Do you think IIT Guwahati certified course can help you in your career?
Introduction
There are millions of products available online, and choosing one out of them is difficult. Earlier, we ask recommendations from our acquaintances, now from the online store. So how do these online stores recommend us users?
These e-commerce companies have developed a recommendation system,i.e., a system to recommend products to users based on different factors. These recommender systems predict the most likely product that the consumer is most likely to purchase. Companies like Amazon, Flipkart, Netflix uses these systems to provide suggestions to its consumer.
There are tons of information available, but these systems filter out the essential information based on consumers' interests and other factors. Recommendation systems create similarity between the user and the product and attribute this similarity between the user and product for the recommendation.
Both the users and the services providers have benefited from these systems. The quality and decision-making process has also improved through these kinds of systems.
What Recommendation Systems Can Solve?
It helps the consumer to find the best product.
It helps websites to increase user engagement.
It makes the contents more personalized.
It helps websites to find the most relevant product for the consumer.
Help item providers in delivering their items to the right user.
These systems work on the principle that they recommend the most viewed or purchased products by most people or recommend currently trending or most popular products.
The advantage of systems is that they do not include users' data or recommend products on day 1 of business. Still, the major disadvantage is that it suggests the same sort of products to every other user, and secondly, it is not personalized.
Particular examples are google news or youtube trending videos.
Classification Model Based
These systems work on the principle that it uses features both of the user and the product and then apply the classification model to decide whether the user will buy the product or not. Certain limitations require a tremendous amount of information about different users and products, which is a rigorous task. Secondly, it has flexibility issues.
Content-Based Recommendations
These systems work on the information of the contents of the products rather than the user view. The main idea is if the user likes an item, then the user may also like the "other" similar item. We can use various features to compute the similarity while checking identical content.
The system calculates the distances between the products to check their similarity. There are different metrics for computing the similarity. For numeric data, we use Euclidean distance. For textual data, calculate cosine similarity, and for categorical data, we compute Jaccard similarity.
Particular advantages of these systems are there is not much information about users' data. Secondly, it does not suffer a cold start, where a drawback is feature should be available to compute this similarity.
Collaborative Filtering
It is an intelligent recommender system that works on the similarity between different users and items widely used as an e-commerce website and online. It checks the taste of similar users and makes recommendations. The system efficiency improves if we provide a large volume of information about users and items.
There are mainly two types of collaborative filtering. First, user-based filtering identifies clusters of users and utilizes the interactions of one specific user to predict the interactions of other similar users. Second, the system checks the items identical to the user's items. The similarity between different items is computed based on the items and not the predictions' users. Users X and Y purchased items A and BThe shape with similar tastes.
So far, the best recommendation is from amazon. Many e-commerce sites have adapted the Amazon recommendation system. So what does amazon do differently?
Well, to answer that, let us move back to two decades. At that time, the world was too focused on user-based collaborative filtering(analyzing history at the customer level). At the same time, amazon paid attention to item-item-based collaborative filtering(analyzes the history of recent purchases,i.e., item level). The amazon personalization team found researching at the item level provides a much better result than at the customer level. Further trying to improve the algorithm, they wanted to see the relatedness between two customers' purchase histories. After decoding the likelihood, there was a significant increase in recommendation quality.
At present, amazon uses item-item-based collaborative filtering, in which amazon recommendations are made through user purchased items and pairing them with similar items into the recommendation list.
Their recommendation algorithm effectively creates a personalized shopping experience for each customer, which helps Amazon increase the average order value and the amount of revenue generated from each customer.
Currently, Amazon is trying to improve the recommendation quality further by training models in a neural network.
We will be using the amazon dataset for the coding part. Let us first import all the required packages.
import pandas as pd import numpy as np import math import os import json import time import seaborn as sns import matplotlib.pyplot as plt import seaborn as sns from sklearn.metrics.pairwise import cosine_similarity from sklearn.model_selection import train_test_split from sklearn.neighbors import NearestNeighbors import scipy.sparse from scipy.sparse import csr_matrix from scipy.sparse.linalg import svds import warnings; warnings.simplefilter('ignore') %matplotlib inline
We added columns names as the original dataset did not have.
