Do you think IIT Guwahati certified course can help you in your career?
Introduction
Parsing is the process of changing the formatted text into a data structure. Parsers are generally used to represent input data from source code directly as a data structure to check if the syntax is correct.
Do you know what parsing is in compiler design? If not, then don't worry because, in this article, we will discuss about parsing in compiler design and the process of parsing, types of parsing along with their drawbacks.
What is Parsing in Compiler Design?
Parsing in compiler design refers to the process of analyzing a sequence of tokens (usually generated by the lexer or lexical analyzer) to determine its grammatical structure with respect to a specified grammar, typically represented by a context-free grammar (CFG). The goal of parsing is to check whether the input conforms to the syntactic rules of the language and to construct a parse tree or syntax tree representing the hierarchical structure of the program.
We know that the first step in the compilation process is Lexical Analysis. It is the starting Phases of Compiler in which modified source code is gathered. A lexical analyzer breaks syntax into a series of tokens by removing white spaces. For example, taking characters as input and returning a stream of tokens. This stream of tokens is checked to determine whether it belongs to proper grammar.
Types of Parsers in Compiler Design
A parser determines how input can be derived from the start of the grammar symbol. There are mainly two types of parsers, top-down and bottom-up, and each has sub-types.
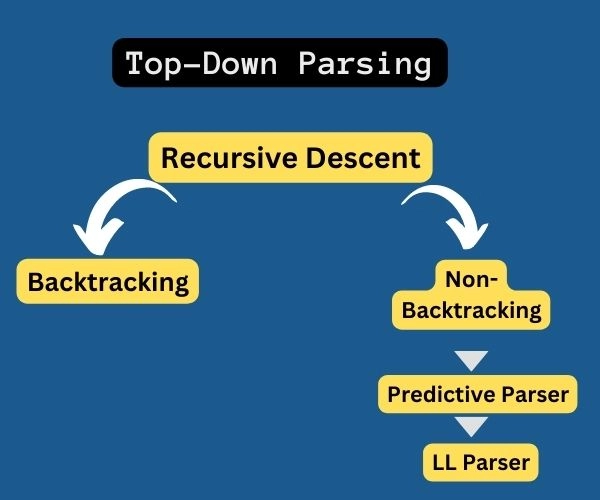
Top-down parsing
This is also known as predictive parsing. The top-down parser follows this approach in finding the input stream's leftmost derivations. This is done by searching for parse trees by consuming tokens from left to right, using top-down expansion according to the given formal grammar rules.
Top-down parsing starts from the 'start' symbol and ends on the terminals, and we usually expand all possible alternatives in the grammar rules instead of choosing one option. It is known as the primordial soup approach; similar to sentence diagramming, it breaks down the constituencies of sentences.
Drawbacks of top-down parsing
Below are some of the drawbacks of top-down parsing:
While making predictions, semantic actions cannot be performed.
Precise error reporting is not possible in top-down parsing. .
Backtracking may be required in some recursive descent parsing.
Left recursion is not handled by top-down parsing.
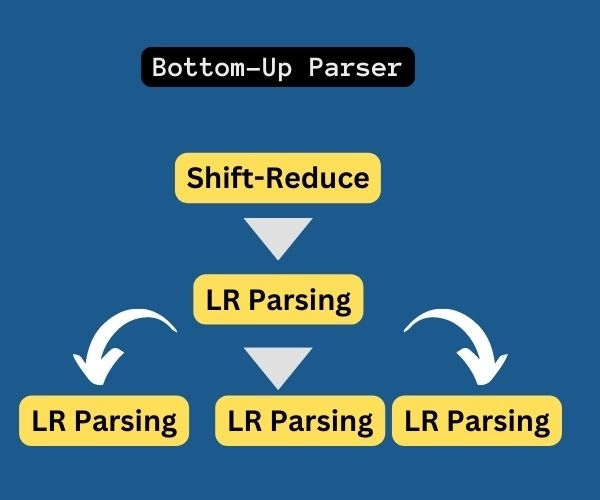
Bottom-up parsing
Bottom-up parsing is also known as Shift-Reduce parsing. It works by reversing the top-down parsing. Therefore first, the input’s rightmost derivation is raced until it reaches the start symbol.
Drawbacks of Bottom-up parsing
Below are some of the drawbacks of bottom-up parsing
The bottom-up parser does not support the left/right information flow.
It leads to the production of ambiguous grammar. Ambiguous makes more than one Leftmost Derivation (or Rightmost Derivation) for the same sentence.
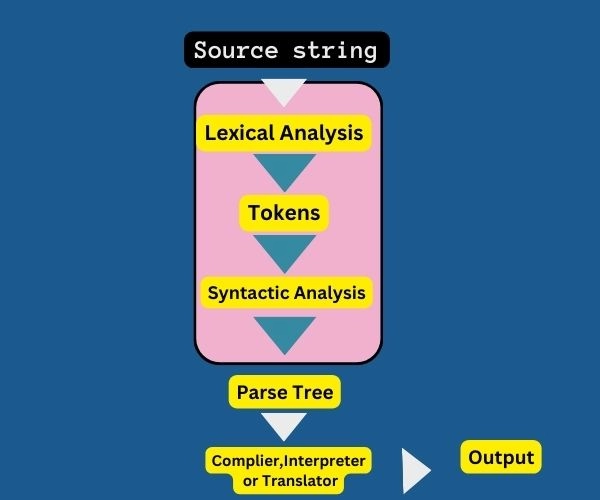
The process of Parsing
Parsing a computer program takes place in two levels of grammar, lexical and syntactic.
In the token generation or lexical analysis stage, the input character string is passed int to the parser and is split into meaningful symbols according to the defined grammar.
