Do you think IIT Guwahati certified course can help you in your career?
Introduction
We use a lot of voice assistants daily like Alexa, Siri, Google Assistant. These voice assistants are interactable, easy to use. We have indirectly depended on voice assistants to set reminders, wake up calls, automatic lights. The algorithm behind these voice assistants is the Recurrent Neural Network(RNN).
In this blog let’s discuss the working of the Recurrent Neural Network(RNN), types of Recurrent Neural Network followed by advantages and disadvantages. Let’s explore different applications of the Recurrent Neural Network(RNN).
A Recurrent Neural Network (RNN) is a type of artificial neural network designed to recognize patterns in sequences of data, such as time series data, text, audio, and video. Unlike traditional neural networks, RNNs have connections that allow information to persist over time. This characteristic makes them especially useful for sequential data where current predictions depend on previous inputs, enabling applications in language translation, speech recognition, and text generation.
Recurrent Neural Network Architecture
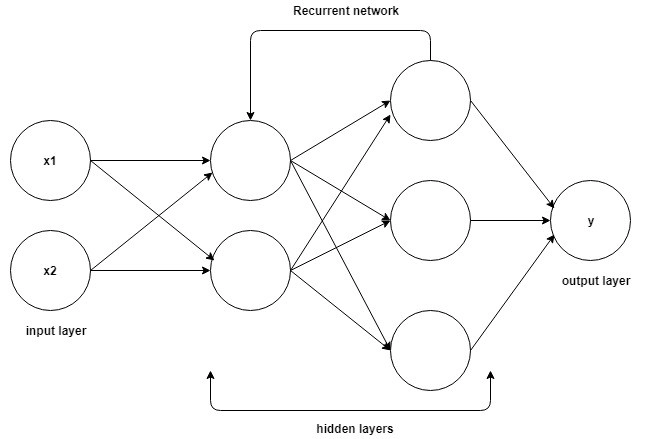
The architecture of an RNN is structured to handle sequence-based data by using feedback loops that allow information to flow across steps in time. Here’s how it works:
1. Recurrent Layers with Feedback Loops:
In a standard neural network, inputs are processed independently, layer by layer. However, in an RNN, each neuron in the hidden layer has a feedback loop that passes information from one time step to the next. This feedback loop allows information from previous inputs (previous time steps) to influence the current output.
This connection makes the RNN “recurrent” because it reuses information, allowing the network to remember previous inputs.
2. Sequence Processing:
When processing sequential data, each input in the sequence is fed into the network one at a time. At each step, the RNN maintains a hidden state that captures information about previous inputs in the sequence.
The hidden state at time step ttt is calculated based on the hidden state at time step t−1t-1t−1 and the current input. This is often expressed as: ht=f(W⋅xt+U⋅ht−1+b) where:
ht is the hidden state at time t.
xt is the input at time t.
W, U, and b are learned parameters.
f is an activation function, often tanh or ReLU.
3. Output Layer:
The output layer takes the final hidden state or a combination of hidden states (depending on the application) to generate the output. For each time step, an output can be generated, or a single output can be produced after the entire sequence is processed.
4. Vanishing Gradient Problem:
A limitation of basic RNNs is the vanishing gradient problem, where gradients diminish during backpropagation, making it hard to learn long-term dependencies. This issue led to the development of more advanced RNN architectures, such as Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU), which use gating mechanisms to help retain information over longer sequences.
Working of Recurrent Neural Network(RNN)
RNNs are a powerful and robust type of neural network and belong to the most promising algorithms in use because it is the only one with internal memory.
Recurrent Neural Networks(RNN) were initially created in the 1980s, but only in recent years have we seen their true potential. An increase in computational power along with the massive amounts of data that we now have to work with and the invention of long short-term memory (LSTM) in the 1990s, has brought RNNs to the foreground.
RNN has vast internal memory that helps to remember important information of inputs received, which allows in predicting the next outputs. So preferred algorithm for sequential data like time series, speech, text, financial data, audio, video, weather, and much more. Recurrent neural networks(RNN) can form a much deeper understanding of a sequence and its context compared to other algorithms.
From the above image let’s understand how an RNN works. First, we need to pass an input layer, that will pass through different hidden layers and process the outputs. So what is different in hidden layers of other neural networks and an RNN, because it has two inputs present and recent past that helps to predict the outputs.
Types of RNN
In general, Recurrent Neural Networks are of four types the name reflects the same as types of functions names. They are:
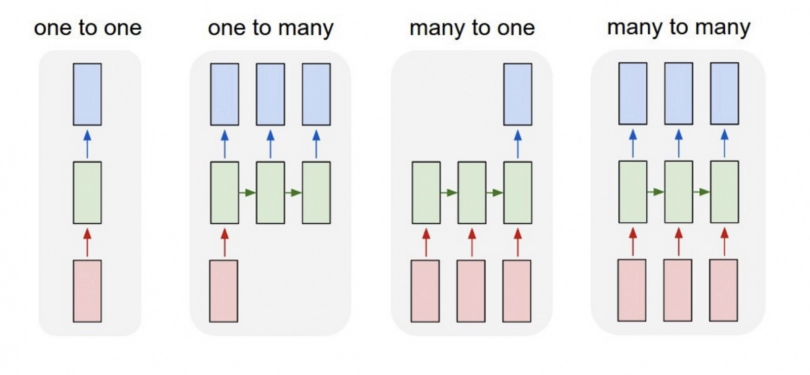
1. One-to-One
Description: One-to-One is the most basic RNN architecture, which is essentially a feed-forward neural network where a single input maps to a single output without needing to handle sequence data.
Example: Image classification tasks often use this setup, where the model takes a single image as input and outputs a single label (e.g., identifying an image as "cat" or "dog").
