Do you think IIT Guwahati certified course can help you in your career?
Introduction
Postorder traversal is a method for visiting all nodes in a binary tree. It follows a specific order: left subtree, right subtree, then root node. This "left-right-root" approach is useful in scenarios where child nodes must be processed before their parents, such as in tree deletion operations or evaluating mathematical expressions. This blog post will explain how postorder traversal works, and its implementation.
Unlike linear data structures (Array, Linked List, Queues, Stacks, etc.), which can only be traversed in one logical manner, trees can be traversed in various ways, which are:
Depth-First Traversal: In depth-first search (DFS Algorithm), the search tree is deepened as much as possible before going to the next sibling.
Breadth-First Traversal: In Breadth-first search(BFS), the nodes are traversed in a level-wise order.
Although there is a possibility to perform a post-order traversal of the binary tree recursively, in this article we’ll be exploring post-order traversal using the Iterative approach, which will use stacks to perform the traversal of the tree.
A binary tree postorder traversal is a method of listing all of the tree's leaves and nodes so that for each node, all of its left children come before all of its right children, which come before the node itself. In simple words, Postorder traversal is a binary tree traversal approach in which you visit the left subtree first, then the right subtree, and finally the root.
LeftSubtree -> RightSubtree -> Root
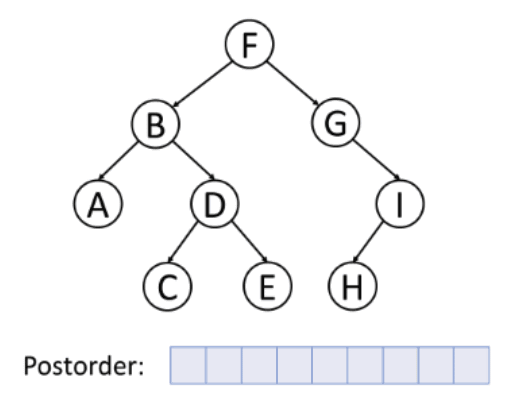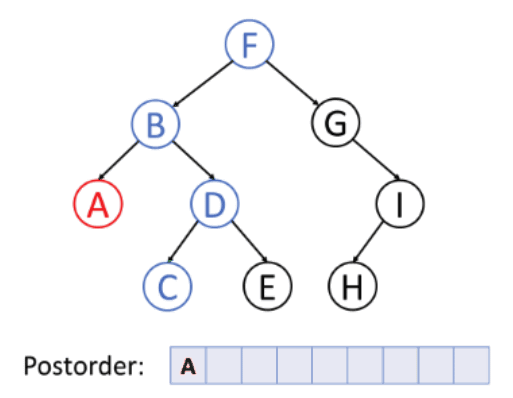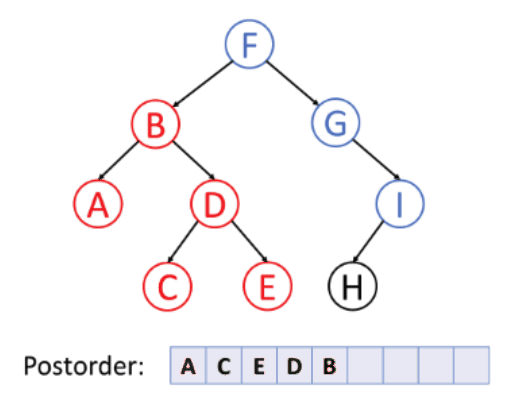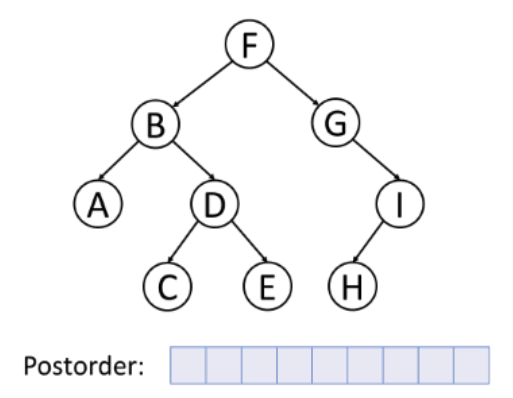
Consider the following example of a binary tree traversal utilizing the post order.
In the preceding example, because the leftmost node is A, it is visited first. Following that, since D is the root node of C and E, the nodes C and E will be visited before the D node. The B node is now the last one to be visited in the left subtree. Now, the left subtree is visited, and because the algorithm expects the root to be visited last, it moves to the right subtree and processes each node in the same manner as it did for the left subtree.
Now that you are familiar with postorder traversal let’s look at the approaches we can perform to traverse a binary tree. As we are attempting to traverse the tree iteratively, thus we’ll be needing an auxiliarystack to process each node.
In postorder traversal, we visit the left subtree, then the right subtree, and finally the root node. Let's walk through this tree:
Start at the root (1).
Go to the left child (2).
Go to its left child (4). It has no children, so we visit it. Output: 4
Go back to 2, then to its right child (5). It has no children, so we visit it. Output: 4, 5
We've finished both subtrees of 2, so we visit 2. Output: 4, 5, 2
Go back to the root (1), then to its right child (3). It has no children, so we visit it. Output: 4, 5, 2, 3
Finally, we've finished both subtrees of the root, so we visit the root (1).
