Do you think IIT Guwahati certified course can help you in your career?
Introduction
In this article, we will learn and implement Prim’s MST for Adjacency List Representation. If you are wondering what MST is, MST stands for Minimum Spanning Tree. It is a spanning tree where the sum of the weight of all the edges in a spanning tree is minimum. We will be traversing each node of the graph exactly once and calculating the minimum total cost of traversing.
To reduce this process's overall complexity, we will use an adjacency list and not a matrix for graph representation.
How will we approach the problem?
As we already know, in Prim’s algorithm, we are supposed to maintain two sets, one set contains a list of vertices that are already included in MST, and the other set contains vertices that are not yet included. If we use adjacency list representation, we can traverse all graph vertices in O(V+E) time using BFS(Breadth First Search).
So, we will traverse all vertices of the graph using BFS and then a Min Heap to store the vertices that are not yet included in our MST. We will use a Min Heap as a priority queue to acquire the minimum weight edge from the cut. Min Heap is being used as the time complexity of different operations in it is very cost-effective, like extracting minimum element and decreasing key value is O(LogV) only. We will enter all the edges along with their weights in the priority queue to always extract the edge with the minimum weight.
What will be the steps we have to follow?
We will be creating a Min Heap of pairs.
Every node of the min heap we created will contain a key value and the node.
We will initialize our Min Heap with the first node as root (the key value assigned to the first node will be 0).
We will assign the key value to all other vertices of the graph as INF (infinite).
While Min Heap is not empty, we will first extract the min value node from Min Heap.
We will name this extracted node as y.
Now for every adjacent vertex y of x, we will check if y is in Min Heap (it means whether or not it is yet included in MST).
If y is not included in the Min Heap and its key value is more than the weight of u-v, then we will update the key value of y as the weight of edge x-y.
We will continue these steps till the whole MST is not formed.
Sample Example
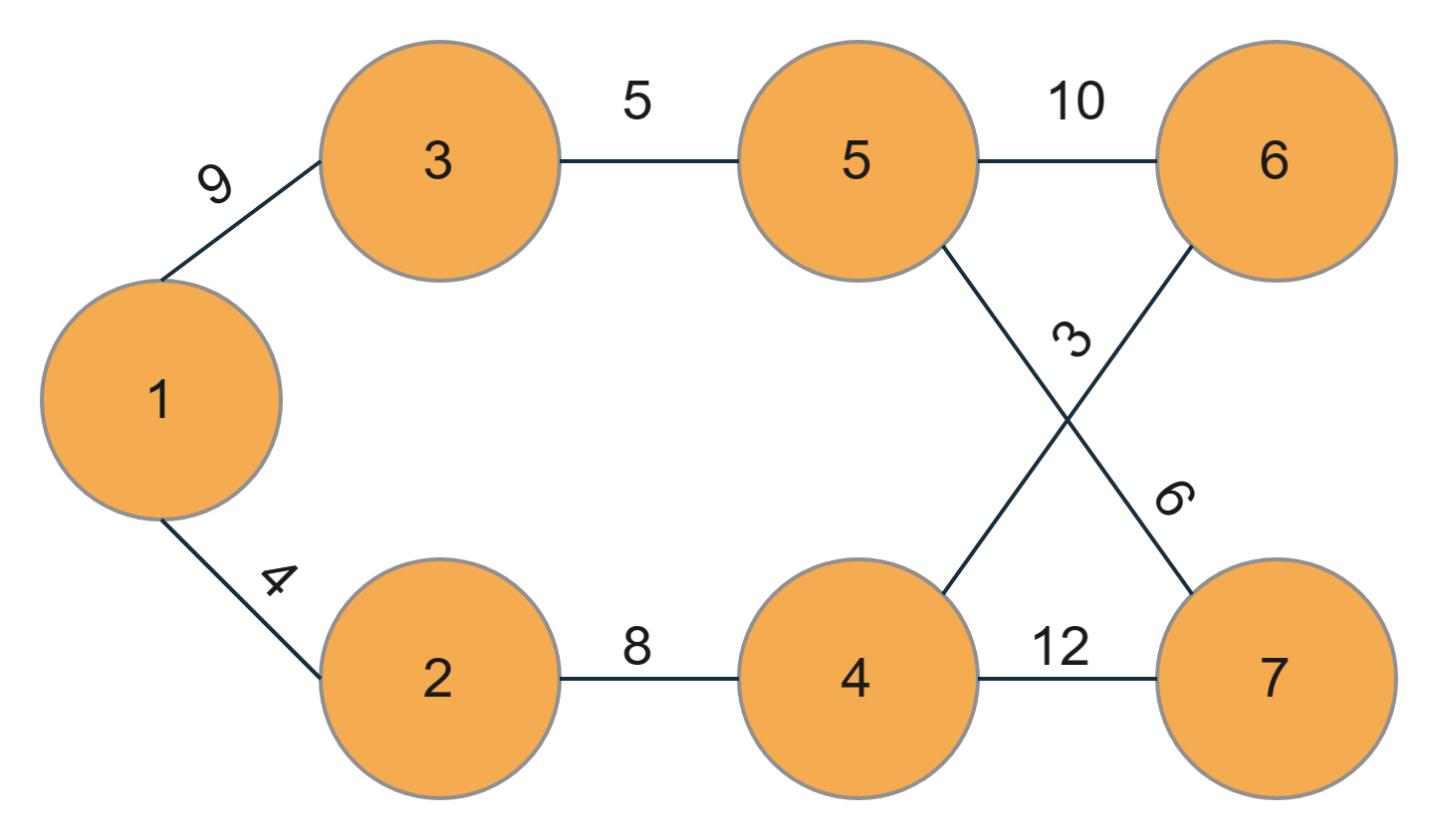
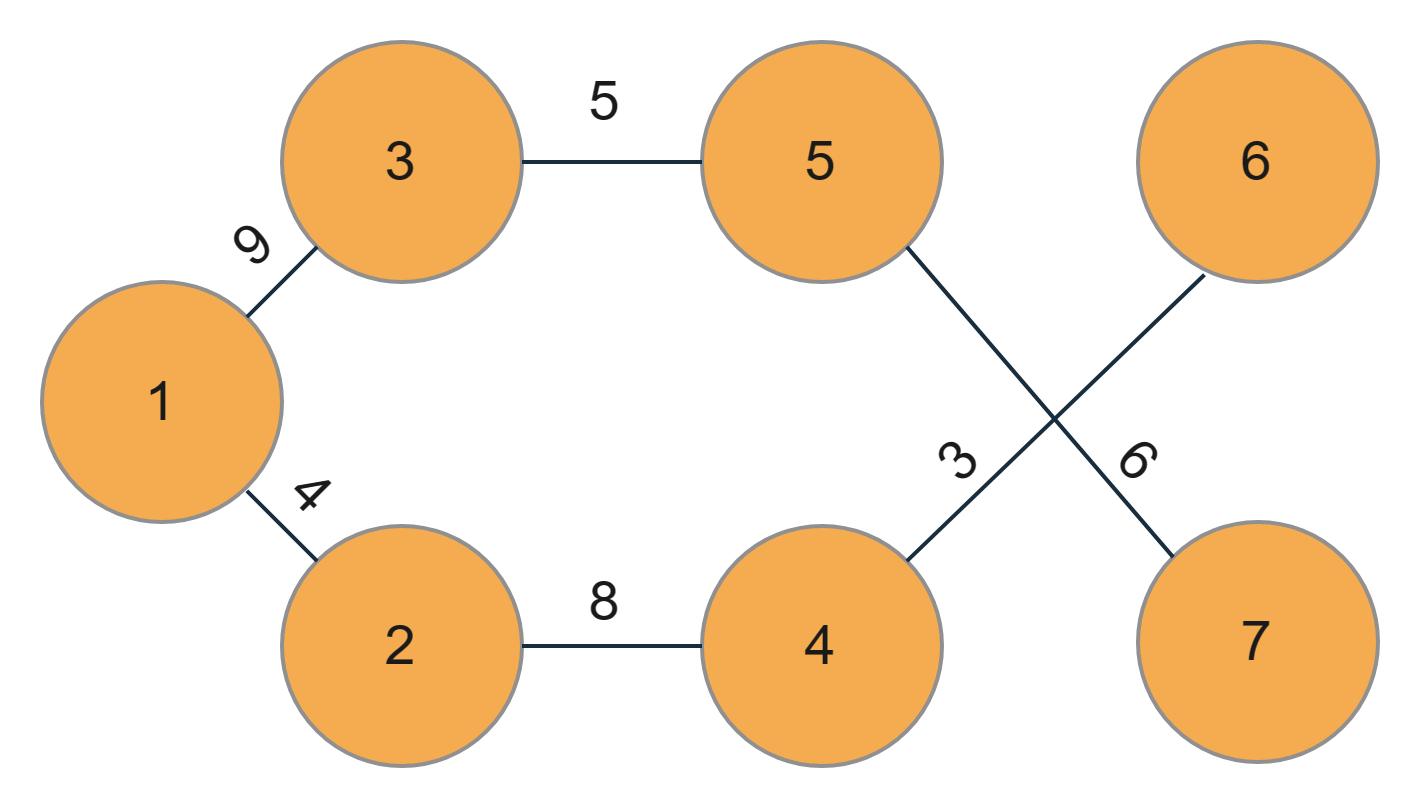
Let’s say we have a given graph as follows. We have to implement Prim’s MST for adjacency list representation in it.
