



























Introduction
Python, a versatile and widely-used programming language, continues to dominate the tech industry with its simplicity, readability, and robust ecosystem. Python's clean syntax and powerful libraries make it a preferred choice for web development, data analysis, artificial intelligence, automation, and more. In this blog, "Top 100+ Python Interview Questions and Answers 2024," we provide a comprehensive resource designed to help candidates prepare for Python interviews across different levels. This extensive list of questions and answers covers fundamental concepts, advanced topics, and practical applications, ensuring that you are well-equipped to tackle any challenge that comes your way.

We have classified Python Interview Questions into the following sections:
- Python Interview Questions for Freshers
- Python Interview Questions for Experienced
- Python Pandas Interview Questions
- Python Libraries Interview Questions
- Python OOPS Interview Questions
- Numpy Interview Questions
- Python Programming Examples
Let’s discuss them in detail with answers.
Python Interview Questions Freshers
1. What is Python? What are some of its key features?
Python is a high-level, interpreted programming language known for its simplicity and readability. Its key features include dynamic typing, automatic memory management, and a rich standard library. It also has strong community support and is used for various applications such as web development, data analysis, and machine learning.
2. What is the difference between a list and a tuple in Python?
| LIST | TUPLE |
|---|---|
| Lists are mutable. | Tuples are immutable. |
| Denoted by square brackets. | Denoted by parenthesis. |
| Slower due to dynamic resizing and modifications. | Faster due to fixed size and immutability. |
3. What is the difference between a set and a dictionary in Python?
| SET | DICTIONARY |
|---|---|
| It is a collection of unique elements. | It is a collection of key-value pairs. |
| Created using the set() function. | Created using the dict() function. |
4. What is the use of the "self" keyword in Python?
In Python, "self" refers to the instance of a class that a method calls. It is typically used within a method to refer to instance variables or contact other instance methods. When a method calls on an instance of a class, the self keyword accesses the instance's attributes and methods.
5. What is a lambda function in Python?
In Python, a lambda function is a small, anonymous function that can have any number of arguments but can only have one expression. Lambda functions are a shorthand for creating simple functions that are only needed once. They are made using the lambda keyword, followed by the function's arguments and a colon, and then the expression for evaluation.
6. What is the difference between "range" and "xrange" in Python 2. x?
In Python 2. x, "range" and "xrange" generate integer sequences. However, "range" yields a list of integers simultaneously, while "xrange" generates them on-the-fly as needed. It can be more memory-efficient when working with large ranges, as it generates only one number simultaneously. In Python 3. x, "range" has been modified to behave like "xrange," and "xrange" no longer exists.
7. What is the purpose of the "init" method in Python?
In Python, the __init__ method is a unique method that looks like a constructor, though it is not. It is used for instantiating objects of a class. It initializes the object's attributes with default values or values passed during object creation. This method is commonly used to set up an object's initial state and can also be used to perform other initialization tasks.
8. How can you check the type of a variable in Python?
In Python, the type() function determines the type of a variable. For example, type(variable) will return the style of the variable.
Alternatively, the isinstance() function can be used to check if a variable is an instance of a particular class. For example, isinstance(variable, int) will return True if the variable is an instance of the int class.
9. What is the difference between "is" and "==" in Python?
The "is" operator checks if two objects are the same object in memory. It returns True if both objects are identical, meaning they have the same memory address.
On the other hand, the "==" operator checks if two objects have the same value. It returns True if the values of the two objects are equal, regardless of whether they are the same object in memory.
10. What are decorators in Python, and how are they used?
In Python, decorators are functions that help the compiler know about the unique property associated with a particular function. By wrapping a function with another function, decorators can modify the input or output values of the function or add functionality to it before or after it executes. Decorators are often used to add cross-cutting concerns like logging, caching, or authentication in a reusable manner.
11. What is Python, and how is Python useful?
Python is a high-level, interpreted programming language first released in 1991. It is open-source, meaning the source code is freely available for modification and distribution.
Python's popularity is due to its simple and readable syntax, versatility, and ease of use. It has a large standard library and a vast array of third-party libraries and frameworks that allow developers to build complex applications quickly and efficiently.
