Relational Data Model is a model that represents data about entities and relationships between different entity sets by a group of tables or relations. It is used in RDBMS and uses the concept of mathematical relation and set theory.
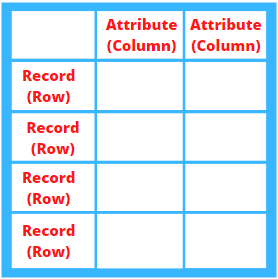
A table or a relation is a two-dimensional object having
RDBMS: RDBMS (Relational Database Management System)is a particular type of DBMS in which information about the entities and relationship between different entities are described by a set of tables or relations.
Examples of RDBMS include MySQL, Oracle etc.
Entity: An Entity is anything that can be stored in a database. It can be a place, person, object or even a concept.
Attributes: Each column in a table corresponds to a specific attribute. They refer to the characteristics of the entities.
Tuples: Tuples or rows in a table contain a linear set of information about the entities.
Degree: The total number of attributes present in a table or relation is the degree.
Cardinality: The total number of tuples present in a table or relation is the cardinality.
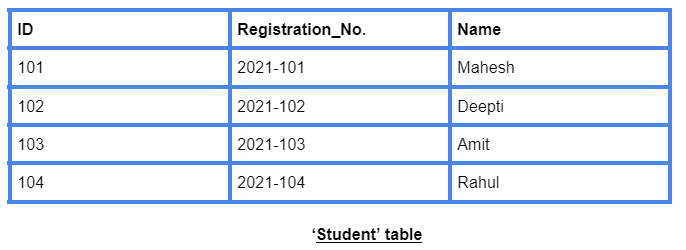
In this table, there are four tuples/rows. There are three attributes - ID, Registration_No. and Name. So the degree is three, and cardinality is four.
Domain: A domain is a set of atomic values that are allowed for an attribute.
For example, the set of possibilities for the domain of Marital Status can be
Single
Married
Divorced
Relation Schema: Relation Schema is used to describe the structure relation. It represents the name of the relation along with all the attributes.
The relation schema is expressed as
R (A1, A2, A3, A4, A5 … An)
Here R refers to the Relation name, and A1, A2, A3, A4, A5 … An represents a list of attributes.
For the above ‘Student’ table, the relation schema is
Student (ID, Registration_No., Name)
Relation Instance/ State: It is a set of tuples at any given time.
All the tables in a database must have a unique name.
Each attribute must have a unique name.
Tuples/ rows in a relation need not have a particular order. They can be arranged in any sequence.
Columns can also be arranged in any sequence. The ordering of columns is insignificant, just like rows.
Each value in a tuple is an atomic value. The table/relation does not contain multivalued attributes or composite attributes.
Duplicate rows are not allowed.
Constraints
Constraints are a set of rules/ limitations on data in the database imposed by the system during data entry and update. Constraints make sure that data integrity and accuracy is maintained.
Constraints in the database are mainly of three types:
Domain Constraints
Key Constraints
Referential Integrity Constraints
Domain Constraints
The domain of an attribute refers to the set of valid values of an attribute. For example, we may define the domain of the attribute ‘Exam_name’ as { Unit Test 1, Unit Test 2, Final Exams}. The domain constraint ensures that only the values specified in the domain should be stored for that attribute.
For example, the domain constraint of ‘Age’ attribute can be defined as,
{x ∣ 18≤x≤60 }
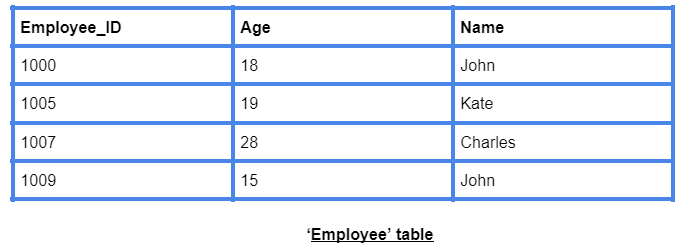
The last tuple in the above ‘Employee’ table, cannot be allowed, as the value does not lie within the domain constraint of Age.
Key Constraints
A key is an attribute or set of attributes that help to uniquely identify a record or a row of data in a table(relation).
In the above ‘Employee’ table, Employee_ID is a key, but Name and Age is not a key.
Not Null: Not Null constraint ensures that the specified column does not contain a NULL value.
Unique: Unique constraint ensures that all values in a column are different.
Primary Key: Primary Key uniquely identifies a row/record in a table.
Foreign Key: Foreign Key ensures referential integrity of the relationship. Foreign key points to the primary key of a foreign table.