Final output: 4, 5, 2, 3, 1
This order ensures that for any node, both its left and right subtrees are fully traversed before the node itself is visited.
Algorithm of Postorder Traversal
Below is the algorithm for the postorder traversal of all the nodes of the binary tree:
Step 1: Check if the current node is NULL; if yes, return.
Step 2: Traverse the left subtree recursively.
Step 3: Traverse the right subtree recursively.
Step 4: Visit the current node.
Step 5: END
This algorithm can be implemented using either recursion or an iterative approach. The recursive approach is typically easier to understand, while the iterative approach can be more efficient in some cases.
When using Recursion to perform a postorder traversal, the algorithm maintains a call stack that stores the nodes that still need to be visited. The stack is initially populated with the root node of the tree, and the algorithm continues until the stack is empty.
How PostOrder traversal of the Binary tree works?
Postorder traversal of a binary tree is a recursive algorithm that visits the nodes in the following order:
Traverse the left subtree.
Traverse the right subtree.
Visit the root node.
Here are the steps involved in performing a postorder traversal of a binary tree:
Recursively traverse the left subtree using postorder traversal.
Recursively traverse the right subtree using postorder traversal.
Visit the current node and perform any desired operations.
Now, let's look at an example of Postorder traversalconsidering the following tree:
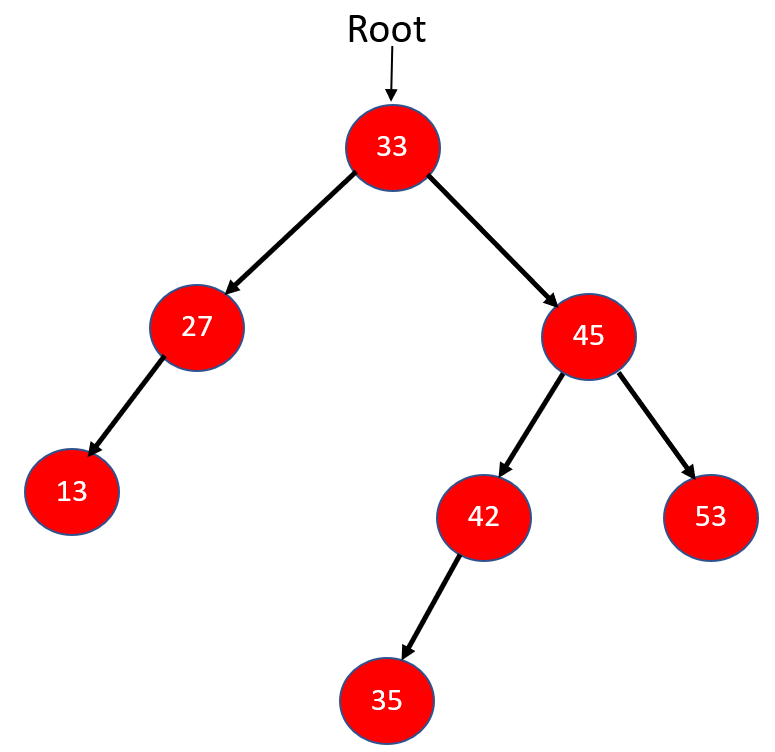
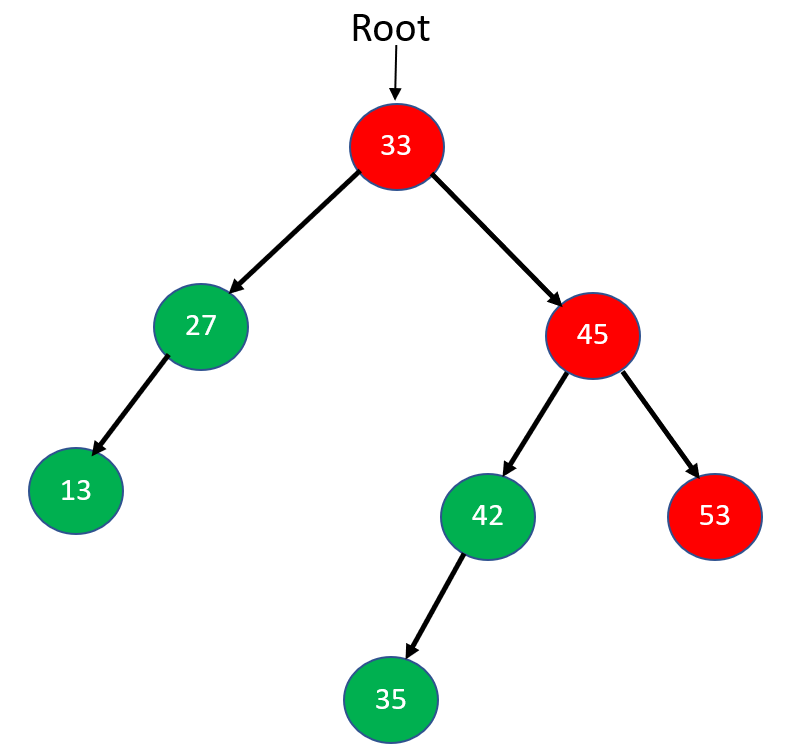
In the below image, we have a binary tree with all non-visited nodes. Now, let us traverse the tree using Postorder Traversal.
