



























Introduction
Pipelining is a method of breaking down a sequential process into sub-operations, with each sub-process running in its own dedicated segment that runs in parallel with the others.
In most central processing unit (CPU) architectures, addressing modes are part of the instruction set architecture. The multiple addressing modes are established in an instruction set architecture to determine how machine language instructions identify each instruction's operand(s). In this article, we are going to discuss previous Gate questions on Pipelining and Addressing Modes.
So, let's get started:
Question 1: Consider an instruction pipeline with five stages without any branch prediction: Fetch Instruction (FI), Decode Instruction (DI), Fetch Operand (FO), Execute Instruction (EI) and Write Operand (WO). The stage delays for FI, DI, FO, EI and WO are 5 ns, 7 ns, 10 ns, 8 ns and 6 ns, respectively. There are intermediate storage buffers after each stage and the delay of each buffer is 1 ns. A program consisting of 12 instructions I1, I2, I3, …, I12 is executed in this pipelined processor. Instruction I4 is the only branch instruction and its branch target is I9. If the branch is taken during the execution of this program, the time (in ns) needed to complete the program is
GATE CS 2013
- 132
- 165
- 176
- 328
Solution: (B) 165
Explanation
The pipeline will have to be halted until the Ei stage of l4 is completed, as this will determine whether or not to take a branch.
After that, l4(WO) and l9(Fi) can run parallel, followed by the procedures below.
So, until l4(Ei) is finished: 77ns = 7 cycles * (10 + 1) ns
8 cycles * (10 + 1)ns = 88ns from l4(WO) or l9(Fi) to l12(WO)
Total time = 77 + 88 = 165 nanoseconds
Question 2: Consider analysing the following expression tree on a system with a load-store architecture, which allows only load and store instructions to access memory. Initially, the variables a, b, c, d, and e were held in memory. Only when the operands are in registers can the machine evaluate the binary operators employed in this expression tree. Only a register is affected by the instructions. What is the smallest number of registers required to evaluate this expression if no intermediate results may be saved in memory?
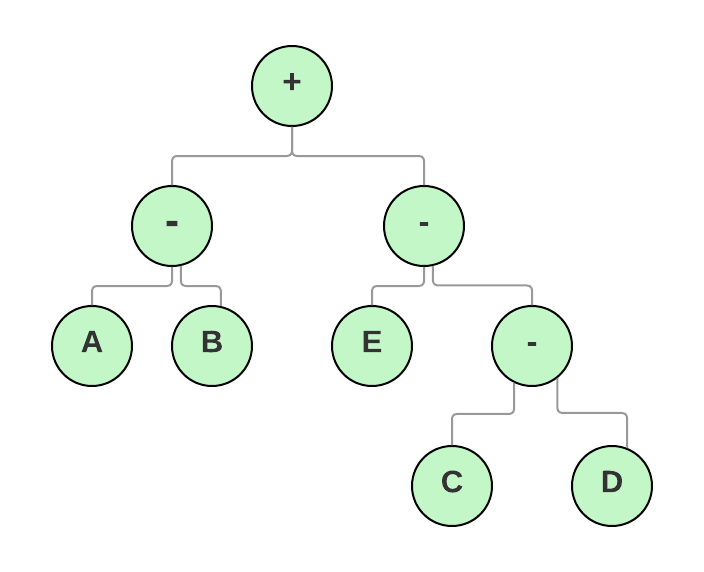
- 2
- 9
- 5
- 3
Solution: (D) 3
Explanation
R1←c, R2←d, R2←R1+R2, R1←e, R2←R1-R2
Now we must load a and b into the registers in order to calculate the rest of the statement, but we will need the content of R2 later.
As a result, we'll need to use a different Register.
R1←a, R3←b, R1←R1-R3, R1←R1+R2
Question 3: Which of the following is/are true of the auto-increment addressing mode?
I. It is useful in creating self-relocating code.
II. If it is included in an Instruction Set Architecture,
then an additional ALU is required for effective address
calculation.
III. The amount of increment depends on the size of the data
item accessed.