Referential Integrity Constraints
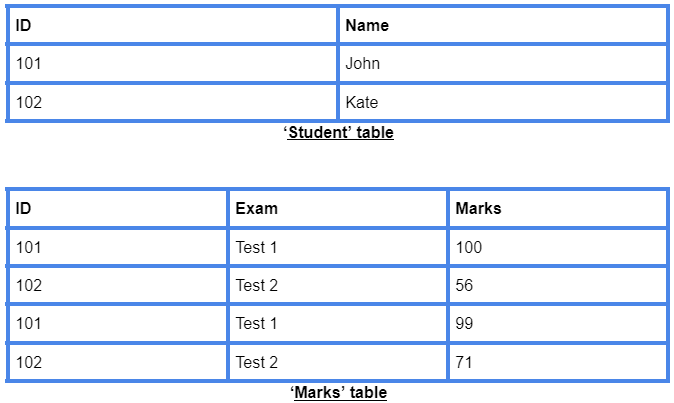
Consider two tables/ relations - R and S. If R and S have a common attribute which is the primary key in R and foreign key in S, then the referential integrity constraint does not allow a tuple in S which has no matching tuple in R.
This constraint is essential for displaying meaningful combinations of data for join operation.
In the above table, ‘ID’ is the primary key in ‘Student’ Table, but foreign key in ‘Marks’ Table.
So the referential integrity constraint will not allow a tuple in the ‘Marks’ table having ID 103, because there is no corresponding tuple in the ‘Student’ table with ID 103.
Anomalies are problems or irregularities that arise on unnormalised data of a relation in a database. There are three types of anomalies,
Insertion Anomaly
Modification/ Updation Anomaly
Deletion Anomaly
All of these three anomalies can be removed with Normalisation. Normalisation is a process by which redundancy or duplication of data is reduced.
Insertion Anomaly
If we cannot insert some known facts in a table/ relation until the data about some other dependent entities are known to us, then it is called Insertion Anomaly
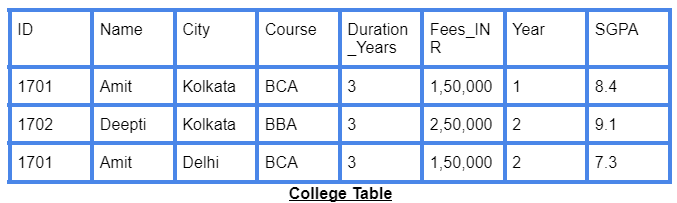
In this ‘College’ table we cannot insert the Duration and Fees of a new course MCA until a student gets admitted in MCA course.
Modification/ Updation Anomaly
If the same fact about an entity becomes different in two different records, then it is called Modification Anomaly.
In the ‘College Table’ , Amit’s City is Kolkata in the 1st year, but in the 2nd year, his City is Delhi. So there are two different values of the City for the same ID, which violates the consistency of data.
Deletion Anomaly
If deletion of data of one entity causes the deletion of another entity, then it is called Deletion Anomaly. For example, we delete the record of student Deepti from the database, then information about the course BBA will also get deleted from the database.
Ans: RDBMS stands for Relational Database Management System. It is a special type of DBMS which is based on the Relational Data Model. In RDBMS, the information about the entities and the relationship between different entities are described by a set of tables or relations.
Some systems that use RDBMS include IBM, Oracle, MySQL etc.
Q2 What is Normalisation?
Ans: Normalisation is a process of continuous modification of data of a relation/ table to remove partial dependencies, transitive dependencies, composite attributes, multi-valued attributes, anomalies etc. The main objective of Normalisation is to reduce redundancy or duplication of data.
Q3 What are the different normal forms?
Ans: The normalisation rules are divided into the following six normal forms,
First Normal Form (1NF)
Second Normal Form (2NF)
Third Normal Form (3NF)
Boyce-Codd Normal Form (BCNF)
Fourth Normal Form (4NF)
Fifth Normal Form (5NF)
Q4 What is SQL?
Ans: SQL stands for Structured Query Language. It is a non-procedural language used in RDBMS. It is used for storing, searching, manipulating and deleting data from databases.
Key Takeaways
In this blog, we discussed Relational Data Models in-depth. We talked about the different properties of Relation and the associated Constraints and Anomalies.
If you are preparing for interviews, don’t forget to study DBMS - as it is one of the most asked topics in interviews. You should definitely check our free DBMS course designed specifically for you!
Don't stop here, Ninja; check out the Top 100 SQL Problemsto get hands-on experience with frequently asked interview questions and land your dream job.





























 9+ registered
9+ registered 