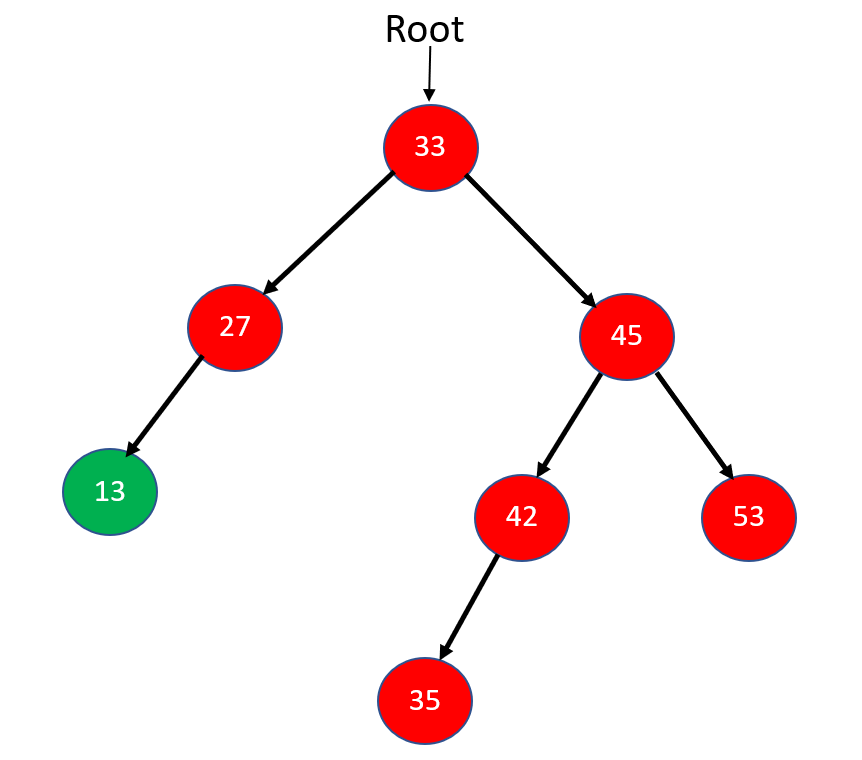
Step 1: In the above example, 33 is the root node from where we are going to start our traversal. Firstly, we will traverse to the left subtree of node 33, i.e., 27. Again, node 27 will traverse in Postorder to its left subtree 13. Now, node 13 has no left or right subtree, so let's print 13 and mark it as visited and move up towards 27.
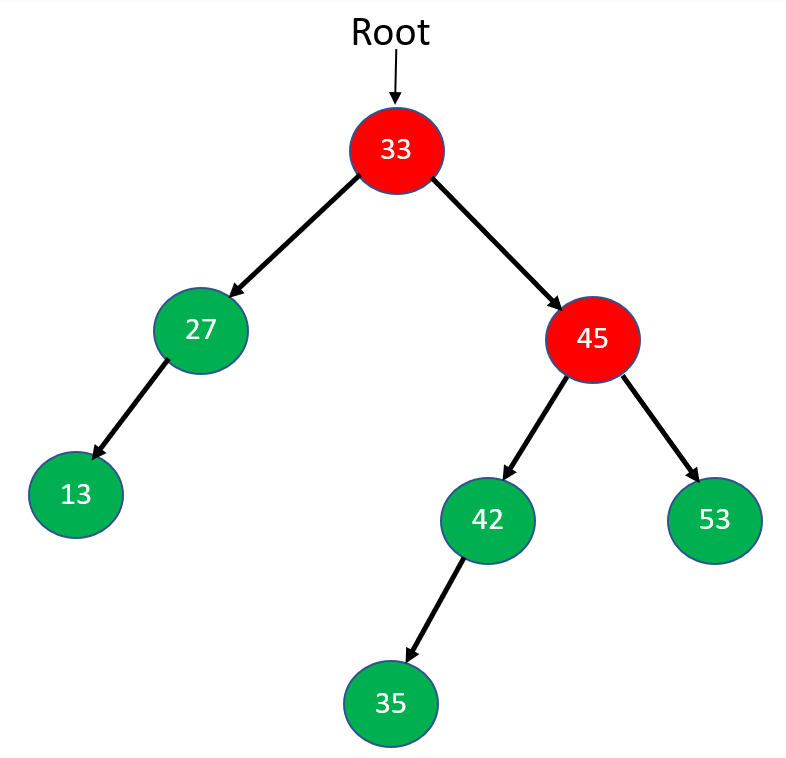
Step 2: Node 27 has no right subtree; therefore, we will mark 27 visited, print it and move up toward the right subtree of root node 33.
