


























Introduction
Probabilistic Context-Free Grammar (PCFG) is an extension of Context-Free Grammar (CFG) that incorporates probabilities into its production rules. While CFG defines the structural rules of a language, PCFG adds a probabilistic dimension, allowing it to manage ambiguity by selecting the most likely parse for a given input. This makes PCFG particularly useful in fields like natural language processing, where multiple interpretations of a sentence may exist, as it can prioritize the most probable one based on statistical patterns learned from data.

What is Probabilistic Context-Free Grammar?
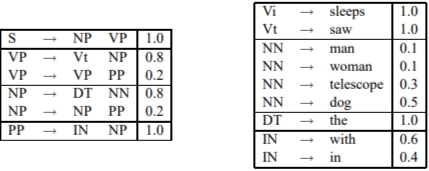
Probabilistic Context-Free Grammar
In the above we can see the Probabilistic Context-Free Grammar. It looks the same as context-free grammar, but now we have probabilities assigned to each rule in the grammar. Here, I have a set of context-free rules and will assume that 'S' is the start symbol under the context-free grammar, and we have probabilities for each rule. These probabilities have one critical property: if I take any nonterminal in the grammar, let's take VP, for example. There are many possible ways of expanding that nonterminal. So VP can be extended in three different ways. We can write it as VI or VT NP or V PPP. We can Notice that the three different probabilities associated with the three options sum to one (0.4+0.4+0.2=1.) This is the key constraint on the probabilities in a probabilistic context-free grammar. If we look at any nonterminal, we must have these probabilities summing to 1. Here is another example: NP; we can rewrite it in two different ways: a determiner followed by a noun or a noun followed by a prepositional phrase. These two probabilities sum to 1. So these probabilities have a clear interpretation which is the following
They are the conditional probabilities conditioned on a particular nonterminal. We have multiple different ways of writing nonterminals. We now distribute those other options over those different ways of redirecting that nonterminal.
Let's take a particular parse tree under this grammar.
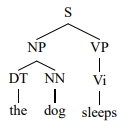
Notice that every one of the rules I am using here is in this grammar. Hence, this is a valid parse tree under the underlying context-free grammar. We will now assign probabilities to this parse tree, which is simply a product of possibilities for the different rules. If we look at the first rule, S goes to NPVP with a probability of 1.0. NP goes to DTNN with a chance of 0.3; DT goes to 'the' with a probability of 1.0. To calculate the possibility of the entire tree, we need to multiply together the chances of the different rules.
The final expression looks like- 1.0 x 0.3 x 1.0 x 0.7 x 0.4 x 1.0.
Given a parse-tree t ∈ TG containing rules α1 → β1, α2 → β2, . . . , αn → βn, the probability of t under the PCFG is
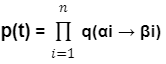
Where q(α → β) is the probability for the rule
Probabilistic context-free grammars (PCFGs) are defined as follows:
A PCFG consists of:
1. A context-free grammar G = (N, Σ, S, R).
2. A parameter q(α → β)
for each rule α → β, ∈ R. The parameter q(α → β) can be interpreted as the conditional probability of choosing rule α → β in a left-most derivation, given that the nonterminal being expanded is α.For any X ∈ N, we have the constraint
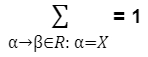
In addition we have q(α → β) ≥ 0 for any α → β ∈ R
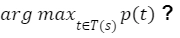

 9+ registered
9+ registered 