GATE CS 2008
- I only
- II only
- III only
- II and III only
Solution: (C ) III only
Explanation
The address for the next data block to be put in auto-increment addressing mode is created automatically based on the size of the single data item to be saved. Option 1 is erroneous because no additional ALU is necessary because self-relocating code always takes some address in memory, and the statement says that this mode is used for self-relocating code. Hence option (C) is the proper option.
Question 4: Which of the following must be true for the RFE (Return from Exception) instruction on a general purpose processor?
I. It must be a trap instruction
II. It must be a privileged instruction
III. An exception cannot be allowed to occur during
execution of an RFE instruction
GATE CS 2008
- I only
- II only
- III only
- I, II, and III only
Solution: (D) I, II, and III only
Explanation
When an exception occurs, RFE (Return From Exception) is a privileged trap instruction that is performed, preventing the exception from being executed. A sudden transfer of control to the operating system can be specified as an exception in computer architecture for a general purpose CPU. Exceptions can be categorised into three categories: a. Interrupt: This is primarily due to an I/O device. b. Trap: This is caused by a syscall made by the programme. c. Fault: It is caused by a program that is now running, such as ( a divide by zero, or null pointer exception etc). The fetch instruction unit of the processor polls for interrupts.
If it detects something odd in the machine's operation, it substitutes an interrupt pseudo-instruction for the normal instruction in the pipeline.
Then, as it progresses through the pipeline, it begins to handle the interrupts. By employing the privileged instruction RFE(Return From Exception), the operating system expressly transitions from kernel mode to user mode, usually at the end of an interrupt handler or kernel call.
Question 5: In an instruction execution pipeline, the earliest that the data TLB (Translation Lookaside Buffer) can be accessed is
GATE CS 2008
- before effective address calculation has started
- during effective address calculation
- after effective address calculation has completed
- after data cache lookup has completed
Solution: ( C) after effective address calculation has completed
Explanation
The address after addressing mode is the effective address. However, this lead address is still a virtual address; the virtual address is not accessible to the CPU and is only delivered by the Memory Management Unit when a corresponding address is assigned to it. For TLB lookup, a virtual address is provided. TLB stands for Translation Lookaside Buffer. During the translation of an address, the term "lookaside" is used (from Virtual to Physical). However, before we can look at the TLB, the virtual address must be present. As a result, (C) is the correct answer.
Question 6: Consider the data given in the question. Assume that the memory is word addressable. After the execution of this program, the content of memory location 2010 is:

GATE CS 2007
- 100
- 101
- 102
- 110
Solution: (A) 100
Explanation
The program keeps track of results from 2000 to 2010. At the 2010 location, it stores 110,109,108.....100. As a result, it stores 100 items in 2010. Because DEC R1 is an instruction that reduces the value of a register by one. As a result, (A) is the correct answer.
Question 7: An instruction pipeline has five stages, namely, instruction fetch (IF), instruction decode and register fetch (ID/RF), instruction execution (EX), memory access (MEM), and register writeback (WB) with stage latencies 1 ns, 2.2 ns, 2 ns, 1 ns, and 0.75 ns, respectively (ns stands for nanoseconds). To gain in terms of frequency, the designers have decided to split the ID/RF stage into three stages (ID, RF1, RF2) each of latency 2.2/3 ns. Also, the EX stage is split into two stages (EX1, EX2) each of latency 1 ns. The new design has a total of eight pipeline stages. A program has 20% branch instructions which execute in the EX stage and produce the next instruction pointer at the end of the EX stage in the old design and at the end of the EX2 stage in the new design. The IF stage stalls after fetching a branch instruction until the next instruction pointer is computed. All instructions other than the branch instruction have an average CPI of one in both the designs. The execution times of this program on the old and the new design are P and Q nanoseconds, respectively. The value of P/Q is __________.
GATE CS 2014
- 1.5
- 1.4
- 1.8
- 2.5
Solution: (A) 1.5
Explanation
Each one takes an average 1CPI.