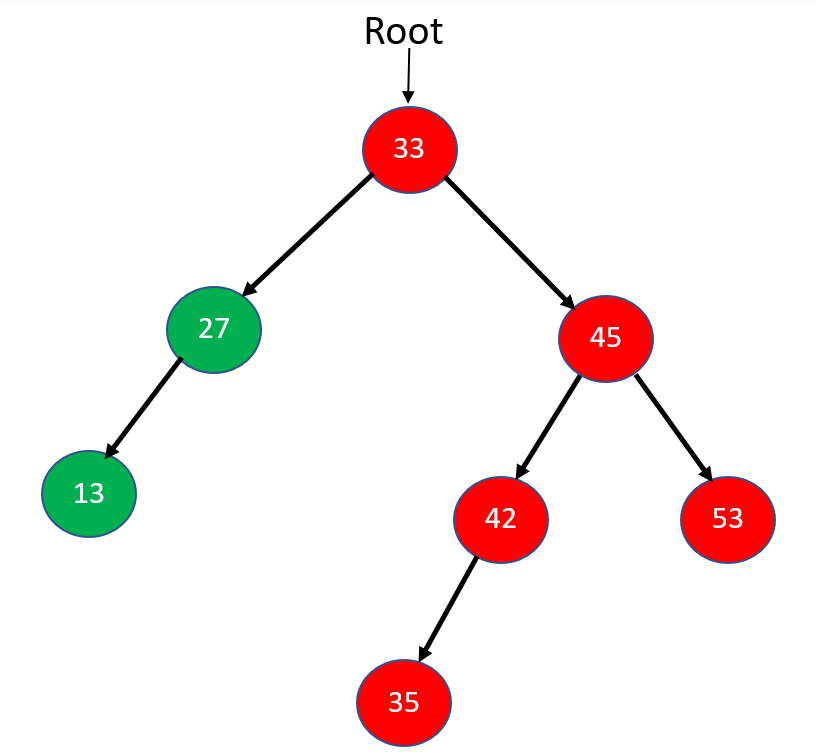
Step 3: Now, node 45 will also follow the Postorder sequence and will go toward left subtree 42. Again, 42 will go towards its left subtree 35. As 35 has no subtrees, we will print it and mark it visited and then move up towards node 42.
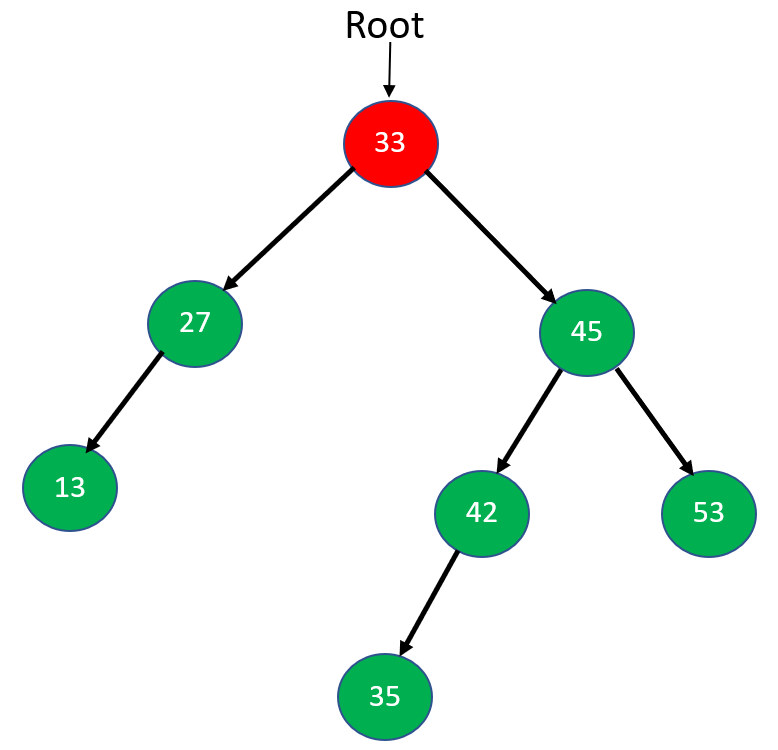
Step 4: Now, node 42 has no right subtree. Thus we will mark it visited, print it and then move up towards node 45.
Step 5: Node 45 will go towards its right subtree 53. Now, 53 has no left or right subtree. So, we mark it visited and move back towards node 45 again.
