Do you think IIT Guwahati certified course can help you in your career?
Introduction
Finite automata are used to recognize patterns. It takes the string of symbols as input and transforms its state accordingly. When the required symbol is found, then the transition occurs.
Regular Expressions are the expressions that describe the language accepted by Finite Automata. It is the most efficient way to represent any language.
Let’s understand the concept of Regular Expression and Finite Automata in depth.
What is Automata?
Automata is a fascinating concept that involves automating processes or activities using logical methods. It offers several advantages, such as reduced manual work, increased efficiency for repetitive tasks, and applicability across different industries. However, it also has drawbacks, including the risk of flow disruptions, higher implementation and maintenance costs, and potential security vulnerabilities compared to traditional methods. Despite these challenges, automata holds great potential for streamlining operations and improving productivity in various business domains.
Finite Automata
Finite automata are used to recognize patterns. It takes the string of symbols as input and transforms its state accordingly. When the required symbol is found, then the transition occurs.
The automata can either stay in the same state during the transition or move to the next state.
Finite automata consist of two states, one is Accept State, and another is Reject State. When the input string is processed successfully, and the automaton reaches its final state, it will accept.
Formal Definition Of Finite Automata
Finite automata are a collection of 5-tuples M = (Q, ∑, δ, q₀, F),
Where:-
1.) Q = Finite set of states.
2.) ∑ = Finite set of the input symbol
3.) δ: Q × Σ -> Q is the transition function.
4.) q₀ ∈ Q is the start or initial state.
5.) F = Final or Accept state.
Types Of Finite Automata
There are two types of Finite Automata:
1.) Deterministic Finite Automata (DFA):
Deterministic in DFA refers to the uniqueness of the computation. The machine will go to one state only for a particular input character in the DFA. DFA does not accept the null move.
2.) Non-Deterministic Finite Automata (NFA):
NFA transmits any number of states for a particular input. It can accept the null move.
Examples of Finite Automata
Example 1
Design a Finite Automata (FA) with ∑ = {0, 1} accepts those string that starts with 1 and ends with 0.
Ans. The FA will have a start state q₀ from which only the edge with input 1 will go to the next state.
Explanation: In state q1, if we read the symbol 1, we reach the state q1, but if we read 0, we will reach state q2, the final state. In state q2, if we read any of the symbol 0 or 1, we will reach state q2 or q1, respectively. And if the input ends with 0, it will be in the final state.
c.) In DFA, there can be many paths for specific input from the current state to the next state.
d.) NFA can accept the null values.
Ans. The correct answers are:-
a.) Every DFA is NFA, but NFA is not DFA.
b.) DFA is used in Lexical Analysis in Compiler.
c.) NFA can accept the null values.
What is Regular Expression?
Regular Expressions are the expressions that describe the language accepted by Finite Automata. It is the most efficient way to represent any language.
The languages accepted by some regular expressions are referred to asRegular languages.
Regular expressions are used to check and match character combinations in strings. The string searching algorithm uses this pattern to find the operations on a string.
Let Σ be an alphabet that denotes the input set.
The regular expression over Σ can be defined as follows:-
1.) Φ is a regular expression that denotes the empty set.
2.) ε is a regular expression and denotes the set {ε}, called a null string.
3.) For each ‘x’ in Σ ‘x’ is a regular expression and denotes the set {x}.
4.) If ‘a’ and ‘b’ are the regular expressions that denote the language L1 and L2, respectively, then:-
a.) a+b is equal to L1 U L2 union.
b.) ab is equal to the L1L2 concatenation.
c.) a* is equal to L1* closure.
In a regular expression, a* means zero or more occurrences of a. It can generate {ε, a, aa, aaa, aaaa, aaaaa, .....}.
In a regular expression, a+means one or more occurrences of a. It can generate {a, aa, aaa, aaaa, aaaaa, .....}.
Operations On Regular Language
The various operations on the regular language are:
1.) Union
If R and S are two regular languages, their union R U S is also a Regular Language.
R U S = {a | a is in R or a is in S}
2.) Intersection
If R and S are two regular languages, their intersection is also a Regular Language.
