


























Introduction
Fischler and Bolles created the RANdom SAmple Consensus (RANSAC) algorithm, a general parameter estimation approach designed to deal with a high proportion of outliers in the input data. By removing outliers in the training dataset, the RANSAC (RANdom SAmple Consensus) technique takes the linear regression process to the next level. Outliers in the training dataset impact the coefficients/parameters learned during training.

As a result, outliers should be discovered and deleted during the exploratory data analysis phase. Outliers from the training data set should be removed, use Statistical approaches such as Z-scores, Box plots, other types of plots, hypothesis tests, and many others.
The Need for RANSAC Algorithm?
The concept underlying traditional linear regression is straightforward: create a "best-fit" line across the data points that minimizes mean squared errors. It appears to be in good condition. However, we do not often obtain such clean, well-behaved data.
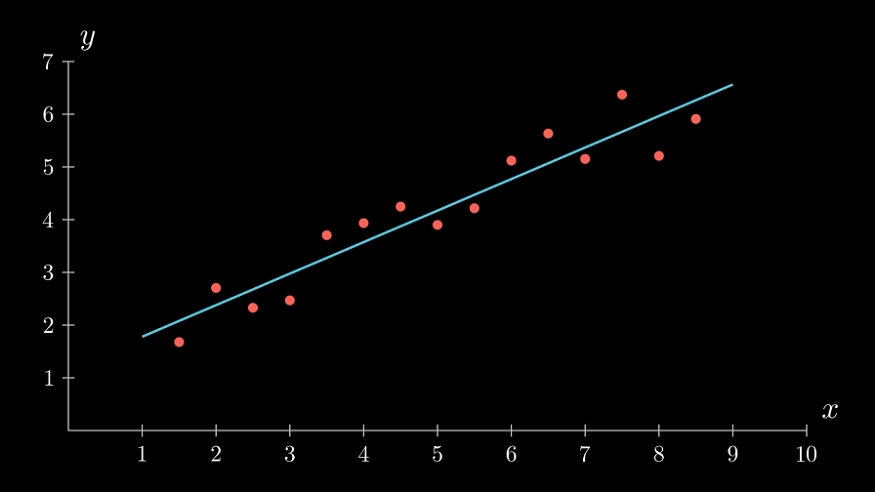
The Classic example of linear regression
You have been given a dataset and want to use it to fit a mathematical model. We can now presume that there are some inliers and outliers in this data. Outliers are data points that any plausible mathematical model cannot describe. Inliers are data points that a mathematical model can explain.
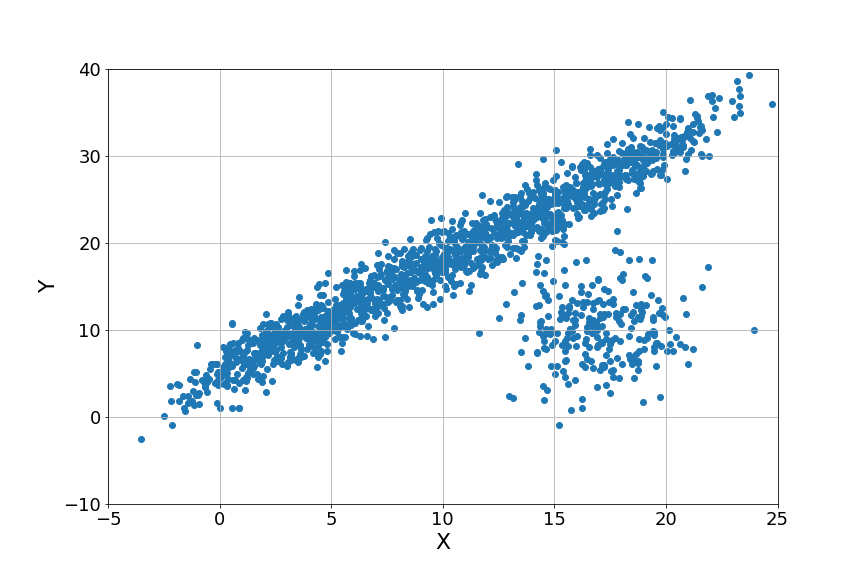
The quality of the mathematical model we can fit the data is usually harmed by their presence in the dataset. While estimating the parameters of our mathematical model, we should disregard these outliers for optimum outcomes. RANSAC assists us in finding these locations in order to provide a better fit for the inliers.
Even the inliers may not completely match the mathematical model owing to noise. However, the outliers either have an unusually significant quantity of noise or are produced due to measurement errors or sensor difficulties.
Let us discuss the algorithm now.


 8+ registered
8+ registered 