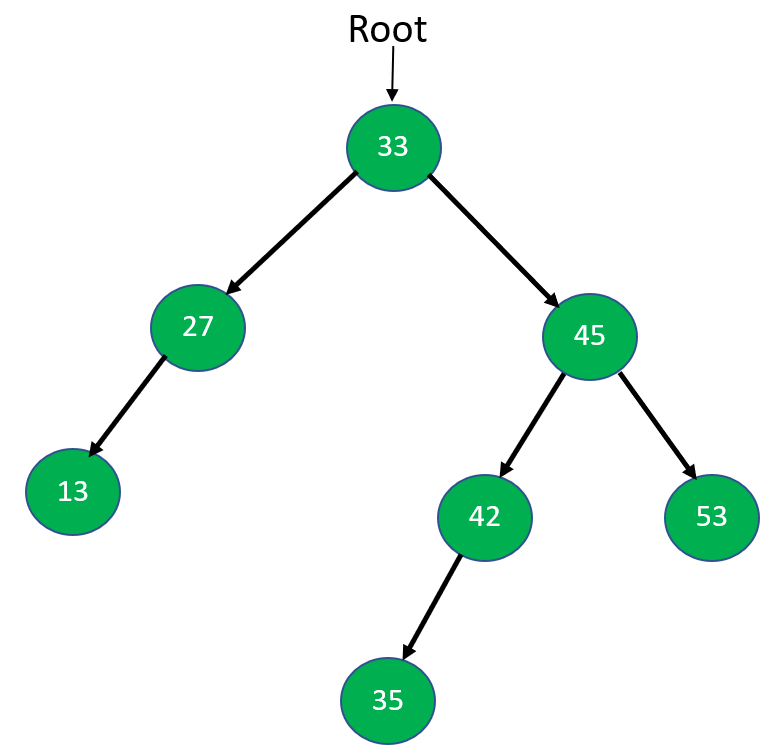
Step 6: Now both subtrees of 45 are visited, so we will mark 45 visited and go up toward the root node 33.
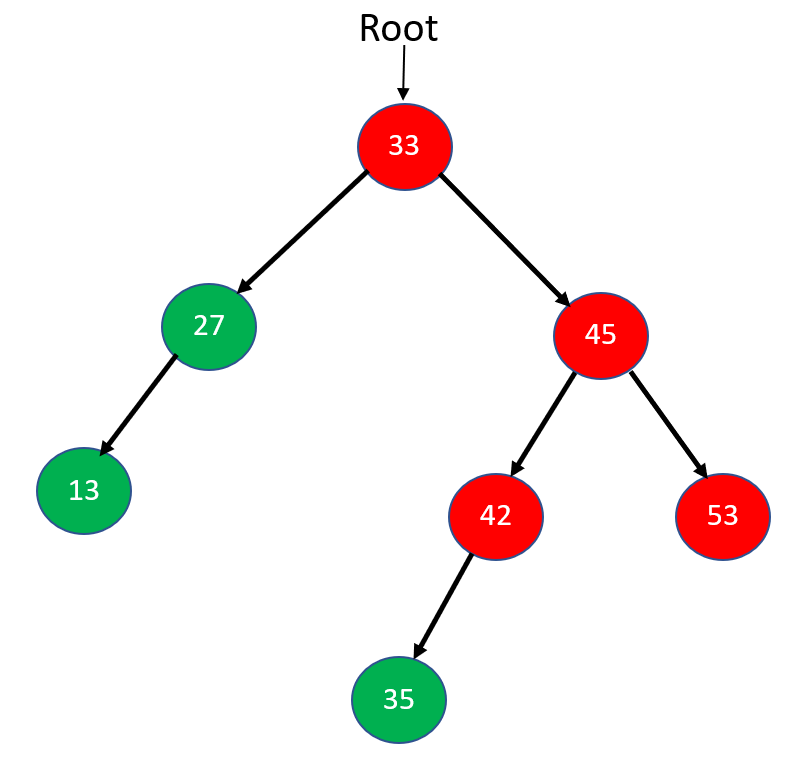
Step 7: Now, at last, both subtrees of node 33 are visited. So, mark 33 visited and print it, and our Postorder traversal is finished.
The final output of Postorder traversal: [13, 27, 35, 42, 53, 45, 33]
Approaches to implement Postorder traversal of binary -
Using two stacks: In this section, we’ll learn how two stacks can assist in traversing the binary tree.
Using one stack: This is the more efficient approach to solving this problem. We have discussed this approach in another blog.
Method 1: Using two stacks
We can use two stacks to implement the Postorder traversal. The goal is to acquire the reversed postorder elements in the stack and then pop the elements one by one from the stack, as the stack adheres to the LIFO principle. The question of how to obtain the reversed order of the postorder items emerges. This problem's answer can be reached by combining two stacks. The second stack is utilized to obtain the postorder items in reverse order.
The steps for implementing postorder utilizing two stacks are as follows:
1 - We'll start by pushing the root to the top of the stack.
2 - Second, we'll run a while loop that will keep running until the first stack becomes empty and process the below steps.
A node from the first stack is popped and pushed into the second.
Push the left and right child of the popped node to the first stack.
3 - The data from the second stack will be printed.
Consider the above example, and let’s try to understand each step in detail before moving to the Implementation:
1. Push 1 to the first stack.
First stack: 1
Second stack: Empty
2. Pop 1 from the first stack and push it to the second stack.
Push left and right children of 1 to the first stack.
First stack: 2, 3
Second stack: 1
3. Pop 3 from the first stack and push it to the second stack.
Push the left child of 3 to the first stack.