L ⋂ M = {ab | a is in R and b is in S}
3.) Kleene closure
If R is a regular language, its Kleene closure R1* will also be a Regular Language.
R* = Zero or more occurrences of language R.
Examples of Regular Expressions
Example 1
Consider the languages L1 = ∅ and L2 = {x}. Which one of the following represents
L1 L2* U L1*.
a.) {ε}
b.) x*
c.) ∅
d.) {ε,x}
Ans. a.) {ε}
Explanation: L1 L2* U L1* Result of L1 L2* is ∅, {∅} indicates an empty language. Concatenation of ∅ with any other language is ∅.
L1* = ∅* which is {ε}. Union of ∅ and {ε} is {ε}.
Example 2
Which one of the following languages over the alphabet {a,b} is described by the regular expression: (a+b)*a(a+b)*a(a+b)*?
a.) Set of all strings containing the substring aa.
b.) Set of all strings containing at least two a’s.
c.) Set of all strings that begin and end with either a or b.
d.) Set of all strings containing at most two a’s
Ans. b.) Set of all strings containing at least two a’s.
Explanation: The regular expression has two a′s surrounded by (a+b)*, which means accepted strings must have at least two a′s. The least possible string is ε a ε a ε = aa The set of strings accepted is = { aa, aaa, baa, aaba, bbbb, aabaa, baabaab,.....}. Thus, we can see from the set of accepted strings that all have at least two a’s, the least possible string.
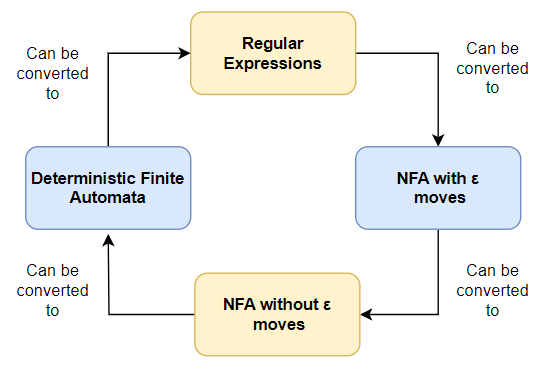
Relationship between Finite Automata and Regular Expression
Finite automata and regular expressions are closely related concepts in the theory of computation.
The relationship between Finite Automata (FA) and Regular Expressions (RE) can be described in several steps:
1. Using epsilon moves, regular expressions can be transformed into Non-deterministic Finite Automata (NFA). Without an input symbol, epsilon moves let you jump from one state to another.
2. The NFA with epsilon moves can be transformed into an equivalent NFA without epsilon moves. This process involves eliminating the epsilon transitions by performing the epsilon closure operation and creating new transitions.
3. The NFA can be further transformed into a Deterministic Finite Automata (DFA) without epsilon stages. For this conversion, a new state must be created for each subset of the NFA states, and transitions are chosen based on the possible inputs for each state.
4. Additionally, a DFA can be converted back into a Regular Expression. This kind of data conversion is possible using methods like state elimination, in which unnecessary states are gradually eliminated until a regular expression representation is produced.
Frequently Asked Questions
1. What do you mean by automata?
Automata refers to the abstract machine which can recognise patterns or sequences of symbols. These are used to study formal languages, pattern recognition and parsing. It reduced manual work and increased efficiency for repetitive tasks.
2. What is an example of an automata?
An example of automata is a finite state machine (FSM). It consists of a finite number of states and transitions between these states based on input symbols. FSM applications include traffic lights, vending machines etc.
3. What is the basic theory of automata?
In short, it is the study of abstract machines and their computational capabilities. It looks at the basic ideas and mathematical frameworks that are used to analyse and evaluate the behaviour of systems that interpret symbols or languages.
4. What is the subject of automata?
Automata is a branch of computer science and mathematics that studies abstract machines, formal languages, and computational models. It involves finite automata, regular expressions, context-free grammar, and the theoretical foundations of computation and language recognition.
Conclusion
In this blog, we have learned about Regular Expression and Finite Automata, their uses, and how they are related. Also, we have solved some examples based on RE and FA.































 9+ registered
9+ registered 

