Do you think IIT Guwahati certified course can help you in your career?
Introduction
Reading Excel files is a common task in data analysis and automation, and Python makes it easy with its versatile libraries. Whether you need to extract data for processing, analyze spreadsheets, or automate reporting, Python provides powerful tools like pandas and openpyxl to simplify these tasks. In this guide, we'll understand the step-by-step process of how we can read Excel file in Python Pandas.
This article will help you understand the function pandas.read_excelin depth. So, let us dive into the topic and explore it more.
Pandas read excel
Pandas read excel ( pandas.read_excel() ) is a pandas function that reads an excel sheet with the extension xlsx into a pandas DataFrame object. In the Excel sheet, the data is in two-dimensional table form. In the DataFrame object, the data is also in a two-dimensional tabular form.
Let us understand this with the help of an example:
In the above example, we have an Excel file named Student_data, and we print the data into DataFrame objects with the help of pandas.read_excel function.
The pandas read excel function has different parameters to read the excel file as per the user's requirement. So, let us look into some of the parameters.
Parameters of pandas read excel
This section of the article will give you a brief overview of the different parameters of the pandas read excel function:
Parameters
Description
io
It is a valid string path directing to the workbook. The string could be any URL, local path, filename, or file-like object.
sheet_name
It reads the sheet name of the workbook. A sheet name can only be a string, an integer can be used in zero-indexed sheet positions.
header
It reads the header row. If there is no header, then use none. The dtype is an object. dtype is nothing but the datatype.
use_col
It parses all the columns if none is mentioned, and it will parse the column of that index that is mentioned. If the list of string or integer is mentioned, it will parse all the columns mentioned.
index_col
It reads the column mentioned in the index_col and will print the column at the index position. It passes None if there is no such column.
dtype
It tells the type of data present in the file and mentions the type of data present in the column.
skiprow
It skips the row which is mentioned in the skiprow; it takes an integer value.
nrows
It parses upto the given row mentioned in the nrows parameter.
skipfooter
It skips the number of rows from the bottom of the file which is being parsed and contains this parameter.
Now , let us understand these parameters more with the help of examples.
Read Excel Files in Python Using Different Methods
Python offers various libraries to read Excel files, each suited to specific use cases. Before proceeding, ensure you have the necessary libraries installed and an input Excel file ready. Here, we demonstrate how to read Excel files using three popular methods.
Required Modules and Input File
Install the required libraries using pip: pip install pandas openpyxl xlwings
Prepare an input Excel file, for example, sample.xlsx, containing sample data.
Method 1: Reading an Excel File Using Python with Pandas
The pandas library provides a straightforward way to read Excel files into a DataFrame, which is ideal for data manipulation and analysis.
import pandas as pd
# Reading the Excel file
file_path = "sample.xlsx"
df = pd.read_excel(file_path)
# Displaying the content
print("Data from the Excel file:")
print(df)
Output:
When executed, this code reads the content of sample.xlsx and displays it in a tabular format, like this:
Data from the Excel file:
Name Age Department
0 Rohit 30 Finance
1 Rahul 25 Operations
2 Mohit 35 IT
Method 2: Reading an Excel File Using Python with openpyxl
openpyxl is a library designed for interacting with Excel files, supporting both .xlsx and .xlsm formats.
from openpyxl import load_workbook
# Loading the workbook
file_path = "sample.xlsx"
workbook = load_workbook(file_path)
# Selecting the active sheet
sheet = workbook.active
# Reading and displaying data
print("Data from the Excel file:")
for row in sheet.iter_rows(values_only=True):
print(row)
Output:
This method reads and prints each row from the sample.xlsx file:
Data from the Excel file:
('Name', 'Age', 'Department')
('Rohit', 30, 'Finance')
('Rahul', 25, 'Operations')
('Mohit', 35, 'IT')
Method 3: Reading an Excel File Using Python with Xlwings
Xlwings allows you to interact with Excel using Python, making it ideal for tasks involving live Excel applications.
