Do you think IIT Guwahati certified course can help you in your career?
Introduction
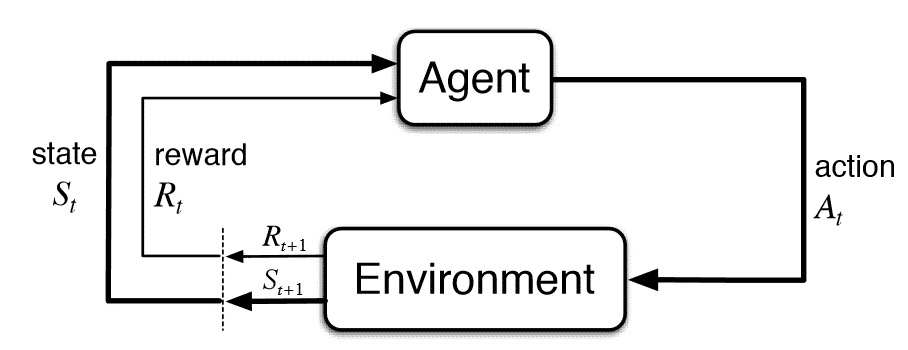
The region of machine learning involving how intelligent agents ought to take actions is known as reinforcement learning. It is among the three primary learning paradigms and supervised and unsupervised learning. It belongs to the deep learning subset, which maximizes a portion of cumulative reward. One algorithm which belongs to reinforcement learning is Q-learning. It is a model-free reinforcement learning algorithm based on the Bellman equation.
What is Q-Learning?
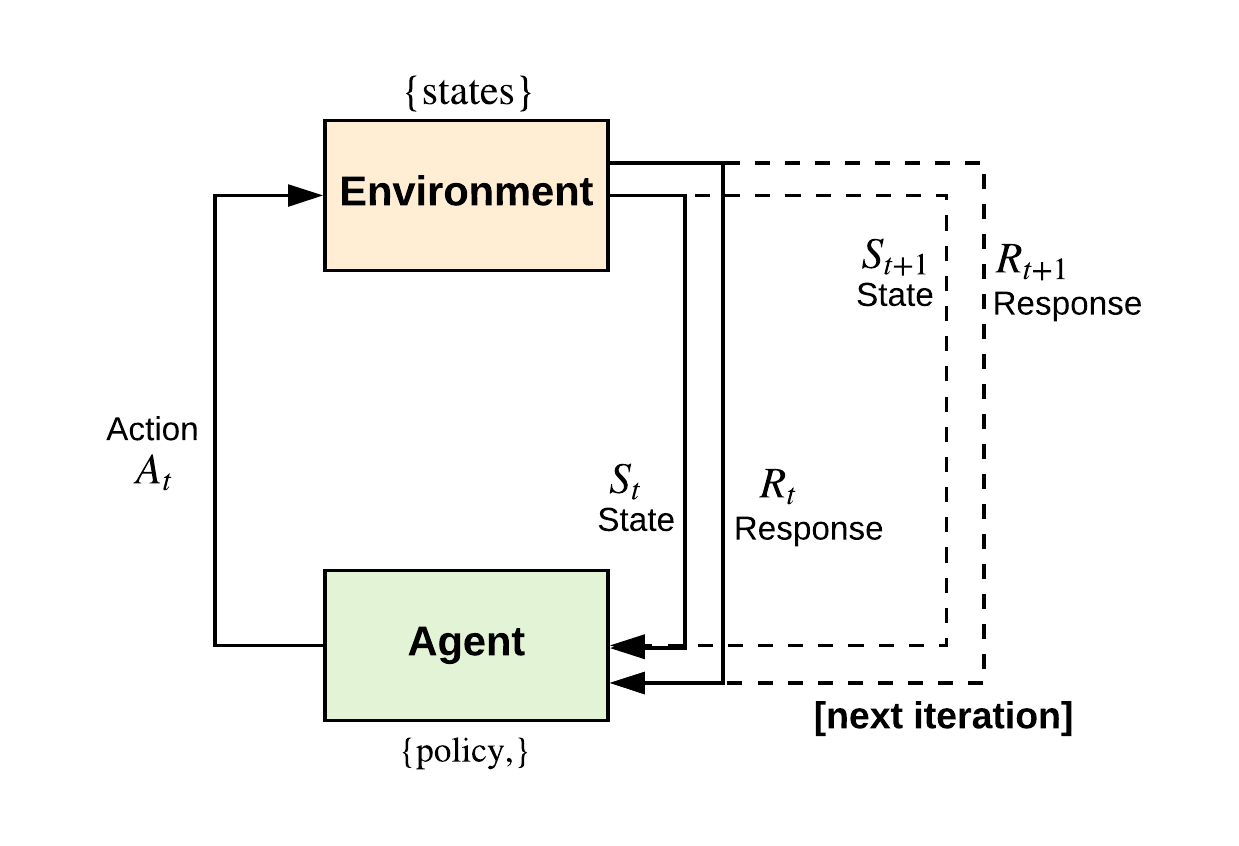
Q-learning belongs to the family of reinforcement learning that aims to come across the best action, given the current state. It is considered off-policy, i.e., it is independent of the agent's actions because the Q-learning function learns from actions outside the current policy. In particular, Q-learning aims to learn a policy that maximizes the total reward. A pictorial representation of the Q-learning algorithm is as follows:
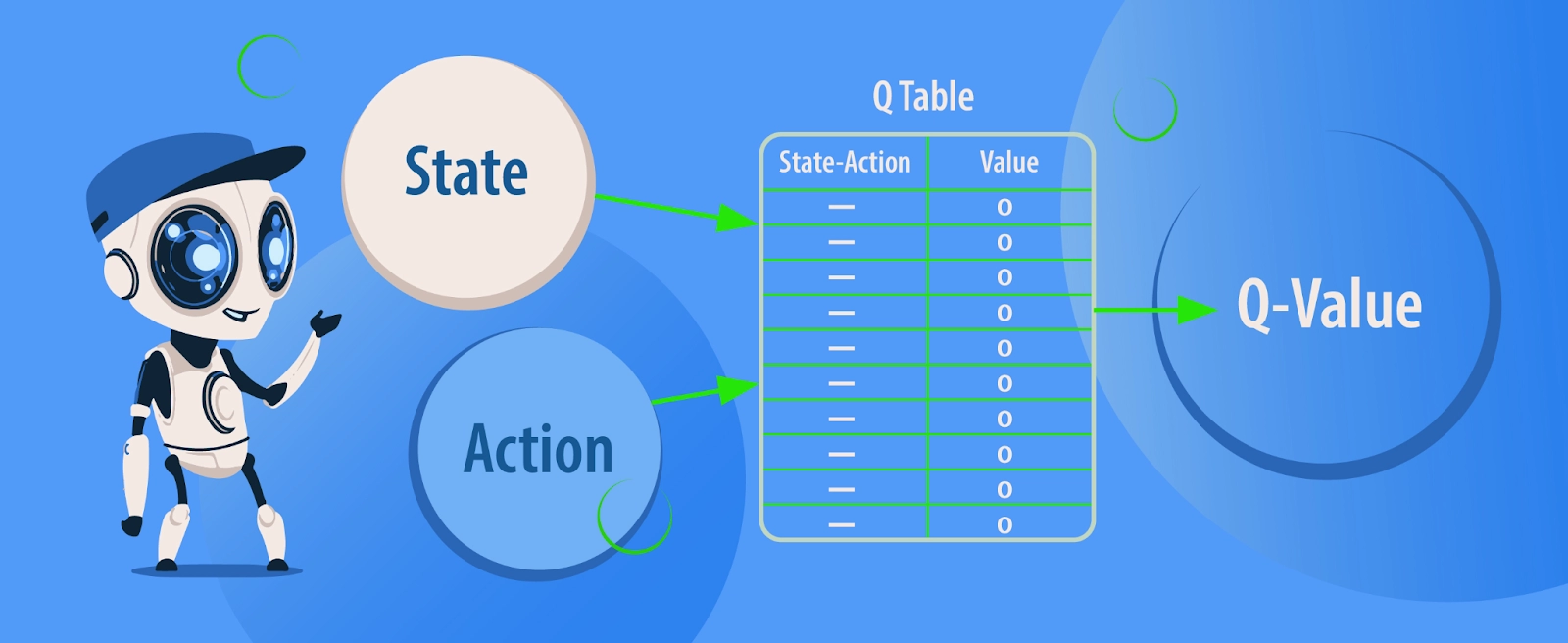
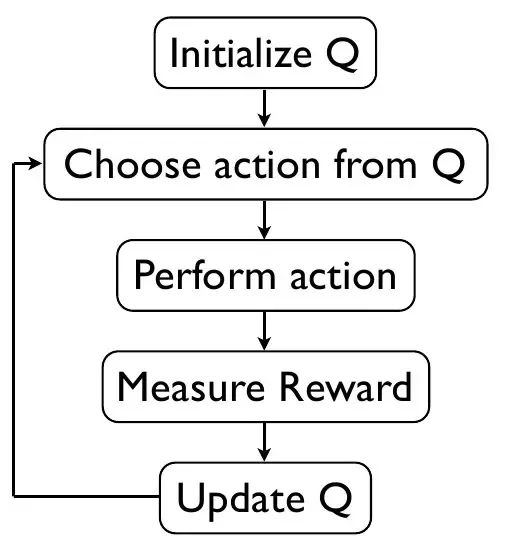
When Q-learning comes into play, a q-table is created, representing the shape of [state, action] matrix, and the values are initiated to zero. As the process follows, the values are updated. The Q-table works as a reference for the agent and selects the best action based on the q values.
