Do you think IIT Guwahati certified course can help you in your career?
Introduction
Hey Readers!!
Welcome back to another article related to Python. While working on Python, you've come across different Python Libraries like Numpy, Pandas, Keras, and many more.
So in this article, you'll learn about one of those libraries used in machine learning called scikit-learn and how the preprocessing is done in scikit-learn.
Let’s begin!!
Data Preprocessing
Data Preprocessing is a technique that converts the raw data into data that can be used for analysis.
Data Preprocessing in Scikit-learn
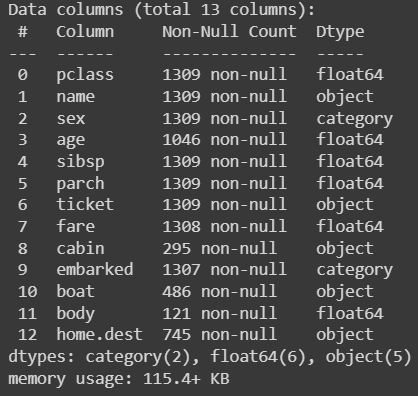
Now let's look at the steps of Data Preprocessing in Scikit-learn. In this, we'll use the Titanic Dataset for the data preprocessing.
Load data with the Scikit-learn
Load the titanic dataset using fetch_openml()
import pandas as pd
from sklearn.datasets import fetch_openml
df = fetch_openml('titanic', version=1, as_frame=True)['data']
df.head(4)
You can also try this code with Online Python Compiler
The ranges of individual attributes may vary across different datasets.
For instance, one feature may accept data in Kilometres while the other may accept it in miles.
As a result, we must normalize the data.
We can apply StandardScaler or MinMaxScaler to standardize the data.
Each feature is scaled by MinMaxScaler to a specified range.
By eliminating the mean and scaling to unit variance, StandardScaler standardized the features to haveμ= 0 and σ= 1 for each feature.
Create a LogisticRegression
In this let's create the LogisticRegression
from sklearn.datasets import fetch_openml
from sklearn.linear_model import LogisticRegression
X, y = fetch_openml('titanic', version=1, as_frame=True, return_X_y=True)
# impute missing values
X['age'].fillna(X['age'].mean(), inplace=True)
X['embarked'].fillna(X['embarked'].mode(), inplace=True)
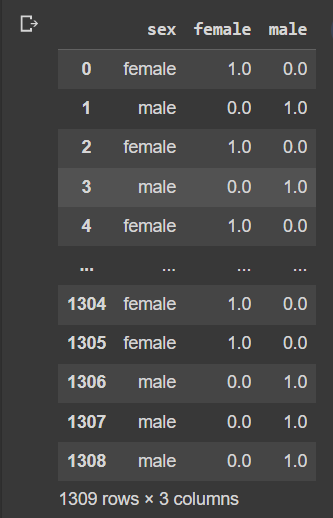
# handle categorical data
X = pd.get_dummies(X[['age','embarked', 'sex','pclass']],drop_first=True)
# fit machine learning model
model = LogisticRegression()
model.fit(X, y)
# make prediction
model.predict(X)
You can also try this code with Online Python Compiler
Let's skip the specifics and simply briefly describe what the code does.
We construct a set of actions we wish to carry out sequentially using the Pipeline class.
Frequently asked questions
What is scikit-learn used for?
In the Python ecosystem, Scikit-learn, an open-source data analysis toolkit, is considered the pinnacle of machine learning.
What is the main purpose of scikit-learn?
It offers a range of effective machine learning and statistical modeling capabilities, such as dimensionality reduction, clustering, regression, and classification.
Is scikit-learn deep learning?
A high-level wrapper for the TensorFlow deep learning library is called Scikit Flow.
Does scikit-learn use multiple cores?
Using several CPU cores, some scikit-learn estimators and tools parallelize expensive computations.
Is scikit-learn a library or module?
A free machine-learning library for Python is called Scikit-learn.
Conclusion
You understand the data preprocessing, Preprocessing with scikit-learn, and the different steps to do that.
Below are the mentioned kike that will help you out in gaining more knowledge in libraries for machine learning.





































 9+ registered
9+ registered 

