


























Introduction
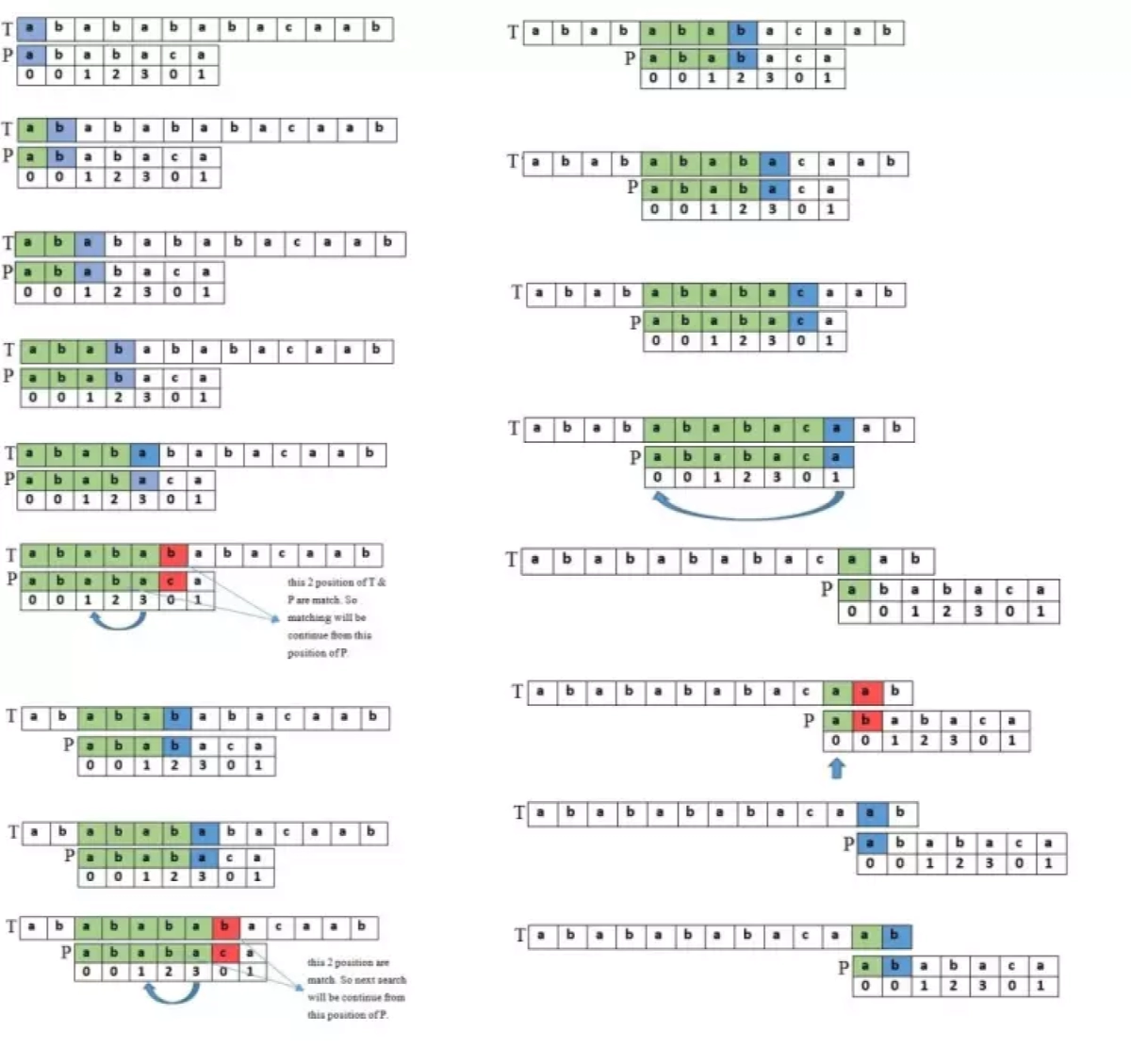
KMP is the most popular substring search algorithm in linear time. This algorithm is used for finding linear time solutions of various string-related problems such as searching substring in a string, the number of unique substrings in a string, pattern matching problem, etc.