So let's dry-run the above example to understand the problem better.
1. First, let us choose a node. Say we choose 1.
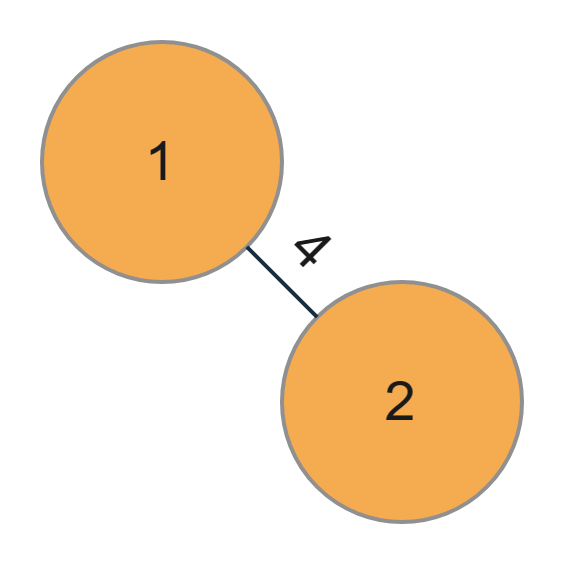
Initially, the graph would look like this,
2. Now, let us choose a minimum edge. There are two edges here, node 1 is connected to node 3 with weight 9 and the other to node 2 with weight 4. So since the edge with node 2 has less weight. Therefore, we would choose it.
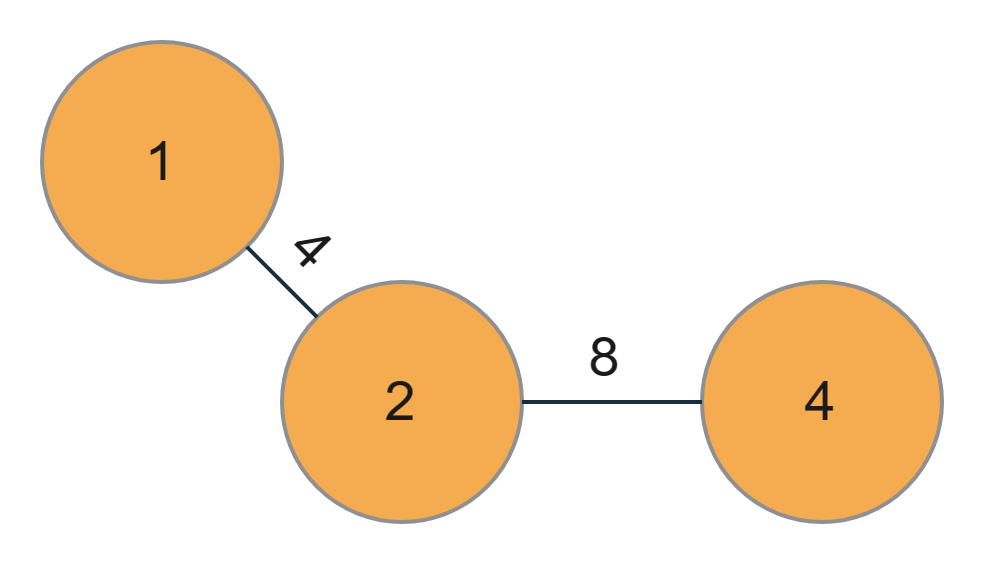
Now our graph will look like this,
3. let us repeat the above process. We again have two edges, one connected from node 1 to node 3 with weight 9 and the other from node 2 to node 4 with weight 8. So we would choose the edge with weight 8.
