Get a skill gap analysis, personalised roadmap, and AI-powered resume optimisation.
Introduction
Hey Ninjas, today we will discuss something very interesting. In statistics, classification is similar to grouping kinds of observations into categories. Similarly, in Machine learning, classification can be considered as predicting the class for a given data point and classifying them accordingly.
In today’s modern time, the data is so huge that for understanding data, knowing data mining is essential. There are many mining techniques, but this article will discuss rule-based classification in data mining.
What is Rule-based Classification in Data Mining?
Rule-based classification in data mining is a technique in which class decisions are taken based on various “if...then… else” rules. Thus, we define it as a classification type governed by a set of IF-THEN rules. We write an IF-THEN rule as:
“IF condition THEN conclusion.”
IF-THEN Rule
To define the IF-THEN rule, we can split it into two parts:
Rule Antecedent: This is the “if condition” part of the rule. This part is present in the LHS(Left Hand Side). The antecedent can have one or more attributes as conditions, with logic AND operator.
Rule Consequent: This is present in the rule's RHS(Right Hand Side). The rule consequent consists of the class prediction.
Example:
R1: IF tutor = codingNinja AND student = yes
THEN happyLearning = true
Assessment of Rule
In rule-based classification in data mining, there are two factors based on which we can access the rules. These are:
Coverage of Rule: The fraction of the records which satisfy the antecedent conditions of a particular rule is called the coverage of that rule. We can calculate this by dividing the number of records satisfying the rule(n1) by the total number of records(n). Coverage(R) = n1/n
Accuracy of a rule: The fraction of the records that satisfy the antecedent conditions and meet the consequent values of a rule is called the accuracy of that rule. We can calculate this by dividing the number of records satisfying the consequent values(n2) by the number of records satisfying the rule(n1). Accuracy(R) = n2/n1
Generally, we convert them into percentages by multiplying them by 100. We do so to make it easy for the layman to understand these terms and their values.
Properties of Rule-Based Classifiers
There are two significant properties of rule-based classification in data mining. They are:
Rules may not be mutually exclusive
Rules may not be exhaustive
Rules may not be mutually exclusive in nature
Many different rules are generated for the dataset, so it is possible and likely that many of them satisfy the same data record. This condition makes the rules not mutually exclusive.
Since the rules are not mutually exclusive, we cannot decide on classes that cover different parts of data on different rules. But this was our main objective. So, to solve this problem, we have two ways:
The first way is using an ordered set of rules. By ordering the rules, we set priority orders. Thus, this ordered rule set is called a decision list. So the class with the highest priority rule is taken as the final class.
The second solution can be assigning votes for each class depending on their weights. So, in this, the set of rules remains unordered.
Rules may not be exhaustive in nature
It is not a guarantee that the rule will cover all the data entries. Any of the rules may leave some data entries. This case, on its occurrence, will make the rules non-exhaustive. So, we have to solve this problem too. So, to solve this problem, we can make use of a default class. Using a default class, we can assign all the data entries not covered by any rules to the default class. Thus using the default class will solve the problem of non-exhaustivity.
Implementation of Rule-Based Classifier
We have two different kinds of methods for implementing rule-based classification in data mining. They are:
Direct Method
Indirect Method
Direct Method
The direct method for rule-based classification in data mining contains algorithms that extract rules directly from the dataset.
The prominent among these are:
1R Algorithm
Sequentia Covering Algorithm
1R Algorithm
The 1R Algorithm is also known as the Learn One Rule Algorithm. It is based on a simple classification rule. Thus it is one of the simplest algorithms. In this algorithm, we make rules to test each attribute. If the attribute has a range of values, we make rules by counting how often each class value appears. We do this to know its frequency and find the class with the maximum frequency. Then we assign that class to the attribute value pair. After this, we calculate the error rate for each attribute and select the one with the lowest error rate.
There can be some problems with the 1R method; there is a high chance of overfitting and noise sensitivity. So, to overcome these problems, we use the Sequential Covering Algorithm.
