


























Introduction
We hear a lot about deep learning-based language translation, in which a neural network learns a mapping from one language to another. Google Translate uses it to translate into over 100 languages. Is it possible to perform a similar process with images? Yes, absolutely! It will be possible to convert one image to another language if it is possible to capture the complexities of languages. This demonstrates the power of deep learning.
The regulated conversion of a given source image to a target image is known as image-to-image translation. Converting black-and-white images to color photographs is one example. The image-to-image translation is a complex topic that frequently necessitates specialized models and loss functions tailored to a specific translation task or dataset.
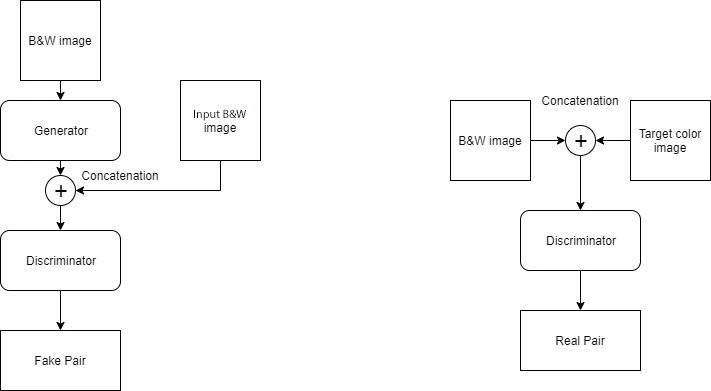
A general technique for image-to-image translation is the Pix2Pix GAN. It's based on the conditional generative adversarial network, which generates a target image based on a given input image. The Pix2Pix GAN adjusts the loss function in this scenario so that the generated image is both credible in the target domain's content and a plausible translation of the input image.
In 2016, the Pix2Pix GAN article was published. In 2018, it was changed again. When it was first published, internet people responded in kind. They used the pix2pix GAN system to a range of scenarios, including a frame-by-frame translation of a video of one person to another, emulating the movements of the former. Isn't it cool? We can map any image to any other image using pix2pix, such as the edges of an object to the image of the item. We'll also take a closer look at its architecture and how it works. Now, let's get started!
The problem of Image-to-Image Translation
The difficulty of transforming a given image precisely or controlled way is known as image-to-image translation.
Two examples are translating a landscape photograph from day to night or a segmented image to a picture. We describe automatic image-to-image translation as the challenge of translating one possible representation of a scene into another, given adequate training data, in the same way, that automatic language translation is defined. It's a complex problem that usually necessitates the creation of a specialized model and hand-crafted loss function specific to the type of translation work at hand.
Traditional approaches use per-pixel classification or regression models, which have the drawback of each predicted pixel is independent of the pixels predicted before it, potentially missing the image's larger structure.
In an ideal world, a universal technique, that is, one that can use the same general model and loss function for a variety of image-to-image translation jobs.


 8+ registered
8+ registered 