First stack: 2, 6
Second stack: 1, 3
4. Pop 6 from the first stack and push it to the second stack.
First stack: 2
Second stack: 1, 3, 6
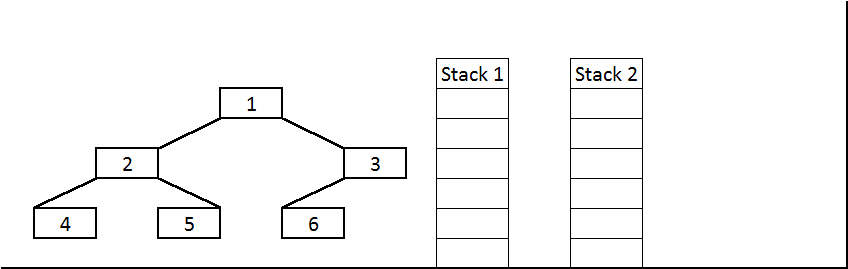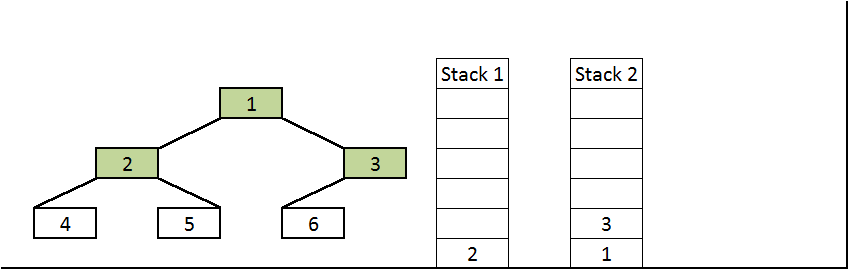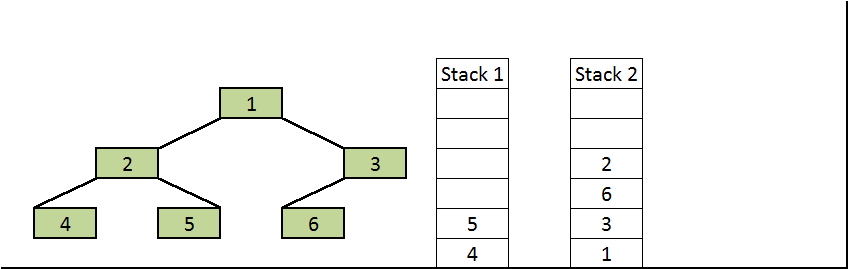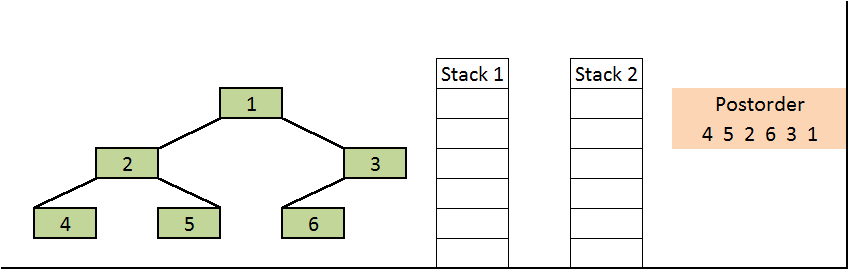
6. Pop 2 from the first stack and push it to the second stack.
Push left and right children of 2 to the first stack.
First stack: 4, 5
Second stack: 1, 3, 6, 2
7. Pop 5 from the first stack and push it to the second stack.
First stack: 4
Second stack: 1, 3, 6, 2, 5
8. Pop 4 from the first stack and push it to the second stack.
First stack: Empty
Second stack: 1, 3, 6, 2, 5, 4
The algorithm stops here since there are no more items in the first stack.
Observe that the contents of the second stack are in postorder fashion. Print them.
Algorithm
Step 1: Create two empty stacks -> stack1 and stack2.
Step 2: Push the root node on stack1.
Step 3: TreeNode* current = NULL
Step 4: while(!stack1.empty())
current = top of stack1
pop current from stack1
push current on stack2
if (current->left!= Null)
push current->left on stack1
if(current->right!=NULL)
push current->right on stack1
Step 5: while(!stack2.empty())
current = top of stack2
print current->value
pop current from the stack2
Implementation in C++
C++
C++
#include <iostream> #include <stack> using namespace std;
int main() { TreeNode* root = new TreeNode(1); root->left = new TreeNode(2); root->right = new TreeNode(3); root->left->left = new TreeNode(4); root->left->right = new TreeNode(5); root->right->left = new TreeNode(6);
Time Complexity:- The time complexity is O(n) (where n is the number of nodes in the tree) because of the work we do in the while loops.
Space Complexity:- The space complexity is O(n) (where n is the number of nodes in the tree) because of the space taken by the two stacks.
To know more about conceptual knowledge and the implementation of the code, watch this video tutorial.
Implementation in Java
Java
Java
import java.util.Stack;
class Node { int data; Node left, right;
public Node(int item) { data = item; left = right = null; } }
public class IterativePostorder { static Node root;
static void postOrderIterative(Node node) { if (node == null) return;
Stack<Node> stack1 = new Stack<>(); Stack<Node> stack2 = new Stack<>();
stack1.push(node);
while (!stack1.isEmpty()) { Node current = stack1.pop(); stack2.push(current);
if (current.left != null) stack1.push(current.left); if (current.right != null) stack1.push(current.right); }
while (!stack2.isEmpty()) { Node current = stack2.pop(); System.out.print(current.data + " "); } }
public static void main(String[] args) { root = new Node(1); root.left = new Node(2); root.right = new Node(3); root.left.left = new Node(4); root.left.right = new Node(5); root.right.left = new Node(6);
Time Complexity:- The time complexity is O(n) (where n is the number of nodes in the tree) because of the work we do in the while loops.