Python is useful in the following ways:
- Python is useful for various applications, including web development, scientific computing, data analysis, machine learning, artificial intelligence, and automation. It is used by organizations such as Google, NASA, and Netflix and is also widely used in academia.
- One of the main advantages of Python is its simplicity and readability. The syntax is easy to understand and write, making it accessible to every programmer.
- Python also strongly focuses on code readability, making it easier for people to collaborate on projects and maintain code over time.
- Another advantage of Python is its versatility. It can be used for various applications, from building simple scripts to creating complex applications with graphical user interfaces.
12. How do you create a function in Python?
def keyword is used to create a function in Python, followed by the name of the function and any parameters the function will accept in parentheses. The code inside the function should be indented to show that it is a part of it. Here is an example:
- Python
Python
def calculate_rectangle_area(length, width):
area = length * width
return area
# Call the function with arguments 5 and 10
result = calculate_rectangle_area(5, 10)
# Print the result
print(result)
Output:
50
This function takes two parameters, length and width, and calculates the area of a rectangle using the formula area = length * width. The return statement returns the value of the area.
13. What is the difference between a list and a tuple in Python?
A list is a mutable data type in Python that uses square brackets [] to store an ordered collection of items.
On the other hand, a tuple is an immutable data type in Python that uses parentheses () to store an ordered collection of items. Tuples are faster and more memory-efficient than lists, especially for larger data collections.
| Feature | List | Tuple |
|---|---|---|
| Mutable/Immutable | Mutable | Immutable |
| Syntax | Square brackets [] | Parentheses () |
| Length | Can change length | Fixed length |
| Performance | Slower for large lists | Faster for large tuples |
| Use cases | Used for dynamic data | Used for static data |
| Example declaration | fruits = ['apple', 'banana'] | fruits = ('apple', 'banana') |
14. What is a module in Python?
A module in Python is a file containing Python code that can be used in other Python programs.
A module is a self-contained unit of code that can include variables, functions, and classes that can be accessed and used in other Python programs. By organizing code into modules, you can avoid duplicating code across different programs and instead import and use the same code in multiple places, making it easier to maintain and reuse your code.
Python has many built-in modules that can be used for various purposes, such as working with files, network communication, data processing, and more. In addition, third-party modules can be installed and used in Python programs to extend their functionality.
To use a module in a Python program, you first need to import it using the import statement. Here is an example:
- Python
Python
import math
result = math.sqrt(12)
print(result)
Output:
3.464101615137754415. What is the difference between break and continue in Python?
Break and Continue are two keywords in Python that are used to change the flow of a loop. These keywords are used inside loops, such as for and while loops.
Both keywords are used to change the flow of a loop, but they have different effects on the loop:
- Break - It exits the loop entirely and continues with the next statement after the loop.
- Python
Python
for i in range(10):
if i ==5:
break
print(i)
Output:
0
1
2
3
4
- Continue- It skips the current iteration and moves on to the next iteration of the loop.
- Python
Python
for i in range(10):
if i == 5:
continue
print(i)
Output:
0
1
2
3
4
6
7
8
916. How do you iterate over a list in Python?
Let's consider the following code to explain iteration over a list in Python.
- Python
Python
numbers = [1, 2, 3, 4, 5]
for num in numbers:
if num % 2 == 0:
print(num, "is even")
else:
print(num, "is odd")
Output:
1 is odd
2 is even
3 is odd
4 is even
5 is odd
Explanation: We have a list called numbers containing five integers. We use a for loop to iterate over the list, and on each iteration, we assign the current item in the list to the variable num. Then, we check if the number is even or odd using the modulus operator (%) and print out the result.
The 'for' loop iterates over the list from the first to the last item and executes the indented code block once for each item.
17. What is a dictionary in Python?
A dictionary is a collection of key-value pairs that store and retrieve data. In other words, a dictionary is like a map that connects keys to values.
Example:
- Python
Python
student = {
"name": "Jaideep",
"age": 22,
"major": "Computer Science"
}
print(student["name"])
print(student["age"])
print(student["major"])
Output:
Jaideep
22
Computer Science
18. Write a Python factorial program without using if-else, for, and ternary operators.
We can use a recursive function that calculates the factorial of a given number without using if-else, for, and ternary operators:
The function recursively calls itself until it reaches the base case of n=1, at which point it returns 1. Each recursive call multiplies the current value of n by the result of the previous call, effectively calculating the factorial.