Displaying Data
df.head()
Dropping the timestamp column
df.drop('timestamp',axis=1,inplace=True)
Statistics about ratings column
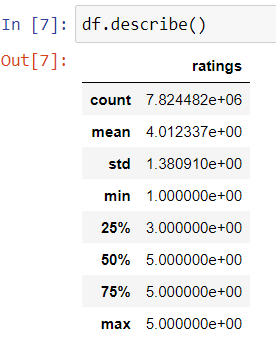
df.describe()
From the above output, the rating is distributed from 1 to 5, with one being the lowest.
We take a subset of the dataset as the data size is too large to make it less dense.
df1=df.iloc[:1000005,0:]
Handling Missing Values
df1.isnull().sum()
As shown above, there are no missing values.
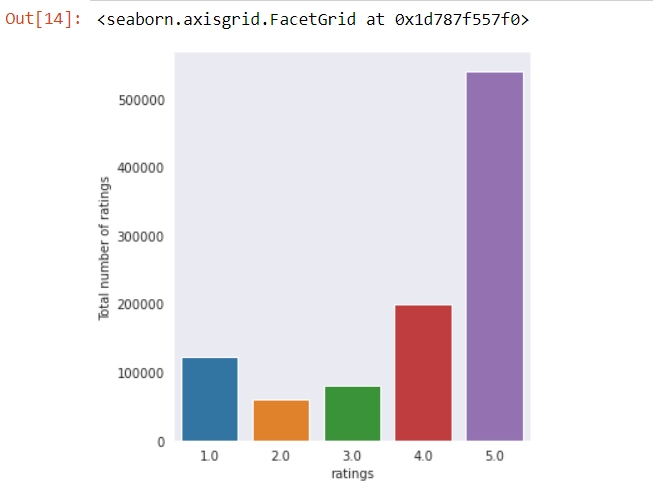
Distribution of Ratings
with sns.axes_style('dark'): g = sns.factorplot("ratings", data=df1, aspect=1.0,kind='count') g.set_ylabels("Total number of ratings")
We can see most of the users have given a rating of 5.
Unique Users and Products
print("\nTotal no of ratings :",df1.shape[0]) print("Total No of Users :", len(np.unique(df1.userId))) print("Total No of products :", len(np.unique(df1.productId)))
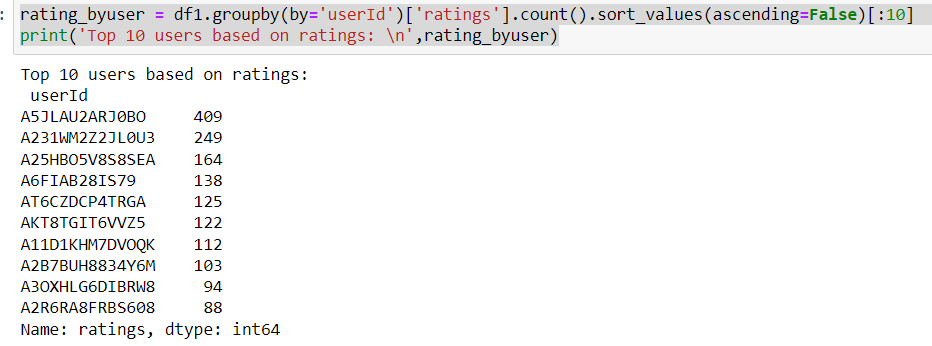
Analyzing the Ratings Given By User
rating_byuser = df1.groupby(by='userId')['ratings'].count().sort_values(ascending=False)[:10] print('Top 10 users based on ratings: \n',rating_byuser)
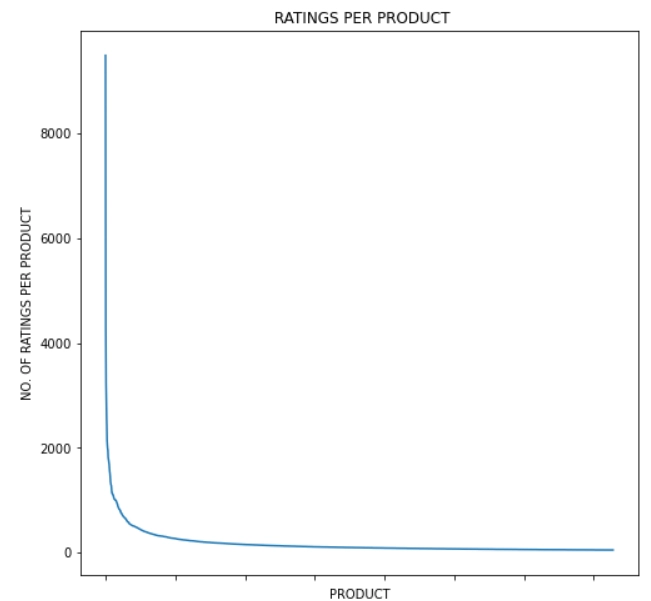
As the dataset is too large, we will only consider users who have rated more than 50 times.
