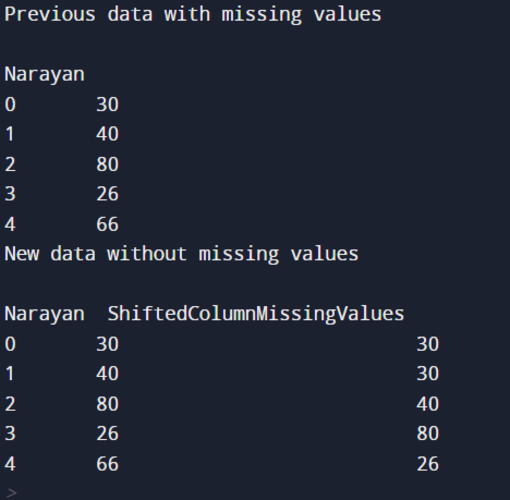
Suppose we want to fill in the missing details of a student. So, we need to fill the value in place of NaN in the above example:
Python
Python
# Using previous Dataframe
print("Previous data with missing values\n")
print(dataframe)
# Calculating and adding a new column 'ShiftedColumnMissingValues'
# Using fill_value=30 to replace missing values with 30
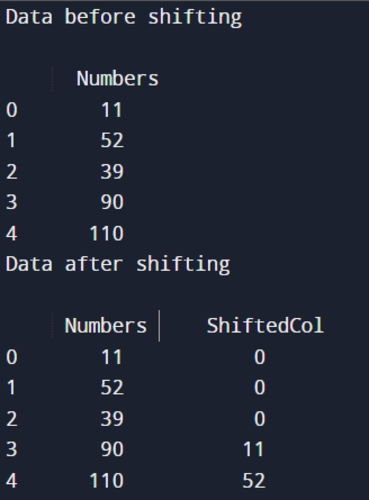
In this example, we have created a DataFrame using randomNum. Then we shifted the data by 3 positions in the column. Then we filled the missing values or NaN values with the help of 0’s. That’s why we have passed three parameters to perform this operation in the dataframe.shift() function. In this example, we can also remove the axis parameter because its default value is 0.
Why Use Pandas dataframe.shift()?
Pandas dataframe.shift() can be used for various purposes:
Time series analysis: It can be used when we are dealing with time series data. We might want to compare the current value with a previous or future value
Calculating differences: It can be used to find the difference between consecutive values. It can mainly be used in financial or scientific datasets
Comparing trends: It can be used to assess the change in trends or patterns between different time periods or categories. We can compare trends to make better decisions using this function
Advantages of Pandas dataframe.shift()
There are several advantages of using dataframe.shift():
It can be used to analyze trends and variations with the help of comparing rows and columns
It can be used in financial and economic analysis because it helps in comparing current values with past or future values
It can be used to find historical data and predictive modeling in machine learning
It comes up with flexible parameters. We just need to specify the number of periods to shift, the axis of shifting, and fill values for missing data
Disadvantages of Pandas dataframe.shift()
Along with the advantage, it also has some disadvantages:
It can create a missing data problem when we shift from starting or ending
When we try to shift the large DataFrames, the time complexity might be increased
When using shifted columns as features in machine learning, there's a risk of overfitting if not used carefully, as the model might learn to predict the target variable using future information
We cannot perform complex transformations or calculations. We also need to perform some other operations which we cannot perform using this function alone
Frequently Asked Questions
How can we shift data by more than one position?
We can specify a positive or negative value in the periods parameter. This will help us to shift the data by more than one position.
What can we do if there are missing values in our DataFrame?
We can use the fill_value parameter. It will specify a value to fill the missing values generated by the shift operation.
How does shifting along columns work?
Shifting along columns moves the data horizontally, with each element moving to the adjacent column. The axis parameter is set to 1 for this operation.
Can we use Pandas dataframe.shift() with time-based data?
Yes, we can use the Pandas dataframe.shift() with time-based data. It is often used in time series analysis to compare current data points with past or future data points. It helps in analyzing trends, identifying anomalies, and calculating differences over time.
Conclusion
In this blog, we have discussed about Pandas dataframe.shift(). It is a very important function when we want to shift the DataFrames according to our requirements. If you want to learn more about the Pandas in Python, then you can check out our blogs:
We hope this blog helps you to get knowledge about the Pandas dataframe.shift(). You can refer to our guided paths on the Codestudio platform. You can check our course to learn more aboutDSA, DBMS, Competitive Programming, Python, Java, JavaScript, etc.
































 9+ registered
9+ registered 