- Python
Python
def factorial(n):
return (n==1) or (n * factorial(n-1))
print(factorial(4))
Output:
2419. Write a Python code to check the Armstrong number.
- Python
Python
number = int(input("Enter a number: "))
order = len(str(number))
sum = 0
temp = number
while temp > 0:
digit = temp % 10
sum += digit ** order
temp //= 10
if number == sum:
print(number, "is an Armstrong number")
else:
print(number, "is not an Armstrong number")
Output:
Enter a number: 34
34 is not an Armstrong number20. What is the difference between deep and shallow copying of an object in Python?
Shallow copying creates and populates a new object referencing the original object's data. Suppose the original object contains mutable objects as elements. In that case, the new entity will reference the same mutable objects, and changes to the mutable objects are reflected in both the new and original objects.
Deep copying creates a new object and recursively copies the original object's data and the data of any things it references. It means that the new entity and its simulated data are entirely independent of the original object and its data.
21. How does garbage collection work in Python?
In Python, garbage collection is the process of freeing up memory unused by the program. Python automatically uses a built-in system that counts how often an object is used. If the count goes to zero, the object is considered garbage and removed from memory.
22. What is the difference between append() and extend() methods in Python lists?
In Python, both append() and extend() methods are used to add elements to a list, but they have some differences in functionality.
- append() method: This method adds a single element to the end of a list. The element can be of any type, including another list.
- extend() method: This method adds multiple elements to a list, such as elements from another list, tuple, or any iterable object. The elements are added one by one to the end of the list.
23. What is the purpose of the "yield" keyword in Python?
The "yield" keyword in Python creates generator functions that can produce a sequence of values. When we call a function with a "yield" statement, it returns a generator object. The generator object helps to iterate over the values produced by the function. The generator has values on-the-fly as it repeats over, which makes it a memory-efficient way to generate sequences.
24. What is the difference between "static method" and "class method" in Python?
A static method is a method bound to the class, not an instance of the class. It means it calls the class without creating an instance. Static methods define utility functions that don't depend on the state of the example or the class.
A class method is also bound to the class, but it takes a reference to the class itself as the first argument. Defined methods operate on the class itself rather than on the instances of the class. Class methods are alternative constructors for the class, which can create class instances with different initial parameters.
25. How can you create a generator in Python?
A generator is created using a function that contains the "yield" keyword. As the generator function is created, it returns a generator object to produce a sequence of values on-the-fly as the generator iterates. To create a generator function, define a function that contains one or more "yield" statements. Each "yield" statement should produce a value for the generator to return.
26. What is the difference between "map" and "filter" functions in Python?
"map" and "filter" are built-in functions operating on iterable objects. The main difference between the two functions is that "map" applies a given function to each item in an iterable and returns an iterator with the results. In contrast, "filter" applies a given function to each item in an iterable and returns an iterator with only the things that meet the given condition.
27. How can you handle exceptions in Python?
Exceptions are handled using a try-except block. The code that may raise an exception is put inside the "try" block, and the exception handler is inside the "except" block. If the try block raises an exception, the program flow is immediately transferred to the except block.
The except block can be used to catch a specific or general exception and handle the exception by providing an appropriate message to the user or performing other actions. We can also use it to raise a new exception or re-raise the original exception.
28. What is the difference between a "module" and a "package" in Python?
A module is a single file containing Python code that can be imported and used in other Python codes. A module typically includes functions, classes, and variables used in other programs. Modules are a way to organize code and promote code reuse.
On the other hand, a package is a collection of related modules organized into a directory structure. A package contains an init.py file executed while package importing. The init.py file can contain initialization code and define the package's interface by specifying which modules are part of the package.
29. What are some of the built-in data structures in Python, and how are they used?
Python has multiple built-in data structures, including lists, tuples, sets, and dictionaries, which store and organize data differently.
- Lists: Lists are ordered collections of items of different types. They are defined by enclosing a comma-separated list of values in square brackets. Lists are mutable, meaning you can remove, add or modify their items.