In 1st case 80% take 1 clock and 20% take 3 clocks so total time:
p = (.8*1 + .2*3)*2.2=3.08.
q = (.8*1 + 6*.2)*1=2
p/q = 1.54
Question 8: A CPU has a five-stage pipeline and runs at 1 GHz frequency. Instruction fetch happens in the first stage of the pipeline. A conditional branch instruction
computes the target address and evaluates the condition in the third stage of the pipeline. The processor stops fetching new instructions following a conditional branch until the branch outcome is known. A program executes 109 instructions out of which 20% are conditional branches. If each instruction takes one cycle to complete on average, the total execution time of the program is:
GATE CS 2006
- 1.0 second
- 1.2 seconds
- 1.4 seconds
- 1.6 seconds
Solution: (C ) 1.4 seconds
Explanation
There will be two stall cycles, or delay slots, in the pipeline's third stage.
There are 109 instructions in total.
Conditional branches account for 20% of the 109 branches.
As a result, the cycle penalty equals 0.2 * 2 * 109 = 4 * 109.
The clock speed is 1 GHz, and each instruction takes one cycle on average.
Total execution time = (109 / 109) + 4 * (108 / 109) = 1.4 sec
As a result, the program's total execution time is 1.4 seconds.
Question 9: A 4-stage pipeline has the stage delays as 150, 120, 160 and 140 nanoseconds respectively. Registers that are used between the stages have a delay of 5 nanoseconds each. Assuming constant clocking rate, the total time taken to process 1000 data items on this pipeline will be
GATE CS 2004
- 120.4 microseconds
- 160.5 microseconds
- 165.5 microseconds
- 590.0 microseconds
Solution: (C ) 165.5 microseconds
Explanation
The time between each stage is 5 nanoseconds.
The total delay for the first data item is 165*4 = 660 milliseconds.
The first data item will take 660 ns to complete, and the next 999 data items will take the maximum of all phases, which is 160 ns + 5 ns register delay.
Total Delay = 660 + 999*165 ns, equating to 165.5 microseconds.
Question 10: For a pipelined CPU with a single ALU, consider the following situations
1. The j + 1-st instruction uses the result of the j-th instruction
as an operand
2. The execution of a conditional jump instruction
3. The j-th and j + 1-st instructions require the ALU at the same
time.
GATE CS 2003
- 1 and 2 only
- 2 and 3 only
- 3 only
- All of above
Solution: (D) All the above
Explanation
Case 1: Is reliant on data. With a single ALU, this can't be safe, therefore read after write. Case 2: Conditional leaps are inherently dangerous since they introduce conditional dependency into the pipeline.
Case 3: This is a dangerous write after read problem or concurrency dependency. All three are dangerous.
As a result, option (D) is the best choice.
Question 11: A pipelined processor's performance suffers if:
GATE CS 2002
- the pipeline stages have different delays
- consecutive instructions are dependent on each other
- the pipeline stages share hardware resources
- all of the above
Solution: (D) All the above
Explanation
Pipelining is a way of running a program by splitting it down into numerous distinct steps. In that situation, pipeline stages can't have varied delays, there can't be any dependencies between subsequent instructions, and there shouldn't be any hardware resource sharing. As a result, option (D) is correct.
Question 12: Comparing the time T1 taken for a single instruction on a pipelined CPU with time T2 taken on a non pipelined but identical CPU, we can say that
GATE CS 2000
- T1 <= T2
- T1 >= T2
- T1 < T2
- T1 is T2 plus the time taken for one instruction fetch cycle
Solution: (B) T1 >= T2
Explanation
- A single instruction's execution time is not increased by pipelining. By processing instructions in numerous pipeline stages, it improves overall speed. In both pipelined and non-pipelined CPUs, we assume that each stage takes 'T' unit of time. Let the total stages in a pipelined CPU equal the total stages in a non-pipelined CPU = K, and the number of instructions = N = 1.
- Total time (T1) = (K + (N - 1))* T = KT on a pipelined CPU
- Total time (T2) = KNT = KT on a non-pipelined CPU T1 >= T2 when buffer delays in a pipelined CPU are taken into account. As a result, option (B) is the correct answer.