Sequential Covering Algorithm
The sequential covering algorithm is the most widely used algorithm in rule-based classification in data mining. This algorithm defines rules to cover the maximum data records of one class and no data records of other classes.
In these algorithms, rules are grown sequentially, one at a time. After a rule is grown, all data records covered by that rule are eliminated, and then this process keeps on repeating for the rest. This process will stop when we reach the stopping criteria, i.e., if the accuracy of the rule is below the required level, then we reject that rule and stop there.
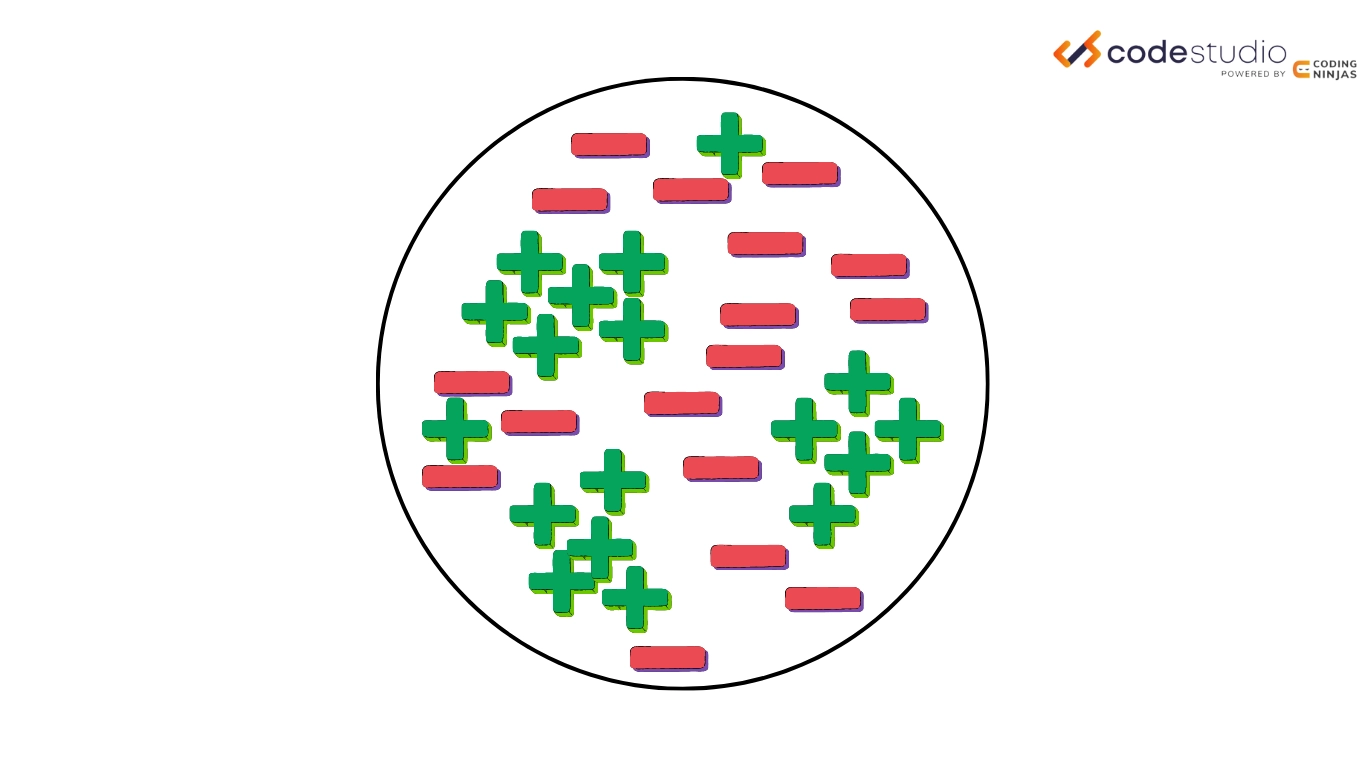