- Tuples: Tuples are similar to lists but immutable, meaning you cannot change their values once they are defined. Tuples are defined by enclosing a comma-separated list of values in parentheses.
- Sets: Sets are unordered collections of different items. They are defined by enclosing a comma-separated list of values in curly braces. Sets are helpful when you want to eliminate duplicates from a collection of objects.
- Dictionaries: Dictionaries are collections of key-value pairs. They are defined by enclosing a comma-separated list of key-value teams in curly braces, with a colon separating each key and its corresponding value. Dictionaries are helpful when looking up a particular key's value.
30. What is the difference between a Mutable datatype and an Immutable data type?
Mutable data types are those whose values can be changed after creation. When you modify a mutable object, it changes its value in place without creating a new object. Any other references to the object will also see the change.
On the other hand, immutable data types are those whose values cannot be changed after creation. When you modify an immutable object, you create a new object with the modified value. Any other references to the original object will not see the change.
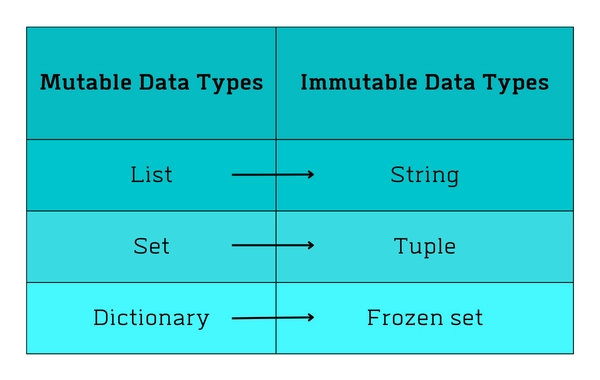
31. What is the difference between '==' and 'is' in Python?
In Python, the == operator and the is operator are used to compare two objects. However, they have different meanings and are used in different contexts.
The == operator compares the values of the objects, while the is operator checks whether the two objects are the same, i.e., whether they have the same identity.
| == operator | is operator |
|---|---|
| It compares the values of two objects. | It checks whether two objects are the same object. |
| It returns True if the values of two objects are equal. | It returns True if two variables reference the same object in memory. |
| It returns False if the values of two objects are not equal. | It returns False if two variables do not reference the same object in memory. |
| It is used for value comparison. | It returns False if two variables do not reference the same object in memory. |
| Examples: a == b, x == 42. | Examples: a is b, x is None. |
Example:
- Python
Python
a = [4, 2, 1]
b = [4, 2, 1]
c = a
print(a == b)
print(a is b)
print(a is c)
Output:
True
False
True
Explanation:
- True - the values of the objects are the same.
- False - the objects have different identities.
- True - both variables reference the same object in memory.
32. What is the difference between a shallow copy and a deep copy in Python?
The difference between a shallow copy and a deep copy in python are as follows:
| Features | Shallow Copy | Deep Copy |
|---|---|---|
| Definition | A shallow copy creates a new object but references the same memory addresses as the original object for the nested objects. | A deep copy creates a new object with new memory addresses for the main object and any nested objects. |
| Syntax | new_object = old_object.copy() or new_object = list(old_object) | new_object = copy.deepcopy(old_object) or new_object = list(old_object). |
| Changes to nested objects | Any changes to the nested objects will reflect in both the original and copied objects. | Changes made to the nested objects in the copied object will not reflect in the original object. |
| Speed | It is faster than a deep copy because it does not create a new object for nested objects. | Slower than a shallow copy because it creates a new object for each nested object. |
| Memory Usage | Less memory usage because it shares memory addresses for nested objects. | More memory usage because it creates new memory addresses for each nested object. |
33. How are arguments passed by value or by reference in Python?
In Python, arguments are generally passed by reference, but how it works can be confusing.
When you pass an object to a function in Python, a reference to that object is passed to the function. This means that the function can modify the object, and those modifications will be reflected in the calling code.
Example:
- Python
Python
def modify_list(my_list):
my_list.append(4)
# create a list
my_list = [1, 2, 3]
# call the modify_list function
modify_list(my_list)
# print the list
print(my_list)
Output:
[1, 2, 3, 4]Explanation: In this example, the ‘modify_list’ function modifies the original list by appending the value 4. When the function returns, the modified list is still accessible in the calling code.