import xlwings as xw
# Opening the Excel file
file_path = "sample.xlsx"
app = xw.App(visible=False)
workbook = xw.Book(file_path)
# Selecting the first sheet
sheet = workbook.sheets[0]
# Reading and displaying data
data = sheet.range("A1").expand().value
print("Data from the Excel file:")
for row in data:
print(row)
# Closing the workbook
workbook.close()
app.quit()
Output:
The code fetches and displays data from sample.xlsx dynamically:
Data from the Excel file:
['Name', 'Age', 'Department']
['John', 30, 'Finance']
['Jane', 25, 'Operations']
['Mark', 35, 'IT']
Understanding the parameter of panda read excel
We have an Excel file having 2 sheets named "Student" and "Article". Using these sheets, we will see examples of the parameters we’ve discussed above.
io
It is a valid string path directing to the workbook. The string could be any URL, local path, filename, or file-like object. The path directing to the workbook must be in single quotes [ ' ' ].
Code
import pandas
# printing file data using read_excel
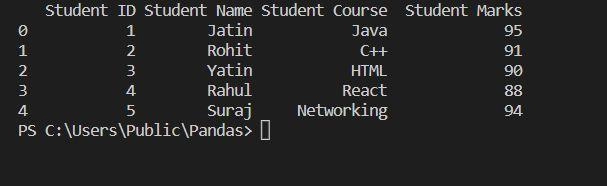
read1=pandas.read_excel('C:/Users/Public/Pandas/Student_data.xlsx')
print(read1)
Output
Explanation
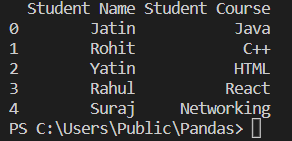
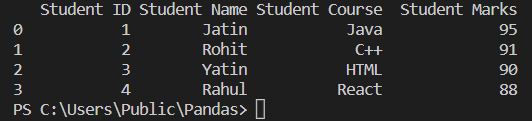
As we see, we are reading the data from the Student_data.xlsx file using read_excel and printing the data into pandas DataFrame object. So in the above example, the valid string path directs to the file "C:/Users/Public/Pandas/Student_data.xlsx " i.e., "io" in the code. We can see that the Student data is printed, i.e., the first sheet only, so if "sheet_name" is not mentioned, it will print the first sheet only by default.
sheet_name
It reads the sheet name of the workbook. A sheet name can only be a string, and an integer can be used in zero-indexed sheet positions.
Code
import pandas
#printing file data with sheet name
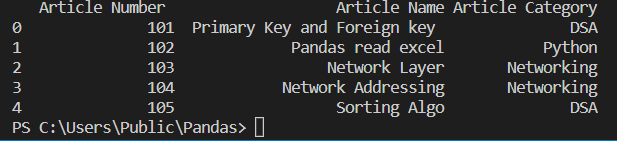
read2=pandas.read_excel('Student_data.xlsx',sheet_name='Article')
print(read2)
Output
Explanation
The sheet_name will print all the data present in that particular sheet. In the above example, we have used theArticle as the sheet name, and then as you can see, all the data of the articles sheet is printed.
header
It reads the header row. If there is no header, then use none. The dtype is an object. dtype is nothing but the datatype.
Code
import pandas
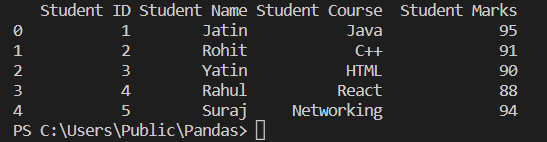
read1=pandas.read_excel('Student_data.xlsx')
# To print the heading row
print(read1.columns.ravel())
Output
Explanation
"read1.columns.ravel()" is used to get the data of the header row, which is printed using print(). We are using the read1.columns.ravel() to print the header as it will print the column names at index 1, which eventually is the header row.
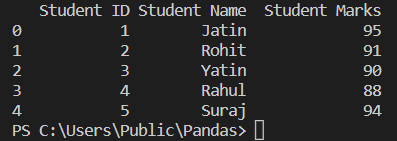
use_col
It parses all the columns if none is mentioned, and it will parse the column of that index that is mentioned. If the list of string or integer is mentioned, it will parse all the columns mentioned.
