Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
Hey Ninja!! Have you streamed your favourite show from Netflix or Prime video recently? Ever wondered how these companies handle such a vast amount of data in real-time? Big data deals with data on a massive scale, reaching millions of GBs. The data is global and distributed.
The data based on requirements and analytics are split into real-time and non-real-time. Let's look into these data requirements in depth. This blog will teach you about big data's real-time and non-real time requirements.
Real-time requirements
We are living in a real-time world and socialising everything with a need for up-to-the-minute user tracking in analytics across industries from e-commerce security to financial services and even web and IT analytics and monitoring. Facebook processes 2 lakh user updates per second, Bloomberg reports 6 lakh ticks per second, and Amazon reports 50 million active users on cyber Monday alone. Imagine the number of searches and clicks.
Let's zoom in on what this looks like when you imagine all of this. Imagine you would need to calculate all of this manually; this is where your batch system breaks down slow processing, right time and input-output, a heavy process of crunching the entire data set. Then again, how about storing the events in a partition of in-memory data?
Great if you put your big data on steroids, process and analyse massive event streams in real-time, meet gig spaces, and real-time analytics for big data. Let's slow it down a little and see how it works: it's fast, it's scalable, it's transactional, it's highly reliable, and it maintains data consistency.
But even better, it equips you with all the event processing and query features you need and back to your real-time. It can even mirror your data to every big data store at your own pace, which is excellent news for you.
Advantages of Real-Time Data
Listed below are some of the significant advantages of real-time data:
Live decision making: Real-time data processing allows you to take decisions on the fly. For example, real-time analysed data can be beneficial if you are an intraday stock trader.
Rapid issue resolution: When data is processed in real-time, actions can be taken swiftly if an error occurs. It helps in risk mitigation. For example, if a server goes down, measures can be taken immediately to resolve the issue.
Improves service: Real-time monitoring of data can help enhance customer experience by providing interactive and situational features. For example, live GPS tracking gives food delivery services extra information to the customer.
Detecting fraud: Banking applications benefit from this significant way. Actual financial scams are avoided using real-time data analysis.
Infrastructure requirements for Real-time data
Broadly these requirements can be classified into software and hardware requirements:
Software Requirements:
Aggregator: It is responsible for collecting data from various sources and passing it on for further processing. It catches data from streams and batches in real-time.
Broker: Large chunks of data must be broken into smaller objects and packets. It makes data ready to process.
Analytics engine: It is responsible for the actual processing of raw data. After processing data, it gives analysis results in the form of actionable events.
Hardware Requirements:
High-speed network: Blazing fast internet connection is required at the server site. It is commonly achieved by getting a leased line simultaneously from different core network providers.
Servers: High-capacity systems are deployed in a cluster to handle significant incoming traffic and real-time data processing. Usually, these are located at data centers.
In memory analytics:Some servers only use RAM as a storage device to fasten the processing speed.
Power supply:A robust power delivery system is required for maximum uptime.
Non-real time requirements
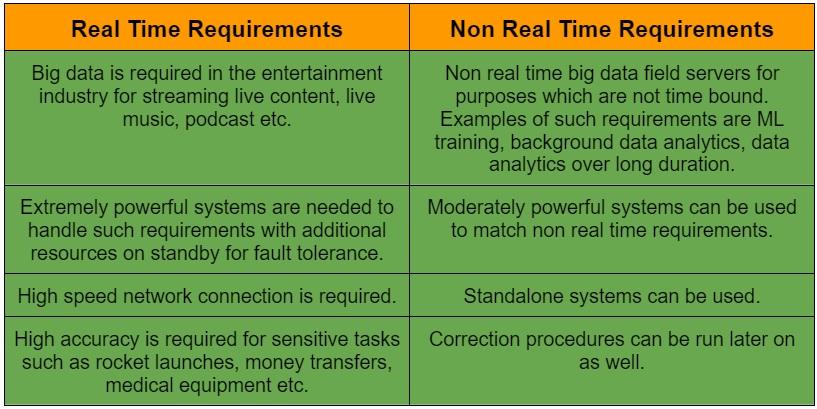
Real-time and non-real time requirements are fundamentally different. Non-real-time requirements are more traditional in their application. It doesn't deal with constantly streaming input data that has to be processed in real-time but rather with data in large batches without any time constraints.
The time taken to process this data can be in hours or even days and is not a very popular requirement nowadays. Most companies prefer dealing with data in real-time. But they still have many advantages over real-time requirements.
Non-real-time tasks are more accurate in their results, the infrastructure needed to run them is cheaper as it doesn't need to be as scalable or versatile as a real-time task and the tasks themselves are more straightforward and more traditional to run. Examples of non-real-time requirements are tasks that maintain payrolls, event loggers, billing, and old email services.
Difference between real-time and non-real time requirements
Frequently Asked Questions
What is Hadoop? Why is it used?
Hadoop is a software framework that stores data and runs applications on clusters. It helps in providing massive storage for any data or information. It provides enormous processing power and the ability to handle virtually limitless concurrent tasks or jobs running simultaneously.
What is scalability?
Scalability is the measure or unit of a system's ability that can either increase or decrease the performance and cost concerning application changes and, sometimes, system processing demands. Scalability is also known as differentiability or expandability.
What is ambiguous data? Explain with an example.
Ambiguous data is the information that exists as the same thing in two different attributes. We can also say that these are those types of data which are not specific or are uncertain. For example, a person with the same first and last name may create ambiguity.
Conclusion
Cheers on completing the blog on Real-time and Non-real time requirements! This blog discussed the types of big data in detail, each kind of data individually, and the difference between real-time and non-real time requirements.

































 8+ registered
8+ registered 

