Do you think IIT Guwahati certified course can help you in your career?
Introduction
As we know, regularization and autoencoders are two different terminologies. First, we will briefly discuss each topic, i.e., autoencoders and regularization, separately, and then we will see different ways to do regularization of autoencoders.
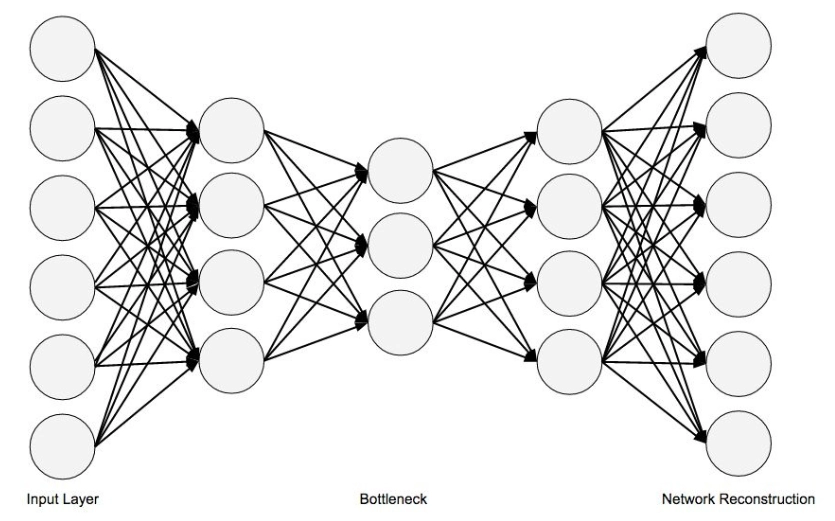
Autoencoders
Autoencoders are a variant of feed-forward neural networks that have an extra bias for calculating the error of reconstructing the original input. After training, autoencoders are then used as a normal feed-forward neural network for activations. This is an unsupervised form of feature extraction because the neural network uses only the original input for learning weights rather than backpropagation, which has labels. Deep networks can use either RBMs or autoencoders as building blocks for larger networks (a single network rarely uses both).
Use of autoencoders
Autoencoders are used to learn compressed representations of datasets. Commonly, we use it in reducing the dimensions of the dataset. The output of the autoencoder is a reformation of the input data in the most efficient form.
Similarities of autoencoders to multilayer perceptron
Autoencoders are identical to multilayer perceptron neural networks because, like multilayer perceptrons, autoencoders have an input layer, some hidden layers, and an output layer. The key difference between a multilayer perceptron network and an autoencoder is that the output layer of an autoencoder has the same number of neurons as that of the input layer.
Regularization
Regularization helps with the effects of out-of-control parameters by using different methods to minimize parameter size over time.
In mathematical notation, we see regularization represented by the coefficient lambda, controlling the trade-off between finding a good fit and keeping the value of certain feature weights low as the exponents on features increase.
Regularization coefficients L1 and L2 help fight overfitting by making certain weights smaller. Smaller-valued weights lead to simpler hypotheses, which are the most generalizable. Unregularized weights with several higher-order polynomials in the feature sets tend to overfit the training set.
As the input training set size grows, the effect of regularization decreases, and the parameters tend to increase in magnitude. This is appropriate because an excess of features relative to training set examples leads to overfitting in the first place. Bigger data is the ultimate regularizer.
Regularized autoencoders
There are other ways to constrain the reconstruction of an autoencoder than to impose a hidden layer of smaller dimensions than the input. The regularized autoencoders use a loss function that helps the model to have other properties besides copying input to the output. We can generally find two types of regularized autoencoder: the denoising autoencoder and the sparse autoencoder.
Denoising autoencoder
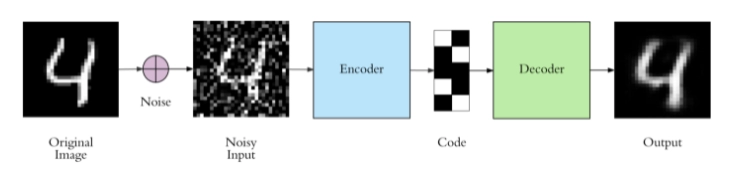
We can modify the autoencoder to learn useful features is by changing the inputs; we can add random noise to the input and recover it to the original form by removing noise from the input data. This prevents the autoencoder from copying the data from input to output because it contains random noise. We ask it to subtract the noise and produce meaningful underlying data. This is called a denoising autoencoder.
In the above diagram, the first row contains original images. We can see in the second row that random noise is added to the original images; this noise is called Gaussian noise. The input of the autoencoder will not get the original images, but autoencoders are trained in such a way that they will remove noise and generate the original images.
The only difference between implementing the denoising autoencoder and the normal autoencoder is a change in input data. The rest of the implementation is the same for both the autoencoders. Below is the difference between training the autoencoder.
Training simple autoencoder:
autoencoder.fit(x_train, x_train)
Training denoising autoencoder:
autoencoder.fit(x_train_noisy, x_train)
Simple as that, everything else is exactly the same. The input to the autoencoder is the noisy image, and the expected target is the original noise-free one.
Sparse autoencoders
Another way of regularizing the autoencoder is by using a sparsity constraint. In this way of regularization, only fraction nodes are allowed to do forward and backward propagation. These nodes have non-zero values and are called active nodes.
To do so, we add a penalty term to the loss function, which helps to activate the fraction of nodes. This forces the autoencoder to represent each input as a combination of a small number of nodes and demands it to discover interesting structures in the data. This method is efficient even if the code size is large because only a small subset of the nodes will be active.
For example, add a regularization term in the loss function. Doing this will make our autoencoder learn the sparse representation of data.
In the above code, we have added L1 regularization to the hidden layer of the encoder, which adds the penalty to the loss function.
Frequently Asked Questions
What is regularization in autoencoder? Regularized autoencoders use a loss function that encourages the model to have other properties besides copying its input to its output.
What is the need for regularization while training a neural? If you've built a neural network before, you know how complex they are. This makes them more prone to overfitting. Regularization is a technique that makes slight modifications to the learning algorithm such that the model generalizes better.
Is autoencoder supervised or unsupervised? An autoencoder is a neural network model that seeks to learn a compressed representation of the input. They are an unsupervised learning method, although technically, they are trained using supervised learning methods, referred to as self-supervised.
Why do we use autoencoder? An autoencoder aims to learn a lower-dimensional representation (encoding) for higher-dimensional data, typically for dimensionality reduction, by training the network to capture the most important parts of the input image.
Key Takeaways
In this article, we have discussed:
Introduction to autoencoders
Definition of regularization
Denoising autoencoders
Sparse autoencoders
Hello readers, here's a perfect course that will guide you to dive deep into Machine learning.






























 9+ registered
9+ registered 