Method 1
import pandas
#using usecols to prints the given columns by column number
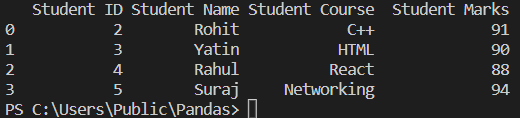
read1=pandas.read_excel('Student_data.xlsx',usecols=[1,2])
print(read1)
Method 2
import pandas
#using usecols to print the given columns, you can use the heading name also
read1=pandas.read_excel('Student_data.xlsx',usecols=['Student ID','Student Name','Student Marks'])
print(read1)
Output 1
Output 2
Explanation
usecol=[ ] to parse through the specific column and get the desired data. It can be done in two different ways:
Using column number
Using column name
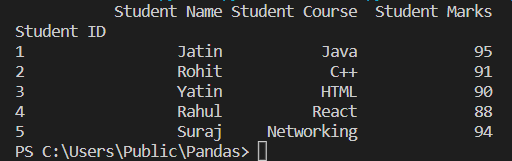
index_col
It reads the column mentioned in the index_col and will print the column at the index position. We’ll pass None if there is no such column.
Code
import pandas
#using student ID as index_col
read1=pandas.read_excel('Student_data.xlsx',index_col='Student ID')
print(read1)
Output
Explanation
It will read the column mentioned in the index_col and will print the column at the index position. As you see in the above example, the "Student ID" has become the index of the data present.
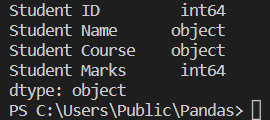
dtype
It tells the type of data present in the file and also mentions the type of data present in the column.
Code
import pandas
read1=pandas.read_excel('Student_data.xlsx')
#using read1.dtypes to get the datatype of the read data
print(read1.dtypes)
Output
Explanation
This is used to check the file's data type and each column's data type. Look at the above output; you will see that different columns have different datatypes, and the file's data type is also mentioned as an "object".
skiprow
It skips the row which is mentioned in the skiprow, it takes an integer value.
Code
import pandas
#using the row number to skip the row
read1=pandas.read_excel('Student_data.xlsx',skiprows=[1])
print(read1)
Output
Explanation
This will skip the parsing of the data of the row mentioned; like in the above code, row 1 is skipped as the "skiprow=1".
nrows
It will parse upto the given row mentioned in the nrows parameter.
Code
import pandas
# Use the number of rows to print only desired number of rows
read1=pandas.read_excel('Student_data.xlsx',nrows=3)
print(read1)
Output
Explanation
This will parse into the desired number of rows only, as you can see in the above code "nrow=3", so it parses up to three rows.
skipfooter
It is used to skip the number of rows from the bottom of the file which is being parsed and contains this parameter.
Code
import pandas
# Use the number of rows to skip the row from the last using skipfooter
read1=pandas.read_excel('Student_data.xlsx',skipfooter=1)
print(read1)
Output
Explanation
skipfooter is used to skip the data at the bottom of the page or the row present at the bottom. In the above example, the last row is skipped.
Frequently Asked Question
How to read an xls file in pandas?
Use the read_excel() function in pandas with the engine='xlrd' parameter for .xls files:
pd.read_excel('file.xls', engine='xlrd')
What is the fastest way to read an Excel file in Python?
Using pandas with read_excel() and specifying engine='openpyxl' for .xlsx files is generally the fastest for most use cases.
Which is better, pandas or openpyxl?
Pandas is better for data analysis and manipulation, while openpyxl is preferred for advanced Excel file operations like formatting or writing macros.
Can pandas read csv read excel?
The pandas library can read data from CSV or excel files. The pandas function that can be used is read_csv() or read_excel(). The file path can only contain a string and must include the file name and extension.
Which Python package read Excel file?
Openpyxl is a tool that lets you read from or write to Excel files using Python. Data scientists use it to analyze and manipulate data, copy information, mine for insights, make charts, format sheets, add formulas, and automate tasks for data processing.
What is the difference between read CSV and read Excel?
CSV is a plain text format with a series of values separated by commas, whereas Excel is a binary file containing data for all worksheets in a workbook. CSV files are unable to perform data operations, but Excel can.
Conclusion
In this article, we learned the pandas library in Python, the pandas read excel function, and the different parameters of the pandas read excel function. We hope this article helped you in knowing more about the pandas read excel.
If you want to learn more, refer to these articles:

































 18+ registered
18+ registered 

