



























Introduction
Big Data: Big data refers to the data that is significant, more complex data sets. It is difficult to handle and is impossible to process using traditional ways and methods. Accessing and storing large amounts of information for analytics purposes from various sources is big data. Big data now can be described by the following 10 V's Volume, Velocity, Variety, Veracity, Value, Validity, Variability, Variability, Venue, Vocabulary, and Vagueness.
Big data is classified into three categories as follows:-
- Structured Data: It is an organized form of data with dimensions defined by set parameters.
- Unstructured Data: It is an unorganized form of data and is not defined by any set parameters.
- Semi-Structured Data: This data lies between structured and unstructured data.
Relational Databases: Relational databases are digital databases that store the data and provide access to data related to each other. They are based on a relational model, which is intuitive and a straightforward way of representing data in the form of tables. It was proposed in 1970 by E. F Codd. The relational database management system is used to maintain the relational databases. Many of them can use SQL for maintaining and querying databases.
Understanding the role of relational databases in big data
When a Database is modified, data persistence refers to how it keeps versions of itself. The relational database management system(RDBMS) is the great grandfather of permanent data stores. The computing industry used what are now regarded as primitive data persistence techniques in its early days.
You may recall "flat files" or "network" data repositories being popular before 1980. Although valuable, these processes were difficult to learn and needed system programmers to build custom programs to manage the data. In the 1970s, IBM scientist Edgar Codd devised the relational model, which was adopted by IBM, Oracle, Microsoft, and others. It is still widely used today and has played a significant role in developing big data. Because different types of databases are utilized with extensive data, it's necessary to understand relational databases. The data in a relational model is kept in a table.
The data in a relational model is kept in a table. This database would have a schema, which represents the database's structure. For example, in a relational database, the schema defines the tables, their fields, and the relationships between them. The information is organized into columns, one for each specific property. The information is also kept in the rows. The two tables in figure 1, for example, describe the schema for a primary database. The first table contains product information, while the second contains demographic data. Each has unique characteristics (customer ID, order number, purchase code for a product, and so on). New data may be added to each table, and data can be removed, read, and changed. This is frequently performed using a structured query language in a relational model (SQL).
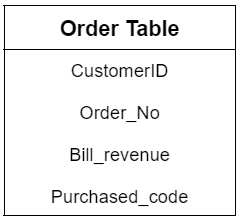
Figure 1
Another feature of the SQL relational architecture is the ability to query tables using a shared key (the relationship). CustomerID is the common key in the tables in figure 2.
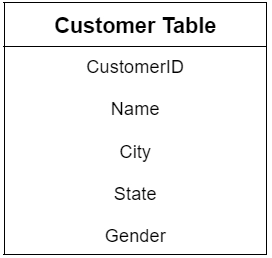
Figure 2
Big data is becoming a critical component of how businesses use high-volume data at the proper speed to address specific data challenges. On the other hand, big data does not exist in a vacuum. Companies must frequently be able to mix the results of big data analysis with data already on hand to be effective. In another way, big data cannot be considered isolated from operational data sources. Several critical operational data services are available.
How big data solutions will inevitably be utilized in combination with data persistence is one of the most significant functions of operational databases (also known as data stores). Persistence ensures that data in a database will not be altered without authorization and will be accessible for as long as the company requires it.
The relational database management system, or RDBMS, is the forefather of permanent data storage. The computing industry employed what are now regarded as rudimentary data persistence techniques in its early days. In essence, they are the systems of record, and they provide the foundation for how businesses retain data on anything from consumer transactions to operational details.
The relational model is still widely used today and plays a crucial role in big data evolution. Tables are used to represent one or more relations in relational databases. The data is saved in the rows of these tables, which are specified by their columns. The primary key is frequently the table's first column. By "normalizing" the data, the database's consistency and most of its value may be obtained. As the term indicates, normalized data has been translated from native format to a shared, agreed-upon format. For example, in one database, "telephone" may be XXX-XXX-XXXX, but in another, it might be XXXXXXXXXXX.
The field will need to be normalized to one of two forms to get a consistent representation of the data. There are five tiers of normalization standards. The database designer is usually in charge of selecting the regular form, which is primarily hidden from end-users. The database schema is a collection of tables, keys, items, and other data. SQL has grown in lockstep with RDBMS technology over the years and is now the most extensively used tool for building, querying, updating, and administering relational databases. The acronym for these tasks is CRUD: Create, retrieve, update, and delete are standard database actions that may be performed directly or through an application programming interface (API).
Read more about Introduction of DBMS here.


 9+ registered
9+ registered 