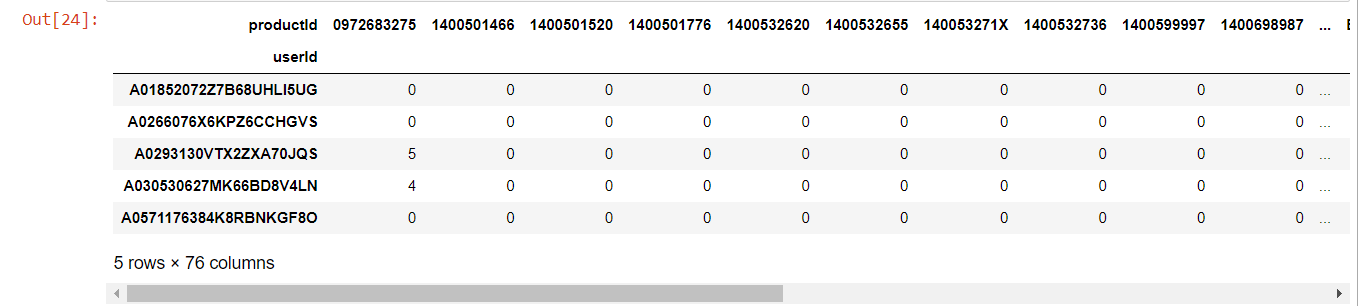
As shown in the table, many cells are filled with zeroes. So it is a sparse matrix.
print('Shape of the pivot table: ', ratings_matrix.shape)
Shape of the pivot table: (9832, 76)
X = ratings_matrix
Now let us create a model.
Collaborative filtering(Item-Item)
Importing the required Packages
from surprise import KNNWithMeans from surprise import Dataset from surprise import accuracy from surprise import Reader import os from surprise.model_selection import train_test_split
A surprise package is a Python library used for recommendation systems. To load data from a pandas data frame, we will use the load_from_df() method. Also, we will need a reader object having a rating_sacle value specified.
reader = Reader(rating_scale=(1, 5)) data = Dataset.load_from_df(new_df,reader)
We can use many algorithms for a recommendation system. Some are baseline only, KNNWithMeans, KNNBaseline, SVD, Co-clustering.
We will be using the KNNWithMeans algorithm for our prediction.
It will return all the movies which have a co-relation greater than 0.5.
That's the end of the implementation. That's the basic model of the Amazon recommendation system. For more reference, do check out the surprise documentation.
Frequently Asked Questions
How does Amazon make use of the recommendation system? Amazon currently uses item-item-based filtering, which produces high-quality recommendations in real-time. This algorithm makes each user's homepage unique, based on their interests and previous purchase history.
How does Amazon personalize using a recommendation system? Amazon uses Amazon personalize, a machine learning service, to share its personalization and recommendation technology with other companies. The primary purpose of this is to overcome problems that create custom recommendations such as delivering high-quality recommendations, preferences, behavior o users, users with no data, etc.
What part of the Amazon sale is due to the recommendation system? According to reports, 35% of the amazons sales are due to its recommendations. So we can see how many recommendations have become a vital part of amazon sales or any other e-commerce site.
Key Takeaways
Let us brief the article; firstly, we saw the recommendation system, moving on, we saw different algorithms for the recommendation system. Furthermore, we saw how Amazon uses this technique to achieve high sales, and lastly, we saw the basic implementation on an amazon dataset.
Thus, I want to conclude this article by stating recommendation system has changed the current scenario by making the user choose the product of their choice and interests.
They make the content more personalized. And the heights amazon achieved just by making proper use of this advanced technology.






























 9+ registered
9+ registered 