Space Complexity:- The space complexity is O(n) (where n is the number of nodes in the tree) because of the space taken by the two stacks.
Method 2: Using one stack
An efficient way to visit every node of a binary tree in postorder traversal order, without using recursion, is through the iterative postorder traversal method using a single stack. This algorithm simulates the recursive call stack by keeping track of nodes to visit and their order using only one stack. The process begins by initializing an empty stack and a pointer to the root of the tree. The algorithm then uses a loop to iterate through each node until all nodes have been visited or the stack is empty. In each iteration, the algorithm either pushes the current node onto the stack and moves the current node pointer to its left child or pops the top node from the stack and visits it if its right child is null or has already been visited. By eliminating the function call stack used in the recursive approach, this method improves efficiency.
Algorithm
Create an empty stack and initialize a pointer to the root of the tree.
Initialize a pointer to the last visited node to null.
Loop while the current node pointer is not null or the stack is not empty:
If the current node is not null, push it onto the stack and set the current node pointer to its left child.
If the current node is null, retrieve the top node from the stack.
If the right child of the top node is not null and not equal to the last visited node, set the current node pointer to the right child.
If the right child of the top node is null or equal to the last visited node, visit the top node, set the last visited node pointer to the top node, and pop it from the stack.
After the loop completes, the nodes of the binary tree will have been visited in postorder traversal order.
Note that this algorithm uses a single stack to simulate the recursive call stack used in the recursive implementation of postorder traversal. The key idea is to use the stack to keep track of the nodes to visit and the order in which to visit them.
Implementation in C++
C++
C++
#include <iostream> #include <stack> using namespace std;
struct Node { int data; Node* left; Node* right; };
public static void main(String[] args) { Node root = new Node(1); root.left = new Node(2); root.right = new Node(3); root.left.left = new Node(4); root.left.right = new Node(5);
Time Complexity:- The time complexity is O(n) (where n is the number of nodes in the tree) because of the work we do in the while loops.
Space Complexity:- The space complexity is O(n) (where n is the number of nodes in the tree) because of the space taken by the one stack.
Now, you have understood the approach; it’s time to implement the code on your own in your favorite programming language on Coding Ninjas Studio. Complete your turn before it’s too late.
Method 3: Iterative Approach - Using Stack and Hashing
Start at the root node.
Traverse the left subtree until reaching the leaf node.
If a node has a right child and it has not been visited before, push it onto the stack.
Once the left subtree is fully explored, move to the right subtree.
Repeat steps 2-4 until all nodes are visited.
Algorithm
Initialize an empty stack and a hash set to store visited nodes.
Push the root node onto the stack.
While the stack is not empty:
Peek at the top node.
If the top node's left child exists and has not been visited:
Push the left child onto the stack.
Otherwise, if the top node's right child exists and has not been visited:
Push the right child onto the stack.
If both children are visited or do not exist:
Pop the top node from the stack.
Print or process the node.
Add the node to the hash set to mark it as visited.
Implementation in C++
C++
C++
#include <iostream> #include <stack> #include <unordered_set> using namespace std;
// Define a binary tree node struct TreeNode { int val; TreeNode* left; TreeNode* right; TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} };
void postorderTraversal(TreeNode* root) { if (!root) return;
int main() { TreeNode* root = new TreeNode(1); root->left = new TreeNode(2); root->right = new TreeNode(3); root->left->left = new TreeNode(4); root->left->right = new TreeNode(5);
// Driver code public static void main(String[] args) { Main solution = new Main(); TreeNode root = new TreeNode(1); root.left = new TreeNode(2); root.right = new TreeNode(3); root.left.left = new TreeNode(4); root.left.right = new TreeNode(5);
Time Complexity: Time complexity is O(n) where n is the number of nodes in the binary tree because every node is visited once.
Space Complexity: Space complexity is O(n) because the worst-case scenario occurs when the binary tree is skewed and all nodes are pushed onto the stack.
Method 4: Using No Stacks (Morris Traversal)
Morris Traversal is an algorithm for traversing binary trees without using a stack or recursion. It modifies the tree temporarily to establish links from nodes to their successors. It ensures constant space complexity and linear time complexity.
Algorithm
Initialize the current node as the root.
While the current node is not null:
If the current node has no left child:
Move to the right child.
If the current node has a left child:
Find the rightmost node in the left subtree.
If the rightmost node's right child is null:
Set the right child to the current node.
Move to the left child.
If the rightmost node's right child is the current node:
Reset the right child to null.
Print or process the current node.
Move to the right child.