For instance, consider this input string “4*(7+9)” is split in tokens 4,*,(,7,+,9,). Each symbol has a specific meaning according to the arithmetic expression.
The lexer breaks down the input string into a series of tokens. It consists of certain rules for matching the input characters to the appropriate tokens. If any character in the input string (e.g., “*7” or “(8”) does not match the rules defined by the lexer, it skips those or throws an error.
The parser uses these tokens for constructing a parse tree. A parser is a part of the compiler, and parsing is a part of the compilation process of a compiler. It is a software component that accepts input data and builds a data structure, and that data structure can be a kind of abstract syntax tree, parse tree, or any hierarchical structure. It is used for further processing like error checking, code generation, or optimization.
The next stage in the process is syntactic analysis or parsing. This means checking if the tokens can form an expression that can be allowed. Context-free grammar recursively defines components that can make an expression and the order in which they appear.
Semantic parsing or analysis is the final phase involving stepping into decision-making, anticipating potential problems, and taking appropriate actions.
Parsing Algorithms
Below are some of the parsing algorithms
CYK Algorithm
CYK (Chomsky Normal Form) is a basic algorithm for parsing context-free grammars (CFG). This algorithm checks if the provided CFG string belongs to a given language. Therefore, CYK algorithms check if the string satisfies CFG-specified conditions.
Earley’s Algorithm
Earley’s algorithm is a top-down parsing algorithm that parsers context-free grammar with ambiguous grammar. It is an efficient algorithm that generates an acyclic constituent parse tree.
LL parsing Algorithm
It is a top-down parsing method. This algorithm requires an input string, a parsing table for the given grammar, a stack, and a parser. It determines if the given grammar/parsing table can produce the specified string. If it cannot be produced, then we get an error.
LR parsing Algorithm
It is a bottom-up parsing method for Context Free Grammar. The input is read from left to right, producing a right-most derivation. It reduces the top-level grammar productions as it builds from the leaves. It consists of an input buffer that contains a string that ends with the $ symbol and a stack (combo of the current input symbol and state symbol). Recommended article-LR Parsing.
Why is Parsing useful
Parsing is essential in compiler design and many other areas of computing because it allows for the interpretation and analysis of structured data. Here's why parsing is useful:
Language Processing: Parsing enables the analysis of programming languages, markup languages, query languages, and other structured data formats. It ensures that the input conforms to the syntax rules of the language, facilitating further processing and execution.
Error Detection: By checking the input against the language grammar, parsing helps identify syntax errors in programs or data. This allows developers to catch mistakes early in the development process, improving software quality and reliability.
Semantic Analysis: Parsing lays the groundwork for subsequent phases of the compiler, such as semantic analysis. Once the syntax of the program is understood, semantic analysis can be performed to check for logical errors and enforce language-specific rules.
Data Extraction: In data processing tasks, parsing is used to extract relevant information from structured data sources such as log files, web pages, and documents. This allows for data manipulation, transformation, and visualization.
Interoperability: Parsing facilitates interoperability between different systems by enabling the exchange and processing of data in standardized formats. For example, parsers are used in web browsers to interpret HTML, CSS, and JavaScript, ensuring proper rendering and functionality of web pages.
Technologies that use Parsers
Several technologies rely on parsers for interpreting and processing structured data:
Programming Languages: Compilers and interpreters for programming languages use parsers to analyze source code and generate executable machine code or bytecode.
Markup Languages: Web browsers, XML processors, and document editors use parsers to interpret markup languages such as HTML, XML, and Markdown, rendering content and applying styling or structure.
Query Languages: Database management systems (DBMS) and search engines use parsers to interpret query languages like SQL, XPath, and JSONPath, enabling users to retrieve and manipulate data.
Configuration Files: Software applications often use parsers to interpret configuration files, allowing users to customize settings and parameters.
Networking Protocols: Network protocols such as HTTP, FTP, and SMTP rely on parsers to interpret request and response messages, facilitating communication between clients and servers.
Parsing is the process of deriving string from a given grammar. This is the process of converting data from one format to another using a parser. A parser is a part of the translator that helps organize linear text structure by following defined rules.
What are the types of parsing?
There are mainly two types of parsers, top-down and bottom-up. The top-down parser follows this approach in finding the input stream's leftmost derivations. This is done by searching for parse trees by consuming tokens from left to right, using top-down expansion according to the given formal grammar rules. Bottom-up parsing works by reversing top-down parsing. Therefore first, the input’s rightmost derivation is raced until it reaches the start symbol.
What is an example of parsing?
An example of parsing is when a web browser interprets HTML code to render a web page. The browser parses the HTML document, identifies elements like tags and attributes, and displays the page accordingly.
What are the techniques of parsing?
Common parsing techniques include top-down parsing (e.g., recursive descent parsing), bottom-up parsing (e.g., LR parsing), and predictive parsing. These techniques vary in their approach to analyzing the input according to a specified grammar.
What is parsing in programming?
Parsing in programming refers to the process of analyzing structured data, such as source code or markup, to extract meaningful information and understand its syntactic structure. This process is essential for interpreting and processing data in various programming tasks, including compilation, interpretation, and data manipulation.
Conclusion
We hope this article helped you understand parsing in compiler design. We have discussed l parsing in compiler design and the parsing process, types of parsing, and their drawbacks. You can read more such articles on our platform, Coding Ninjas Studio.
Must Read- Compiler Design. You will find straightforward explanations of almost every topic on this platform. So take your coding journey to the next level using Coding Ninjas.






























 8+ registered
8+ registered 