However, there are some cases where it appears that Python is passing arguments by value. For example, when you pass an integer or a string to a function and modify it within it.
In conclusion, arguments in Python are generally passed by reference, which means that modifications made to objects within a function can affect the original object in the calling code. However, the behavior can vary depending on the type of object being passed since immutable objects like strings, and integers cannot be modified in place.
34. How to convert a list into a set?
To convert a list into a set in Python, you can use the built-in set() function. This function takes an iterable object (such as a list) as input and returns a new set object that contains all the unique elements in the iterable.
- Python
Python
my_list = [1, 2, 3, 3, 4, 4, 5]
my_set = set(my_list)
print(my_set)
Output:
{1, 2, 3, 4, 5}
Explanation:
In the above code, we first define a list my_list containing duplicate elements. We then pass this list to the set() function to create a new set object, my_set, that contains only the unique elements of the original list.
Note that sets are unordered collections of unique elements, so the order of the elements in the original list may not be preserved in the resulting set.
35. How can you create Empty NumPy Array In Python?
You can create an empty NumPy array in Python using the numpy.empty() function. This function creates an array of a specified size and shape but with uninitialized entries.
Here's an example:
- Python
Python
import numpy as np
# Create an empty array with shape (3, 4)
empty_arr = np.empty((3, 4))
print(empty_arr)
This code will output an empty array of shape (3, 4), which means it has 3 rows and 4 columns, but with no values assigned to any of its entries:
Output:
[[1.86780114e-316 0.00000000e+000 5.31998820e-317 6.90266114e-310]
[6.90266150e-310 5.31998820e-317 6.90266114e-310 6.90266114e-310]
[6.90266114e-310 6.90266115e-310 5.31998820e-317 6.90266083e-310]]
As you can see, the array entries are uninitialized, containing whatever values were already in the memory space where the array was created. If you want to create an empty array with initialized entries, you can use the numpy.zeros() function instead.
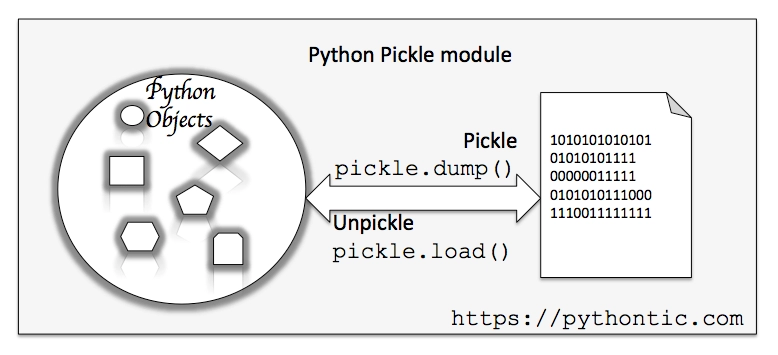
36. What are Pickling and Unpickling?
Pickling and unpickling are processes used in Python to serialize and deserialize objects. Serialization converts an object into a byte stream, which can be stored or transmitted over a network. Deserialization transforms a sequence of bytes, typically stored in a file or transmitted over a network, back into an object in memory that can be manipulated and used by a program.
- Pickling converts a Python object hierarchy into a byte stream using the pickle module. This byte stream can be saved to a file or sent over a network. The pickle module can handle most Python objects, including complex data types such as lists, sets, and dictionaries.
- Unpickling is the reverse process of pickling. It involves reading a byte stream and reconstructing the original Python object hierarchy. This is done using the pickle.load() function.
37. Write a code snippet to get an element, delete an element, and update an element in an array.
- Python
Python
import numpy as np
# Create an array
arr = np.array([1, 2, 3, 4, 5])
# Get an element
element = arr[2]
print("Element at index 2:", element)
# Delete an element
arr = np.delete(arr, 3) # Delete element at index 3
print("Array after deleting element at index 3:", arr)
# Update an element
arr[1] = 6 # Update element at index 1 to 6
print("Array after updating element at index 1:", arr)
Output:
Element at index 2: 3
Array after deleting element at index 3: [1 2 3 5]
Array after updating element at index 1: [1 6 3 5]38. What is a lambda function? How are these written in Python?