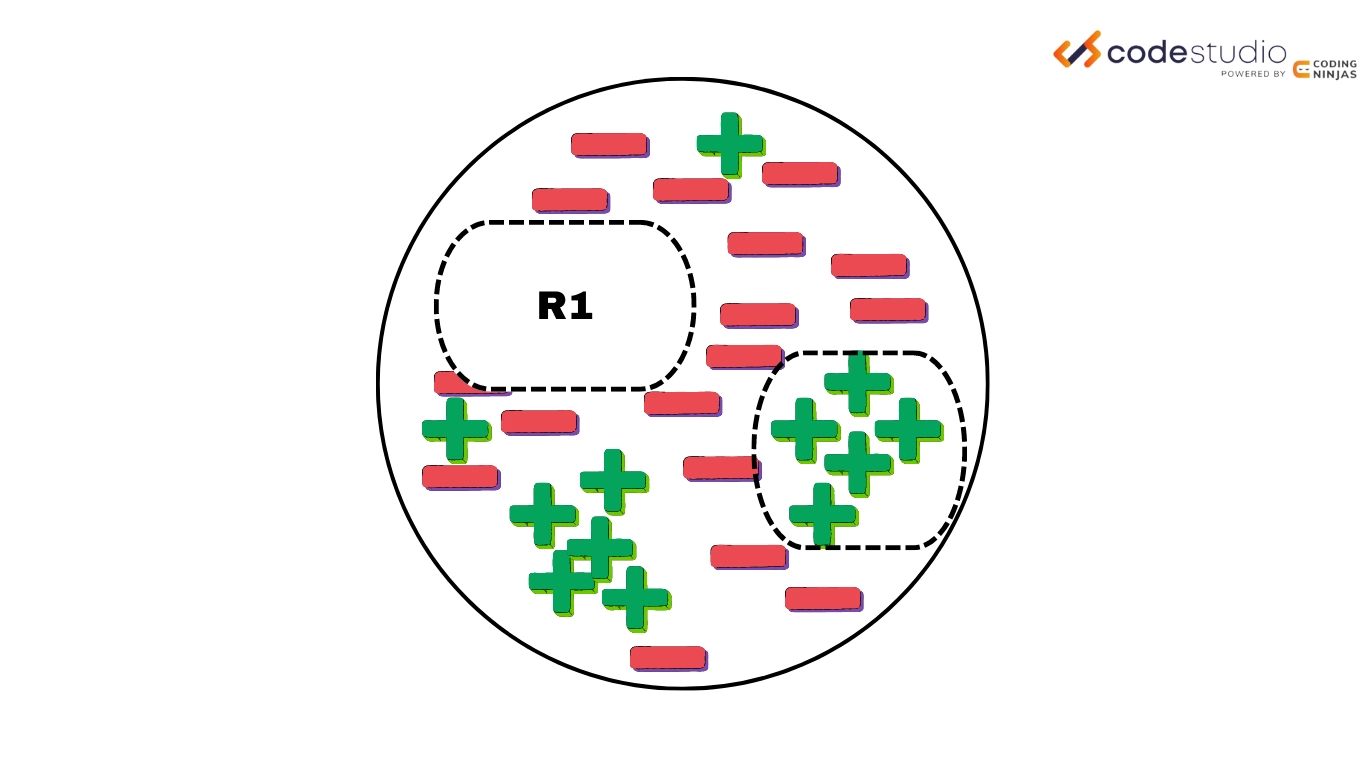
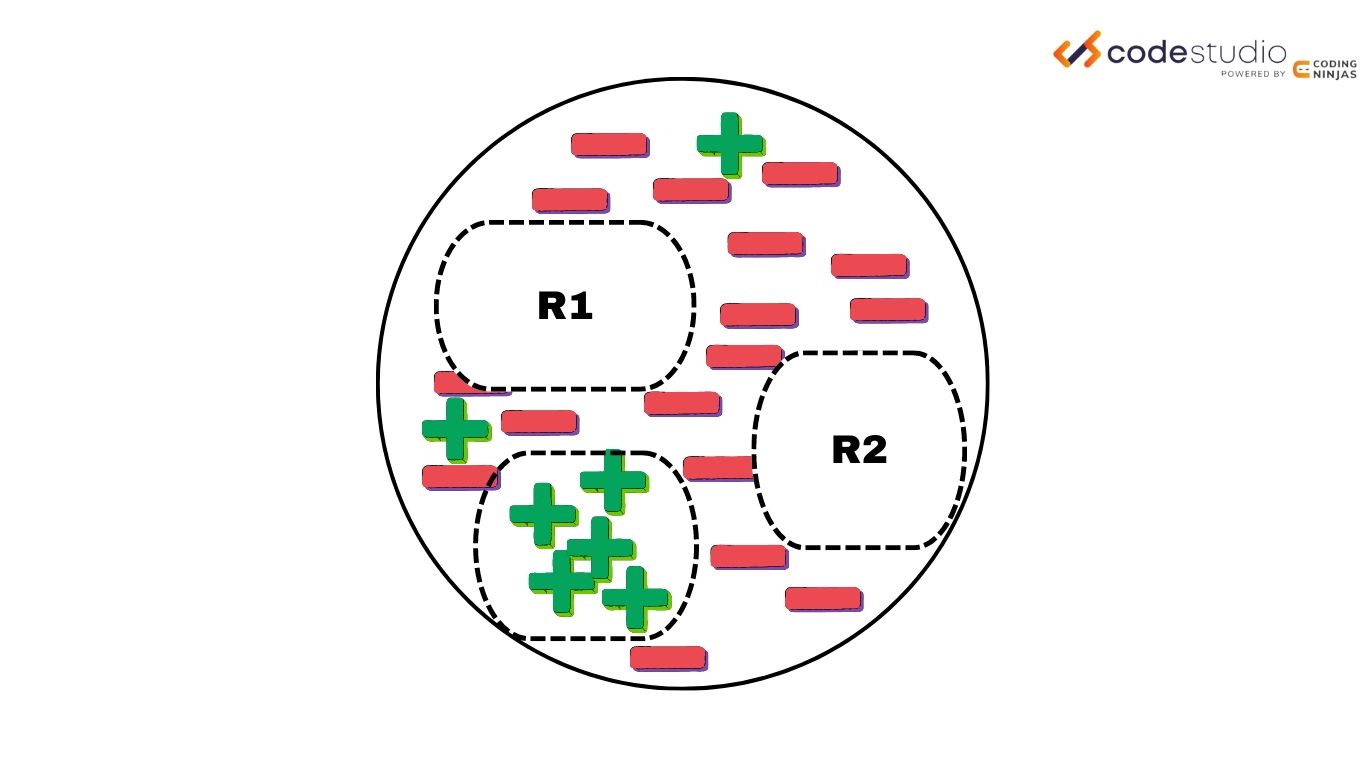
So we can understand the flow of the sequential covering algorithm through the following steps.
This is the original state
Rule Gowing(Rule 1)
Instance Elimination(Removing Rule1 and growing Rule2)
Continuing this process until meeting the stopping criteria.