Implementation in C++
C++
C++
#include <iostream> using namespace std;
// Define a binary tree node struct TreeNode { int val; TreeNode* left; TreeNode* right; TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} };
void postorderMorrisTraversal(TreeNode* root) { TreeNode* current = root;
while (current != nullptr) { if (current->right == nullptr) { cout << current->val << " "; current = current->left; } else { TreeNode* predecessor = current->right;
if (predecessor->left == nullptr) { predecessor->left = current; current = current->right; } else { predecessor->left = nullptr; cout << current->val << " "; current = current->left; } } } }
int main() { TreeNode* root = new TreeNode(1); root->left = new TreeNode(2); root->right = new TreeNode(3); root->left->left = new TreeNode(4); root->left->right = new TreeNode(5);
cout << "Postorder traversal using Morris Traversal: "; postorderMorrisTraversal(root);
return 0; }
You can also try this code with Online C++ Compiler
if (predecessor.left == null) { predecessor.left = current; current = current.right; } else { predecessor.left = null; System.out.print(current.val + " "); current = current.left; } } } }
public static void main(String[] args) { Main solution = new Main(); TreeNode root = new TreeNode(1); root.left = new TreeNode(2); root.right = new TreeNode(3); root.left.left = new TreeNode(4); root.left.right = new TreeNode(5);
System.out.print("Postorder traversal using Morris Traversal: "); solution.postorderMorrisTraversal(root); } }
You can also try this code with Online Java Compiler
Postorder traversal using Morris Traversal: 3 1 5 2 4
Time Complexity: Time complexity is O(n) because each node is visited at most twice: once to establish links and once to traverse the tree.
Space Complexity: Space complexity is O(1) because no extra space is used other than the input tree itself. This method achieves constant space complexity.
Advantages and disadvantages of Postorder traversal
Listed below are examples outlining the advantages and disadvantages of postorder traversal.
Advantages
It can be used to delete a binary tree from memory because it visits the child nodes before the parent nodes.
It can be used to evaluate arithmetic expressions in postfix notation because the operators are encountered after their operands.
It can be used to find the height of a binary tree because the height of a node is equal to the maximum height of its child nodes plus one.
It can be used to implement certain types of binary tree balancing algorithms because it allows for easy computation of balance factors and subtree heights.
Disadvantages
It is more complex than preorder and inorder traversals and can be more difficult to implement and understand.
Postorder traversal requires additional memory to maintain the call stack, which can be a problem for very large trees.
It may not be the most efficient traversal method for certain use cases, as it can result in a larger number of cache misses and branch mispredictions than other methods.
In some cases, postorder traversal may not be necessary or desirable for a particular application or problem.
Use Cases of Postorder Traversal
1. Deleting or Freeing Nodes in a Tree: Postorder traversal processes the children before the parent node, making it suitable for tasks like deleting or freeing memory for all nodes in a tree. It ensures that child nodes are deleted before their parent.
2. Expression Tree Evaluation: In an expression tree, postorder traversal is used to evaluate the expression. It processes operators only after the operands (children) are evaluated, which aligns with the structure of postfix expressions.
3. Generating a Postfix Expression from a Parse Tree: Postorder traversal can be used to convert an expression represented as a parse tree into its postfix notation. This traversal ensures that operands are processed before operators.
4. Dependency Resolution (Build Systems): Postorder traversal can be used in systems like build tools (e.g., Makefile) to resolve dependencies. Dependencies (child nodes) are resolved first before processing the task (parent node).
5. Directory Size Calculation in File Systems: To calculate the size of a directory, postorder traversal can be used to process the sizes of subdirectories first, before calculating the size of the parent directory by summing its contents.
6. Tree-based Algorithms: Algorithms that require processing child nodes before their parent node, such as finding the height of a tree or balancing nodes in AVL trees, can benefit from postorder traversal.
Frequently Asked Questions
What is Postorder traversal expression?
Postorder traversal is a tree traversal method where the nodes are visited in the order: Left subtree, Right subtree, and then the Root node.
What is Postorder traversal sequence?
The Postorder traversal sequence is left-right-root, i.e., start from the left subtree followed by the right subtree and then the root node.
Where does Postorder traversal start?
Postorder traversal starts at the root node and visits the left subtree, the right subtree, and finally, the root.
What is the function of Postorder?
The function of Postorder is to visit nodes in a binary tree and process child nodes before their parent.
How do you find the Postorder traversal of the binary tree?
To find the Postorder traversal of a binary tree, start from the root node, then recursively traverse the left subtree followed by the right subtree, and finally visit the root of the tree.
Why is it called post-order traversal?
Postorder traversal is called postorder because it visits the root node of the tree at last after visiting the left and right subtree.
When to use postorder traversal?
If you know you need to inspect all the leaves before any nodes, you choose post-order, so you don't waste time inspecting roots in search of leaves.
Conclusion
To summarize, we’ve covered the tree traversal iteratively using the postorder DFS based on LRR( Left right root) algorithm. The postfix expression of an expression tree can be obtained using postorder traversal. Moreover, postorder traversal is also used when there is a need to visit the child nodes before the Root node. Postorder traversal is complicated among all the other traversals but is efficiently utilized in computer science. Along with that, a tree can be deleted from leaf to Node by using the postorder traversal.
































 9+ registered
9+ registered 