An anonymous function is also known as a lambda function. It can have any number of parameters but can have just one statement.
Example
- Python
Python
v = lambda p,q : p+q
print(v(7, 5))
Output:
1239. How to reverse lists in Python using slicing?
[::-1] is used to reverse the order of an array or a sequence.
For example
- Python
Python
import array as arr
a=arr.array('i',[1,2,3,4,5])
a[::-1]Output:
array(‘i’, [5, 4, 3, 2, 1])
[::-1] reprints the array as a reversed copy of ordered data structures such as an array or a list. The original array or list remains unchanged.
l = [ 'a','b','c','d','e' ]
l[::-1]
Output:
[ ‘e’, ‘d’, ‘c’, ‘b’, ‘a’ ] 40. How can random numbers be generated in Python?
The Random module is a standard module that is used to generate a random number. The method is defined as:
import random
random.random()
The statement random.random() method returns a floating-point number in the range of [0, 1). This function generates random float numbers. Here, The methods used with the random class are the bound methods of the hidden instances. The 'random' module instances can show the multithreading programs that create different examples of individual threads.
41. What is the difference between range & ‘xrange’?
For the most Part, 'xrange' and 'range' have the same functionality. They both provide a way to generate a list of integers to use; however, you please. The only difference is that 'range' returns a Python list object while 'xrange' returns an 'xrange' object.
This means that 'xrange' doesn't generate a static list at run-time as 'range' does. It creates the values as you need them with a unique technique called yielding. This technique is used with a type of object known as generators. That means that if you have a vast range, you'd like to generate a list for, say, one billion, 'xrange' is the function to use.
This is especially true if you have an accurate memory sensitive system such as a cell phone that you are working with, as the 'range' function will use as much memory as it can to create your array of integers, which can result in a Memory Error and crash your program. The 'range' function is a memory hungry beast.
42. How can you randomise the items of a list in place in Python?
- Python
Python
from random import shuffle
x = ['This', 'sentence', 'will', 'be', 'shuffled', 'now']
shuffle(x)
print(x)
Output:
['sentence', 'This', 'will', 'shuffled', 'be', 'now']
Every time output can be random.
43. What is the concept of pickling and unpickling in Python?
Python library offers a feature - serialisation out of the box. Serialising an object refers to transforming it into a format that it can store to deserialise it, later on, to obtain the original thing. Here, the pickle module comes into play. It accepts any Python object, converts it into a string representation, and dumps it into a file using the dump function; this process is called pickling. In contrast, the process of retrieving original Python objects from the stored string representation is called unpickling.
Pickling:
The process of serialisation in Python is known as pickling. Using the concept of 'pickling', any object in Python can be serialised into a byte stream and dump it as a file in the memory. The process of pickling is compact, but it can compress pickle objects further. Moreover, pickle keeps track of the serialised objects, and the serialisation is portable across versions.
The function is used for the above process 'pickle.dump()' from the pickle module in Python.
Unpickling:
Unpickling is the opposite of pickling. It deserialises the byte stream to recreate the objects stored in the file and loads them in the memory.
The function is used for the above process 'pickle.load()'.
44. What are the generators in Python?
Functions that return an iterable set of items are called generators.
Generators are functions that return iterable collection of items, one at a time, in a fixed manner. Generators, generally, are used to create iterators with a different approach. They employ the use of yield keywords rather than return to return a generator object.
Let's try and build a generator for Factorials of numbers -
## generate factorials of numbers upto n
def factorial(n):
i = 1
fact = i
while(i < n):
fact *= i
yield fact
i += 1
a = factorial(8) # create generator object
## iterating using __next__(), for Python2, use next()
a.__next__() # output => 1
a.__next__() # output => 2
a.__next__() # output => 6
a.__next__() # output => 24
a.__next__() # output => 120
a.__next__() # output => 720
a.__next__() # output => 5040
a.__next__() # error
## iterating using loop
for i in factorial(10):
print(i) # output => 1 2 6 24 120 720 5040 40320 362880 362880045. What are iterators in Python?
An iterator is an object.
It remembers the state, i.e., where it is used during iteration.