The graph would look like this,
4. Repeat the process. We now have three different options. The first one is the same, where the edge has a weight of 9 and is connected from node 1 to node 3. The other two would be from node 4 to node 6 and node 7 with weights 3 and 12. So, we would choose the one with weight 3.
5. Now, again, we have three options. The first one is the same, where the edge has a weight of 9 and is connected from node 1 to node 3. The other two would be from node 6 to node 5 with a weight of 10 and from node 4 to node 7 with a weight of 12. So, we would choose the one with a weight of 9
6. We have three options here. The first one is where the edge has a weight of 5 and is connected from node 3 to node 5, the other is from node 6 to node 5 with a weight of 10, and the last is from node 4 to node 7 with a weight of 12. So, we would choose the one with weight 5.
7. The first option is from node 5 to node 6 with a weight of 10, the second one is from node 5 to node 7 with a weight of 6, and the last is from node 4 to node 7 with a weight of 12. Here we choose the edge with weight 6 from node 5 to node 7.
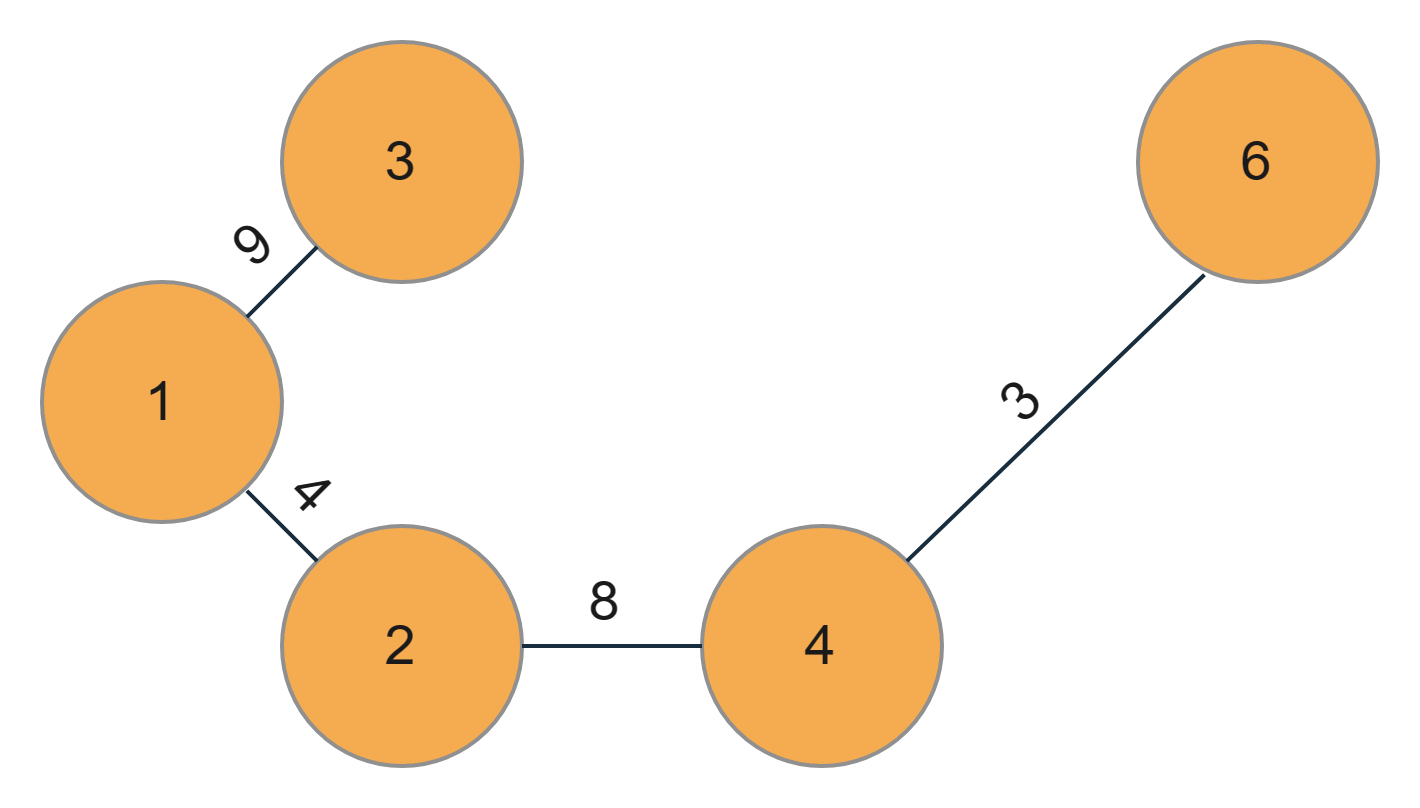
The final Prim’s MSTlooks like this,
Implementation in C++
// Implementation of Prim’s MST
#include <bits/stdc++.h>
using namespace std;
vector<pair<int, int>> adj[1001];
void push(int a, int b, int wt)
{
adj[a].push_back({b, wt});
adj[b].push_back({a, wt});
}
// function to find out Prim’s MST
void solve(int par[], int val[], bool vis[])
{
// min heap
priority_queue<pair<int, int>, vector<pair<int, int>>, greater<pair<int, int>>> pq;
val[1] = 0;
par[1] = 1;
// intially giving only node 1 to the priority queue
pq.push({0, 1});
while (!pq.empty())
{
auto x = pq.top().second;
pq.pop();
// marking the current node as visited
vis[x] = true;
for (auto it : adj[x])
{
int y = it.first, weight = it.second;
// if the node is unvisited and its weight is greater than the current weight t
// then insert it in priority queue with new weight and mark it as visited
if (!vis[y] && weight < val[y])
{
val[y] = weight;
par[y] = x;
pq.push({val[y], y});
}
}
}
}
int main()
{
int n = 8, m = 8;
// forming an undirected weighted graph
push(1, 2, 4);
push(1, 3, 9);
push(2, 4, 8);
