


























Introduction
This blog will discuss the various approaches to solve the Remove duplicates from an unsorted linked list problem. Before jumping into the problem of removing duplicates from an unsorted linked list, let’s first understand a Linked list.
A Linked list is a kind of data structure in which the elements are connected using pointers, and each node has the address of the pointer of its next node.
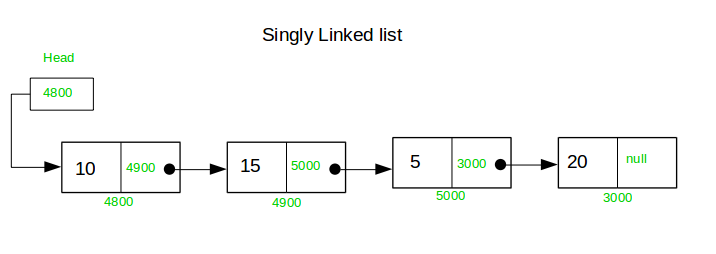
In this Remove duplicates from an unsorted linked list problem, we need to return the head of the linked list after removing all the duplicates from the linked list.
You can refer to this link for more information on the linked list.
For Example:-
List :- 10 -> 15 -> 10 -> 5 -> 145 -> 15 -> 5 -> 11 -> 47 -> 10 -> 15 -> 75
Output :- 10 -> 15 -> 5 -> 145 -> 11 -> 47 -> 75
Let's move toward the approach section for this problem and know how to solve this in the Java language.
Recommended: Before stepping towards the solution try it by yourself on Coding Ninjas Studio.
Brute Force Approach
Brute Force Solution considers checking the complete linked list for the duplicate of each and every element using the nested loop and removing that duplicate element.
Algorithm
Step 1. Create a function ‘getResult()’ that will accept one parameter, i.e., one head pointer of the linked list.
Step 2. Initialize two variables: ‘temp1’ will keep track of the element whose duplicates are being checked, and ‘temp2’ will keep track of the node that is being checked for the duplicate.
Step 3. Assign the value of ‘head’ to ‘temp1’ and assign the null value to ‘temp2’.
Step 4. Make an iteration using the ‘while’ loop, which will terminate if the value of ‘temp1’ or the ‘next’ pointer of ‘temp1’ is equal to null.
Step 5. Store value of ‘temp1’ in ‘temp2’.
Step 6. Make one nested iteration using the ‘while’ loop, which will terminate if the value of the ‘next’ pointer of ‘temp2’ is equal to null.
Step 7. Check if the value of both the ‘temp1’ and ‘temp2’ are equal or not, if they are equal, delete that node and increment the next pointer of ‘temp2’ to its next node’s next pointer and if not equal, then only increment it once.
Step 8. Increment the ‘next’ pointer of the ‘temp1’ node to its next node.
Java Solution
public class Solution
{
class Node
{
// Basic structure of the Node
int data;
Node next;
// Constructor of this class ‘Node’
Node(int x)
{
data = x;
Next = null;
}
}
static Node head;
// Function to insert node in the linked list
static void push(Node headM , int x)
{
Node temp = new Node(x);
temp.next = headM;
headM = temp;
head = headM;
}
Static void getResult(Node head)
{
Node temp1 = null, temp2 = null;
temp1 = head;
/* Pick elements one by one */
while (temp1 != null && temp1.next != null)
{
temp2 = temp1;
/* Comparing each element with the complete linked list
while (temp2.next != null)
{
/* If duplicate of that node is present, then delete it */
if (temp1.data == temp2.next.data)
{
temp2.next = temp2.next.next;
System.gc();
}
else
{
temp2 = temp2.next;
}
}
temp1 = temp1.next;
}
}
static void printList(Node head)
{
int c = 0;
while(head != null)
{
system.out.print(head.data + " ");
head = head.next;
c++;
}
}
public static void main(String[] args)
{
head = null;
push(head, 10);
push(head, 15);
push(head, 10);
push(head, 5);
push(head, 145);
push(head, 15);
push(head, 5);
push(head, 11);
push(head, 47);
push(head, 10);
push(head, 15);
push(head, 75);
System.out.println("Given Linked List :");
printList(head);
getResult(head);
System.out.println("");
System.out.println("Modified Linked List :");
printList(head);
}
}
Output :
Given Linked List:- 10 -> 15 -> 10 -> 5 -> 145 -> 15 -> 5 -> 11 -> 47 -> 10 -> 15 -> 75
Modified Linked List:- 10 -> 15 -> 5 -> 145 -> 11 -> 47 -> 75 Complexity Analysis
Time Complexity: O(N ^ 2)
Incall to ‘getResult()’, As we are using the nested loop to check for a duplicate of each element and then removing it, therefore, the overall time complexity is O(N ^ 2).
Space Complexity: O(1)
As we are using constant space, therefore, the overall space complexity will be O(1).
Recommended Topic, Floyds Algorithm and Rabin Karp Algorithm



 9+ registered
9+ registered 