Indirect Method
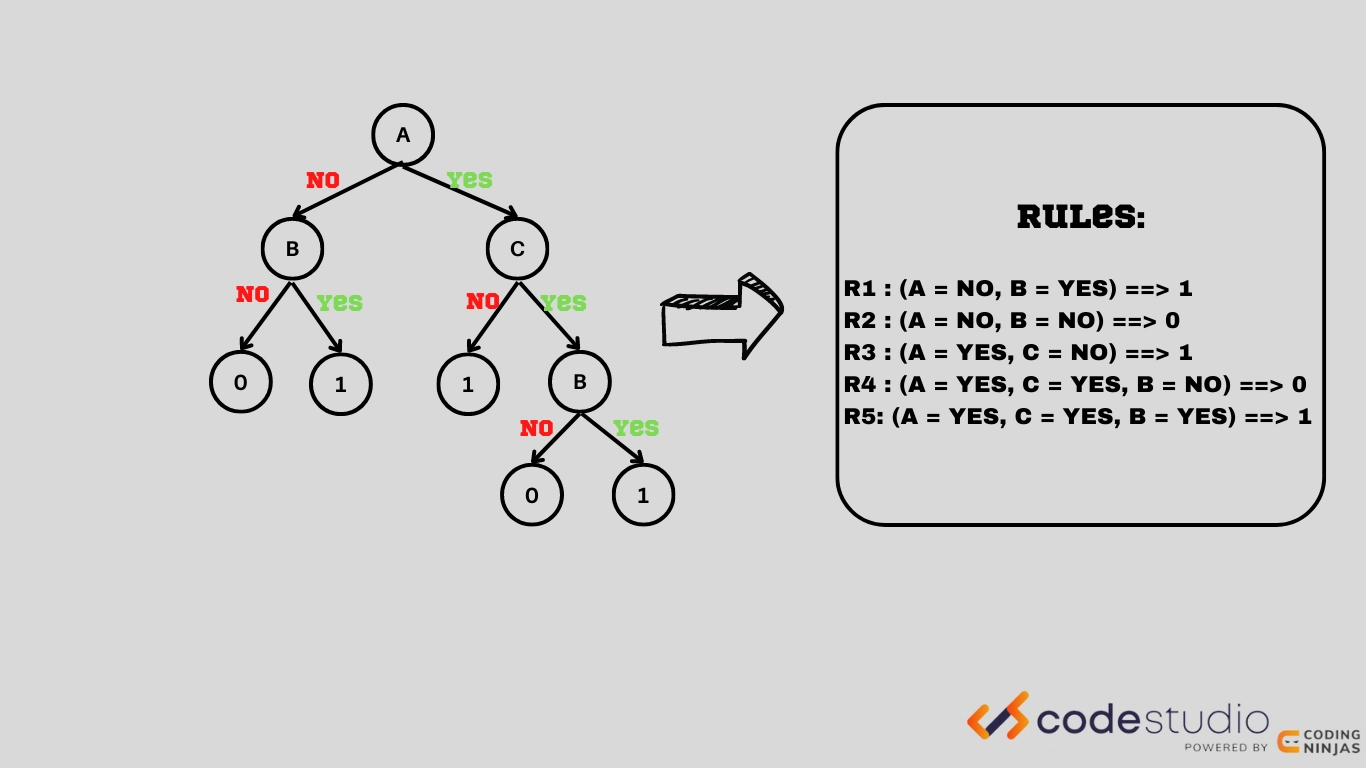
In the indirect method of rule-based classification in data mining, we extract rules from different other classification models. Some prominent classifications from which we extract the rules are decision trees and neural networks.
For example:
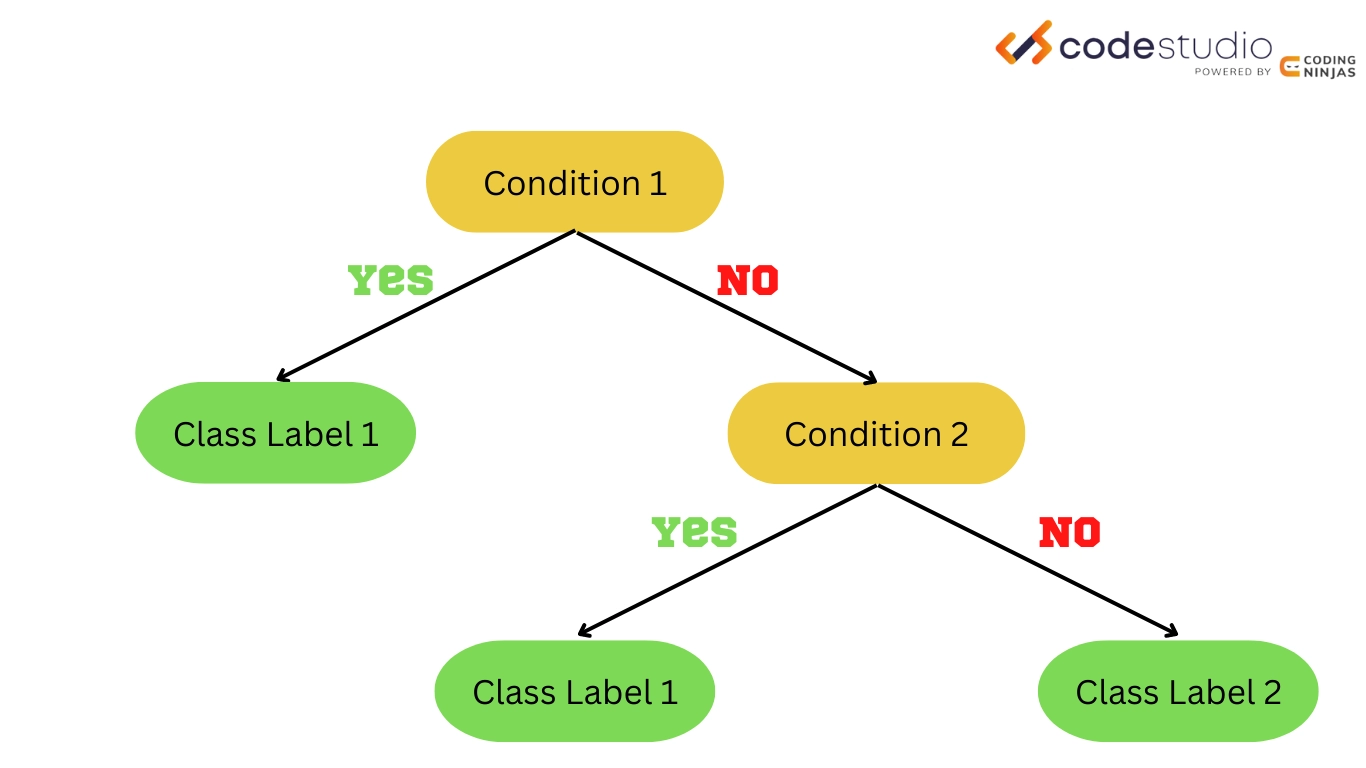
Converting the decision tree to the rule set.
Advantages of Rule-Based Classification
Let us see an example of rule-based classification in data mining to understand its advantages.
The significant advantages of rule-based classification in data mining, which we see through the example are:
The rule-based classification is easy to generate.
It is highly expressive in nature and very easy to understand.
It assists in the classification of new records in significantly less time and very quickly.
It helps us to handle redundant values during classification properly.
The performance of the rule-based classification is comparable to that of a decision tree.
Frequently Asked Questions
What is rule-based classification in data mining?
Rule-based classification in data mining is a technique in which the classification decisions are taken based on various IF-THEN rules.
What are the two properties of rule-based classification in data mining?
The two properties of rule-based classification in data mining are the rules may not be mutually exclusive, and the rules may not be exhaustive.
What is an example of a rule-based algorithm?
An example of a rule-based algorithm is a decision tree. For example, a decision tree for predicting whether a person will buy a product might start by splitting the data based on age. If the person is over a certain age, the tree might next split based on income, and so on. The final leaf nodes would be the predicted decision, such as "buy" or "don't buy".
How rule-based classifiers are used for classification?
Rule-based classifiers are used for classification by defining a set of rules that can be used to assign class labels to new instances based on their features. These rules can be created using expert knowledge of the domain, or they can be learned automatically from a set of labeled training data.
Conclusion
In this article, we learned about rule-based classification in data mining. First, we read about the definition of rule-based classification, then we read about its assessment techniques. After this, we learned the different algorithms and methods we use for its implementation. Then we read its benefits and the reasons for which we use it.
We hope this blog helps you and increases your knowledge about rule-based classification in data mining. Do upvote our blogs if you find them helpful and engaging! To learn more about data mining, refer to Data Mining. To know more about the techniques used, go to Types of Data Mining Techniques.































 6+ registered
6+ registered 