Question 13: The most appropriate matching for the following pairs is
| X: Indirect Addressing | 1: Loops |
| Y: Immediate Addressing | 2: Pointers |
| Z: Auto decrement addressing | 3: Constraints |
GATE CS 2000
- X-3, Y-2, Z-1
- X-1, Y-3, Z-2
- X-2, Y-3, Z-1
- X-3, Y-1, Z-2
Solution: (C ) X-2, Y-3, Z-1
Explanation
The instruction in indirect addressing mode does not have the address of the data to be operated on, but it points to where the address is stored (it is indirectly specifying the address of memory location where the data is stored or to be stored) The data to be used is instantly delivered in the instruction itself in immediate addressing mode, hence it works with constant data. Before determining the effective address in Auto Decrement addressing mode, the value in the base register is decremented by the size of the data item to be retrieved. This addressing method can be used to move backwards through all the elements of an array or vector within a loop. As a result, option (C) is the best choice.
Question 14: Consider a non-pipelined processor with a clock rate of 2.5 gigahertz and average cycles per instruction of four. The same processor is upgraded to a pipelined processor with five stages; but due to the internal pipeline delay, the clock speed is reduced to 2 gigahertz. Assume that there are no stalls in the pipeline. The speed up achieved in this pipelined processor is
GATE CS 2015
- 3.2
- 3.0
- 2.2
- 2.0
Solution: (A) 3.2
Explanation
ExecutionTimeOld / ExecutionTimeNew = Speedup
ExecutionTimeOld = CPIOld * CycleTimeOld [Here CPI stands for Cycles Per Instruction] = CPIOld * CycleTimeOld = 4 * 1/2.5 Nanoseconds = 1.6 ns
CPInew can be expected to be 1 on average because there are no stalls.
CPInew * CycleTimenew = ExecutionTimeNew
= 1 * 1/2
= 0.5
Speedup = 1.6 / 0.5 = 3.2
Question 15: In an enhancement of a design of a CPU, the speed of a floating point unit has been increased by 20% and the speed of a fixed point unit has been increased by 10%. What is the overall speedup achieved if the ratio of the number of floating point operations to the number of fixed point operations is 2:3 and the floating point operation used to take twice the time taken by the fixed point operation in the original design?
GATE IT 2004
- 1.155
- 1.185
- 1.255
- 1.285
Solution: (A) 1.155
Explanation
Time spent on the original design vs. time spent on the upgraded design
Original concept:
The floating point to fixed point operations ratio is 2:3.
As a result, let 2n be the number of floating point operations and 3n be the number of fixed point operations.
The time it takes to do a floating point operation compared to a fixed point operation is 2:1.
Assume that the time taken by a floating point operation is 2t and the time taken by a fixed point operation is t.
The original design took (2n * 2t) + (3n * t) = 7nt of time.
In an enhanced design, the time taken for a floating point operation would be 83.33 percent of the original time (original time/1.2) as the speed of the floating point operation is raised by 20% (1.2 * original speed). (This is due to the fact that CPU speed(S) is inversely related to execution time(T), thus if speed increases to 1.2S, time becomes T/1.2.)
Similarly, if the speed of a fixed point operation is increased by 10% (1.1 * original speed), the time taken now is 90.91 percent of the original time (original time / 1.1) for the fixed point operation.
2n * 2t /1.2) + (3n * t /1.1) = 6.06nt time taken by upgraded design
1.155 = 7nt / 6.06nt speed up
Question 16: We have two designs D1 and D2 for a synchronous pipeline processor. D1 has 5 pipeline stages with execution times of 3 nsec, 2 nsec, 4 nsec, 2 nsec and 3 nsec while the design D2 has 8 pipeline stages each with 2 nsec execution time How much time can be saved using design D2 over design D1 for executing 100 instructions?
GATE IT 2005
- 214 nsec
- 202 nsec
- 86 nsec
- -200 nsec
Solution: (B) 202 nsec
Explanation
(k + n – 1) = total execution time * maximum number of clock cycles Where k represents the total number of stages and n represents the total number of instructions.
For D1 : k = 5 and n = 100 Maximum clock cycle = 4ns Total execution time = (5 + 100 - 1) * 4 = 416
For D2 : k = 8 and n = 100 Each clock cycle = 2ns Total execution time = (8 + 100 - 1) * 2 = 214
Thus, time saved using D2 over D1 = 416 – 214 =202
Thus, option (B) is correct.
Question 17: The stage delays in a 4-stage pipeline are 800, 500, 400 and 300 picoseconds. The first stage (with delay 800 picoseconds) is replaced with a functionally equivalent design involving two stages with respective delays 600 and 350 picoseconds. The throughput increase of the pipeline is _______ percent.