In order to update the values in the Q-table, we will perform the Epsilon greedy algorithm to trade-off exploration and exploitation.
In exploitation, using the q-table as a reference to look at the possible actions, the agent interacts with the environment for a given state. The action is selected based on the agent's maximum action value.
Another way to take action is known as exploration. Instead of selecting actions based on the max future Reward in exploration, we randomly select an action. Exploration is essential as it lets the agent discover and explore new states that otherwise cannot be processed during the exploitation process.
The final updates are made after each complete cycle.
First, let us understand what Q values are. Q values represent an action at a particular state and are denoted by Q(s, a). The q value is stored in a table known as the Q table, which consists of one row for each possible state and one column for each possible action. The Q table contains the values that provide the agent with the best possible action in any particular state, helping to gain the greatest Reward.
Action
State
Up
Down
Left
Right
Start
0
0
1
0
Correct Path
0
0
0
0
Wrong Path
0
0
0
0
End
0
0
0
0
This sample Q table has the Q values for all actions at the respective states for a maze problem. You can see that the best reward position has the value one while others are 0. This helps the agent know better which action to take at the desired state. Now, the question is, how does the agent know what value to put in the Q table, and on what basis does it update the values?
Well, this is where the Bellman Equation comes to play. The bellman equation is responsible for deciding what new values are supposed to be taken based on the actions taken in the previous state. It is represented as
It is often referred to as alpha, which can be defined as whether the user accepts new values compared to the previous values. It is calculated by taking the difference between new and old values and multiplying them by the learning rate. The final value is then added to the previous q-values, and the value in the q-table is updated.
Gamma
It is a discount factor used to stabilize currents and future rewards. Generally, gamma's value ranges between 0.8 to 0.99.
Reward
The Reward is the output or value received after completing an action at a given state. It can take place at any given action or the terminals only.
Max
The np.max (), the inbuilt function of the numpy library, takes the greatest of the future Reward and applies it to the current state's Reward. The max function impacts the ongoing action by the possibility of future rewards, which helps the agent select the highest return action at any state.