push(4, 7, 12);
push(4, 6, 3);
push(6, 5, 10);
push(7, 5, 6);
push(5, 3, 5);
// parent array and val array for storing weights
int par[n], val[n];
// visited array
bool vis[n];
for (int i = 0; i < n; i++)
{
val[i] = INT_MAX;
vis[i] = false;
}
solve(par, val, vis);
// printing the parent and the node
for (int i = 1; i < n; i++){
cout << par[i] << " --> " << i << endl;
}
}
You can also try this code with Online C++ Compiler
For BFS traversal, we already know it is executed in O(V+E) time. Meanwhile, the inner loop will cost us O(LogV) time.
So overall time complexity is O((E+V)*LogV) = O(ELogV)
Space complexity is O(V+E)
Frequently Asked Questions
What is Prim's MST?
It is a type of greedy algorithm. It begins with an empty spanning tree. The idea here is to maintain two sets of vertices:
One contains vertices that are already included in MST while the other contains vertices that are not yet included.
Which representation method is used in Prim's algorithm?
Prim's algorithm can be easily implemented by using the adjacency list graph representation or adjacency matrix, and adding the edge with the minimum weight requires the linearly searching of an array of weights.
Which is better Prims or Kruskal?
The main advantage of Prim's algorithm is its complexity, which is theoretically better than Kruskal's algorithm. Therefore, Prim's algorithm is helpful only when we are dealing with dense graphs having lots of edges.
How do you calculate MST?
First, we have to sort all the edges in the non-decreasing order of their weights. Then we are supposed to pick the smallest edge. We have to check whether or not it forms a cycle with our spanning tree, which has been formed so far. If the cycle is not formed, we will include this edge. Else, we will discard it.
Conclusion
In this tutorial, we have explained Prim’s MST implementation for Adjacency List Representation. We have covered the important aspects of the topics involved, clarified the approach, and discussed the time complexity in detail.
Want To Learn More About brand-new technologies? We Have A Whole Category, visit Coding Ninjas and find courses related to Graphs, Dynamic Programming, and much more!



































 9+ registered
9+ registered 