GATE CS 2016
- 33 or 34
- 30 or 31
- 38 or 39
- 100
Solution: (A) 33 or 34
Explanation
Throughput of 1st case T1: 1/max delay =1/800
Throughput of 2nd case T2: 1/max delay= 1/600
%age increase in throughput: (T2-T1)/T1
= ( (1/600) - (1/800) ) / (1/800)
= 33.33%
Question 18: A processor has 40 distinct instructions and 24 general purpose registers. A 32-bit instruction word has an opcode, two register operands and an immediate operand. The number of bits available for the immediate operand field is ____________.
GATE CS 2016
- 16
- 8
- 4
- 32
Solution: (A) 16
Explanation
For 40 separate instructions, 6 bits are required (since 32 <40 <64). For 24 general purpose registers, 5 bits are required (since 16<24<32). An opcode (6 bits), two register operands (10 bits), and an immediate operand make up a 32-bit instruction word (x bits). x = 32 - (6 + 10) = 16 bits is the number of bits available for the immediate operand field.
Question 19: Suppose the functions F and G can be computed in 5 and 3 nanoseconds by functional units UF and UG, respectively. Given two instances of UF and two instances of UG, it is required to implement the computation F(G(Xi)) for 1 <= i <= 10. ignoring all other delays, the minimum time required to complete this computation is ________________ nanoseconds.
GATE CS 2016
- 28
- 20
- 18
- 30
Solution: (A) 28
Explanation
Pipelining is a programming technique in which many instructions are executed at the same time. The stages are connected in a pipe, with instructions entering at one end, progressing through the steps, and exiting at the other. Pipelining does not reduce the time it takes to execute individual instructions. Instead, it boosts the rate at which instructions are processed. The frequency with which an instruction exits the instruction pipeline determines its throughput. Pipelining employs the same concept. The bottleneck is UF, which takes 5 ns while UG just takes 3 ns. We have ten such calculations to complete, and there are two instances of UF and UG, respectively. Because there are two functional units, each unit has a total of five units to work with.
Assume computation begins at 0 seconds, which means G begins at 0 and F begins at 3 seconds, since G completes the first element at 3 seconds. UF can thus be completed in 5*10/2=25 nanoseconds. For the first 3 ns, UF must wait for UG output, but the rest is pipelined, thus there is no need to wait. As a result, the answer is 3+25=28. Nitika Bansal submitted this solution. Another option is to: Because there are two functional units, each unit has a total of five units to work with. Assume computation begins at 0 seconds, which means G begins at 0 and F begins at 3 seconds, since G completes the first element at 3 seconds. 3 + 5*5 = 28 is the time when F finishes computing.
Question 20: Which of the following claims concerning relative addressing mode is FALSE?
GATE IT 2006
- It enables reduced instruction size
- It allows indexing of array elements with same instruction
- It enables easy relocation of data
- It enables faster address calculations than absolute addressing
Solution: (D) It enables faster address calculations than absolute addressing
Explanation
Relative addressing cannot be faster than absolute addressing since relative addresses are calculated from absolute addresses.
FAQs
How addressing mode affects the instruction pipelining?
Performance degradation in an instruction pipeline could be caused by address dependency, in which the operand address cannot be determined without the information required by the addressing mode.
What is the purpose of addressing modes?
An addressing mode describes how to determine an operand's effective memory address using data stored in registers and/or constants within a machine instruction or elsewhere.
How does the pipeline increase the performance of the processor?
When pipelining is used, the CPU starts executing a second instruction before the first one is finished. Because the CPU does not have to wait for one instruction to complete the machine cycle, pipelining allows for faster processing.
Why are addressing modes required in microcontrollers?
An approach to address an operand is to use the addressing mode. The data we're working with is referred to as the operand (in most cases source data). It can be a memory address, a register name, or any numerical data, among other things. I'll demonstrate this with an 8051 data move instruction.
What is interrupt pipelining?
Interrupt pipelining is a lightweight solution based on the introduction of a distinct, high-priority execution stage for instantly performing out-of-band interrupt handlers upon IRQ reception, which cannot be delayed by in-band, main kernel operations.


 8+ registered
8+ registered 