Use Case: Suitable for problems where there is no sequential dependency, such as straightforward classification tasks.
2. One-to-Many
Description: In a One-to-Many architecture, a single input generates a sequence of outputs. This is useful in scenarios where one input can yield multiple related outputs over time.
Example: Image captioning is a typical example of One-to-Many. The model takes a single image as input and outputs a sequence of words to form a descriptive caption for the image (e.g., "A cat sitting on a sofa").
Use Case: Used when a single data point needs to produce a sequence, such as music generation, where a theme can create multiple notes, or text generation from a prompt.
3. Many-to-One
Description: In Many-to-One architecture, a sequence of inputs leads to a single output. This structure is often used in tasks where the entire sequence must be processed before making a prediction.
Example: Sentiment analysis is a common Many-to-One application. Here, the model takes a sequence of words (e.g., a sentence or review) and outputs a single label, such as "positive" or "negative" sentiment.
Use Case: Ideal for tasks like sentiment classification, text classification, or audio recognition, where the meaning or classification is derived from the full sequence.
4. Many-to-Many
Description: The Many-to-Many architecture processes a sequence of inputs to produce a sequence of outputs. This setup can have different variations, such as matching each input to an output in a parallel fashion or having a time delay between inputs and outputs.
Example: Machine translation is a common example. In this case, the model takes a sequence of words in one language (e.g., English) and outputs a sequence of words in another language (e.g., Spanish).
Use Case: Used for tasks like video classification (labeling each frame), machine translation, and other sequence-to-sequence tasks, where each input in the sequence requires a corresponding output.
We use one to many, many to many (translation) and many to one (classifying a voice). Many to many and many to one are most commonly used for voice assistants and most helpful in recurrent neural networks(RNN).
Advantages of Recurrent Neural Network
Recurrent Neural Networks is one of the most efficient algorithms. So it has many vast advantages:
RNN can process the input of any length.
Even if the input size is larger, the model size does not increase.
An RNN model is modeled to remember each information throughout the time which is very helpful in any time series predictor.
The weights can be shared across the time steps.
RNN can use their internal memory for processing the arbitrary series of inputs which is not the case with feedforward neural networks.
Disadvantages of Recurrent Neural Network
Due to its recurrent nature, the computation is slow.
Training of RNN models can be difficult.
If we are using relu or tanh as activation functions, it becomes very difficult to process sequences that are very long.
Prone to problems such as exploding and gradient vanishing.
Applications of RNN
RNN is one of the most used efficient algorithms for different applications like:
Predicting Problems
Time Series
Machine Translation
Speech Recognition
Language Modelling
Generation of Text
Video tagging
Text Summarization
Call Centre Analysis
Generating Image Descriptions
How does RNN differ from Feedforward Neural Networks?
Recurrent Neural Networks (RNNs) and Feedforward Neural Networks (FNNs) differ primarily in how they handle data and memory, particularly with respect to sequence data. Below are the main differences between RNNs and Feedforward Neural Networks:
1. Data Flow and Structure
Feedforward Neural Networks (FNNs): In FNNs, information flows in one direction—from input through hidden layers to the output layer. There are no cycles or loops in the network, so FNNs don’t maintain any state between different inputs.
Recurrent Neural Networks (RNNs): In RNNs, information flows not only from the input to output but also loops back on itself, allowing each neuron in the hidden layer to maintain a "memory" of previous inputs through feedback connections. This feedback loop creates a form of short-term memory, making RNNs particularly suited for sequential data.
2. Handling Sequential Data
FNNs: FNNs are generally used for tasks where each input is independent of others, such as image classification, where the result depends only on the current input image, not on any previous inputs.
RNNs: RNNs are specifically designed to handle sequential data, such as time series, language, or audio, where the current input’s context depends on prior inputs. RNNs can remember previous information, allowing them to understand relationships over sequences.
3. Memory and State
FNNs: FNNs do not have any inherent memory, as they process inputs independently and do not retain information across inputs. Once an input passes through, it is not "remembered."
RNNs: RNNs have memory, as each hidden layer’s output feeds back into itself. This enables RNNs to retain information across multiple time steps, which is essential for tasks like language processing, where the model needs to retain context across a sequence of words.
4. Applications
FNNs: Used in tasks where each input is independent, such as image recognition, where each image is treated as an independent entity.
RNNs: Used in applications where sequential relationships are important, like language translation, speech recognition, and time series forecasting.
Frequently Asked Questions
What is RNN in deep learning?
An RNN (Recurrent Neural Network) is a neural network designed for sequential data, enabling memory of previous inputs to predict future sequence elements.
Is RNN supervised or unsupervised?
RNNs can be used in both supervised and unsupervised settings, but they’re primarily trained in supervised learning for tasks like language modeling and sequence prediction.
Why is RNN better than CNN for text classification?
RNNs excel in text classification due to their ability to retain and process sequential information, which is essential for understanding context in language.
How many layers are in RNN?
RNNs typically consist of an input layer, one or more recurrent hidden layers, and an output layer. Multiple hidden layers make it a "deep" RNN.
What is RNN used for?
Recurrent Neural Networks(RNN) are a type of Neural Network where the output from the previous step is fed as input to the current step. RNN's are mainly used for, Sequence Classification — Sentiment Classification & Video Classification. Sequence Labelling — Part of speech tagging & Named entity recognition.
What is an RNN example?
The most commonly used RNN is voice recognition, Time series, etc.
What is a simple RNN?
SimpleRNN, a fully-connected RNN where the output from the previous time step is to be fed to next timestep.
What is Illustrator RNN?
A recurrent neural network (RNN) is a class of artificial neural networks where connections between nodes form a directed or undirected graph along a temporal sequence.






























 8+ registered
8+ registered 