Algorithm
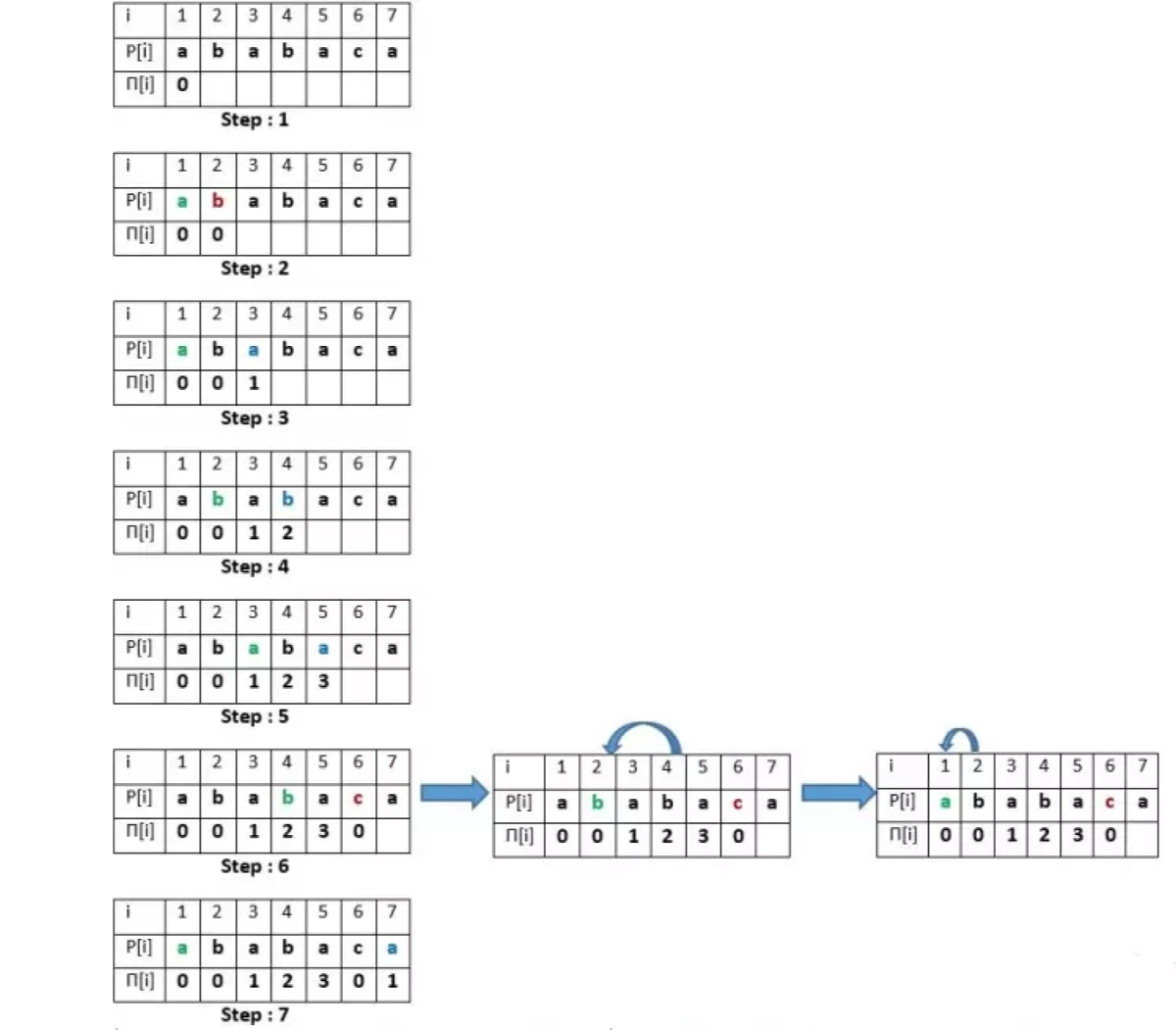
The main component of the KMP algorithm is the prefix function. It is defined as for a string s of length n, π[i] is the length of the longest proper prefix of the substring s[0…i], which is also a suffix of this substring where the proper prefix of a string is a prefix that is not equal to the string itself. π[i] is the ith element of an n-length array π. By definition, π[0]=0.
π[i]= max
k=0...i
k : s[0…k−1]=s[i−(k−1)…i],
where s[0…k−1] is the proper prefix and s[i−(k−1)…i] is the suffix of length k of the string s.
e.g for string "ababaca", prefix function array π is [0,0,1,2,3,0,1]


 9+ registered
9+ registered 