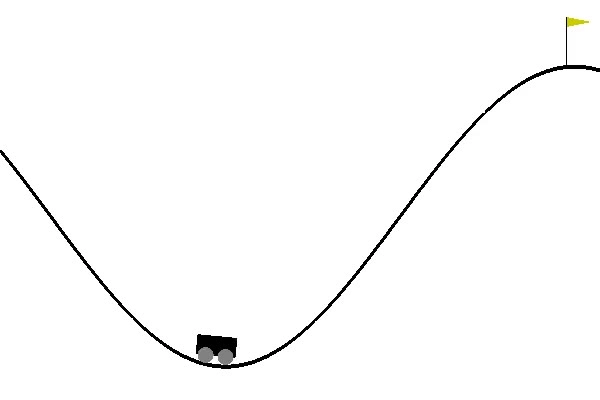
The following is the code to solve a mountain car problem. In this case, the car’s engine is not strong enough to climb a mountain in one go. Therefore, it uses momentum to climb the mountain.
#importing the necesary libraries
import gym
import matplotlib.pyplot as plt
import numpy as np
from gym import wrappers
#Setting the position space and velocity space values
pos_space = np.linspace(-1.2, 0.6, 12)
vel_space = np.linspace(-0.07, 0.07, 20)
#A funtion which takes the observation and returns the state
def get_state(observation):
pos, vel = observation
pos_bin = int(np.digitize(pos, pos_space))
vel_bin = int(np.digitize(vel, vel_space))
return (pos_bin, vel_bin)
#A funtion that returns the maximum action value
def max_action(Q, state, actions=[0, 1, 2]):
values = np.array([Q[state,a] for a in actions])
action = np.argmax(values)
return action
#Creating the environment
if __name__ == '__main__':
env = gym.make('MountainCar-v0')
env._max_episode_steps = 1000
n_games = 50000
alpha = 0.1
gamma = 0.99
eps = 1.0
action_space = [0, 1, 2]
states = []
for pos in range(21):
for vel in range(21):
states.append((pos, vel))
Q = {}
for state in states:
for action in action_space:
Q[state, action] = 0
score = 0
total_rewards = np.zeros(n_games)
for i in range(n_games):
done = False
obs = env.reset()
state = get_state(obs)
if i % 100 == 0 and i > 0:
print('episode ', i, 'score ', score, 'epsilon %.3f' % eps)
score = 0
while not done:
action = np.random.choice([0,1,2]) if np.random.random() < eps \
else max_action(Q, state)
obs_, reward, done, info = env.step(action)
state_ = get_state(obs_)
score += reward
action_ = max_action(Q, state_)
Q[state, action] = Q[state, action] + \
alpha*(reward + gamma*Q[state_, action_] - Q[state, action])
state = state_
total_rewards[i] = score
eps = eps - 2/n_games if eps > 0.01 else 0.01
mean_rewards = np.zeros(n_games)
for t in range(n_games):
mean_rewards[t] = np.mean(total_rewards[max(0, t-50):(t+1)])
plt.plot(mean_rewards)
plt.savefig('mountaincar.png')
You can also try this code with Online Python Compiler
Q-learning algorithms' primary disadvantage is that they learn deterministic policies, although mixed strategies are mainly required. Also, in the cycle, the environment is generally non-stationary because of the adaptation of other agents.
Another common disadvantage is that it takes more time to reach the optimal Q-value and more iterations to calculate the rewards.
FAQs
What is Q in Q-learning? The Q stands for quality. It symbolizes how effective a given action is in order to gain rewards.
Why do we use Q-learning? In order to find an optimal action-selection policy, we use Q-learning.
What is the major drawback of Q-learning? It only works with discrete and finite state and action spaces, which is the major drawback of Q-learning.
Key Takeaways
Q-learning is an off-policy reinforcement learning algorithm that uses Epsilon greedy method to get rewards. This article gave an in-depth explanation of the Q-learning method. To get an in-depth understanding of Reinforcement Learning, check out this article.

































 6+ registered
6+ registered 