__iter__() method initializes an iterator.
It has a '__next__() ' method which returns the next item in iteration and points to the next element. Upon reaching the end of the iterable object, '__next__()' must return a StopIteration exception.
It is also self-iterable.
Iterators are objects using which we can iterate over iterable things like lists, strings, etc.
class LinkedList:
def __init__(self, lst):
self.numbers = lst
def __iter__(self):
self.pos = 0
return self
def __next__(self):
if(self.pos < len(self.numbers)):
self.pos += 1
return self.numbers[self.pos - 1]
else:
raise StopIteration
arr_obj = LinkedList([‘A’, ‘B’, ‘C’])
it = iter(arr_obj) # initialising an iterator object
print(next(it)) # output: ‘B’
print(next(it)) # output: ‘C’
print(next(it))
# Throws Exception
# Traceback (most recent call last):
# ...
# StopIteration46. What does '*args' and '**kwargs' stand for in Python?
- *args
*args is a particular parameter used in the function definition to pass arguments with a variable number of items.
"*" means variable length, and "args" is a name used as a convention.
def add(x, y, *args):
add = a + b
for num in args:
add += num
return add
print(add(1, 2, 3, 4, 5)) # output: 15
- **kwargs
**kwargs is a special syntax used as the function definition to pass a variable-length keyword argument. Here, also, "kwargs" is used just as a convention. It can also use any other name to represent "kwargs" here.
Keyworded argument means a variable that has a name when passed to the function. It is a dictionary of the variable terms and their value.
def KeyArguments(**kwargs):
for key, value in kwargs.items():
print(key + ": " + value)
KeyArguments(arg1 = "item 1", arg2 = "item 2", arg3 = "item 3")
# output:
# arg1: item 1
# arg2: item 2
# arg3: item 347. What are modules and packages in Python?
Python packages and Python modules are two mechanisms that allow for modular programming in Python. Modularizing has several advantages -
- Simplicity: Working on single modules helps you focus on a relatively small portion of the existing problem. This makes development more manageable and less prone to errors.
- Maintainability: Modules are designed to enforce the logical boundaries between different problem domains. If they are written to reduce interdependency, it is less likely that the modifications in a module might also impact other parts of the program.
- Reusability: Functions defined in a module can easily be reused by the other parts of the application.
- Scoping: Modules are typically defined as separate namespaces, which help avoid confusion between identifiers from other aspects of the program.
Modules are simply Python files with a '.py' extension and can have a set of functions, classes and variables defined. They can be imported and initialised using import statements if partial functionality is required to import the requisite classes or processes, such as the foo import bar.
Packages provide for hierarchical structuring of the module namespace using a '.' dot notation. As modules help avoid clashes between global and local variable names, similarly, packages can help prevent conflicts between module names.
Creating a package is easy since it also uses the system's inherent file structure that exists. Modules combined into a folder are known as packages. Importing a module or its contents from a package requires the package name as a prefix to the module's name joined by a dot.
48. How can one create classes in Python?
To create a class in Python, we use the keyword "class", as shown in the example below:
class Employee:
def __init__(self, employee_name):
self.name = employee_name
To instantiate or create the object from the class created above, we do the following:
employee = Employee("Jeff")
To access the name attribute, we call the attribute using the dot operator as shown below:
print(employee.name)
# Prints -> Jeff49. How do you initialise an empty class in Python?
An empty class does not have any members defined inside it. It is created using the 'pass' keyword (the pass command does nothing in Python). We can make all the objects for this class outside the class.
For example-
- Python
Python
class EmptyClass:
pass
obj = EmptyClass()
obj.name = "Arun"
print("Name created = ", obj.name)Output:
Name created = Arun50. How are access specifiers used in Python?
Python does not use access specifiers precisely like private, public, protected, etc. However, it does not deprive it to any variable. It has the concept of imitating variables' behaviour using a single (protected) or double underscore (private) as prefixed to variable names. By default, variables without prefixed underscores are public.
Example:
# to demonstrate access specifiers
class Employee:
# protected members
_name = None
_age = None
# private members
__department = None
# constructor
def __init__(self, emp_name, age, department):
self._name = emp_name
self._age = age
self.__department = department
# public member
def display():
print(self._name + " "+ self._age + " " + self.__department)




 6+ registered
6+ registered 

